## 视频
<video src="https://dev-media.amazoncloud.cn/30-LibaiGenerate/31-LiBaiRebrandingVideo/AIM313-S-How_to_accelerate_Apache_Spark_pipelines_on_Amazon_EMR_with_RAPIDS__sponsored_by_NVIDIA___NVIDIA_-LBrebrandingWCaptionCN.mp4" class="bytemdVideo" controls="controls"></video>
## 导读
RAPIDS加速器可以为[Amazon EMR](https://aws.amazon.com/cn/emr/?trk=cndc-detail)上的Apache Spark数据处理流水线提供透明的加速。在这个闪电式演讲中,您将学习如何在Amazon EC2和[Amazon EKS](https://aws.amazon.com/cn/eks/?trk=cndc-detail)上使用NVIDIA GPU来在[Amazon EMR](https://aws.amazon.com/cn/emr/?trk=cndc-detail)上部署RAPIDS加速器。探索哪些查询特别适合GPU,并了解如何预测Spark工作负载在[Amazon EMR](https://aws.amazon.com/cn/emr/?trk=cndc-detail)上的成本节省。RAPIDS是NVIDIA AI企业套件的一部分,这是一个端到端的、安全的、云原生的AI软件套件,可以在Amazon Marketplace上获得,让组织能够解决新的挑战的同时提高运营效率。这个演示由NVIDIA提供,NVIDIA是亚马逊云科技的合作伙伴。
## 演讲精华
<font color = "grey">以下是小编为您整理的本次演讲的精华,共700字,阅读时间大约是4分钟。如果您想进一步了解演讲内容或者观看演讲全文,请观看演讲完整视频或者下面的演讲原文。</font>
演讲者首先探讨了利用NVIDIA的RAPIDS加速器插件来加速[Amazon EMR](https://aws.amazon.com/cn/emr/?trk=cndc-detail)上的Apache Spark批量处理工作负载的话题。他强调,企业面临各种关键工作负载,如数据准备、报告、分析和操作,这些负载都需要以加速的方式处理大量数据集。
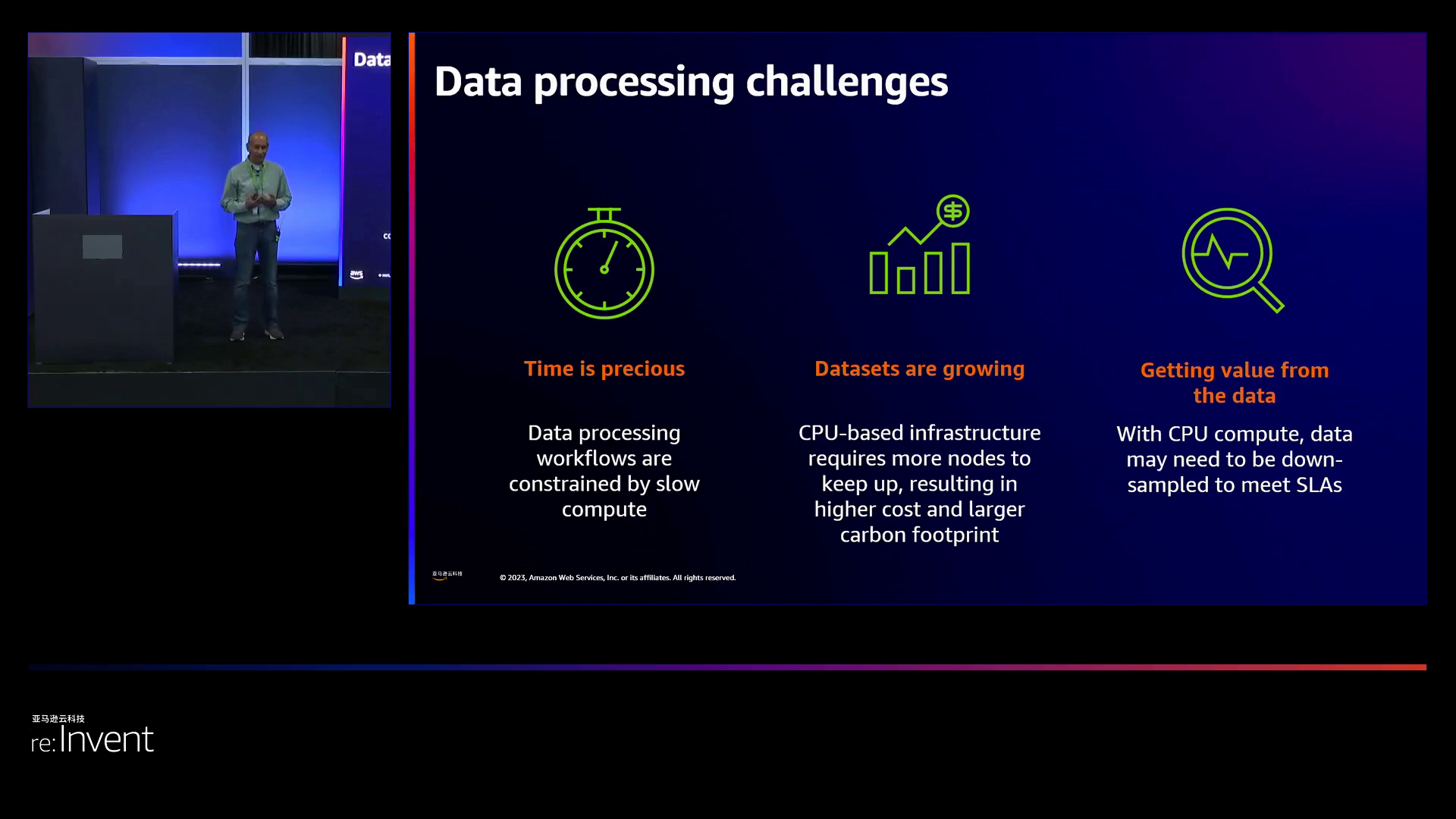
据演讲者介绍,IDC报告显示,到2026年,数据量预计将达到221泽字节,其中80%为非结构化数据。为了从这些海量数据中提取价值,必须对数据进行大规模的转换和准备。然而,扩展计算基础设施的成本很高,而降低数据采样率会导致保真度下降。
为了解决这个问题,演讲者提出了使用GPU加速Spark的方法。Spark 3支持资源感知调度、插件和适用于GPU的列式处理。RAPIDS插件能够自动在GPU上加速Spark DataFrame操作,而无需修改代码。这是通过使用JNI调用来访问RAPIDS库以实现GPU数据处理,从而用GPU执行计划替换CPU执行计划实现的。
基准测试表明,在高基数连接、聚合、窗口处理和复杂处理的数据集上,性能得到了显著提升。一个资格验证工具会分析Spark日志,以推荐建议在特定工作负载中加速GPU的速度提升。
实际应用案例包括零售商优化内容重写、电信公司加速ETL和ML过程以及广告技术公司加快固定空间内的ETL处理。采用这种方法的好处包括降低成本、缩短任务完成时间以及在不增加计算需求的情况下扩大数据处理能力。
NVIDIA AI Enterprise为RAPIDS Spark部署提供了支持、安全补丁、关键错误修复和SLA。资源包括文档、GitHub上的开源社区和资格验证工具。
总的来说,NVIDIA的RAPIDS Spark插件可以在不增加额外成本的前提下,无缝地在GPU上加速Spark工作负载,使企业能够更有效地从不断增长的数据库中提取价值。此外,资格验证工具可以帮助确定哪些任务可以从加速GPU中受益,而NVIDIA AI Enterprise则为企业在生产环境中使用该技术提供了支持。
演讲者强调,企业在处理大量数据方面面临关键挑战,包括数据准备、报告、分析和操作等关键任务,都需要尽快处理。据IDC报告预测,到2026年,数据量将指数增长至221泽字节,其中大部分为未结构化数据。为了从中提取价值,演讲者指出需要在规模上对数据进行转换和准备。尽管扩大计算基础设施成本高昂,但演讲者表示,降低数据采样率可能会导致数据真实性的损失。
作为提高处理速度的替代方案,演讲者建议利用GPU加速Apache Spark工作负载。Spark 3支持资源感知调度、插件和适用于GPU的批处理等技术。NVIDIA的RAPIDS插件可以在不修改代码的情况下自动加速Spark DataFrame操作。这通过调用优化GPU数据处理的JNI接口到RAPIDS库实现。
演讲者引用的一些基准测试显示,在处理高基数连接、聚合、窗口化和复杂处理时,利用GPU可以显著提高数据处理速度。一个资格鉴定工具可以分析Spark日志,以推荐可能受益于GPU加速的具体作业并估计加速效果。
演讲者提供了一些实际客户使用案例,包括一家大型零售商改进其电子商务网站内容重写,一家电信公司加速ETL和[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)管道,以及一家广告技术公司在不扩大计算资源的情况下加速ETL工作流程。主要好处包括降低成本、缩短作业执行时间以及在无需扩展计算资源的情况下处理更多数据。
为了支持在生产中使用RAPIDS Spark,演讲者提到NVIDIA AI Enterprise提供支持、安全补丁、关键错误修复和服务协议等服务。可用资源包括文档、GitHub上的开源社区和资格鉴定工具。
总的来说,NVIDIA推出的RAPIDS Spark插件使得在GPU上对Spark工作负载进行透明加速成为可能,这使得企业在控制成本的前提下能够从海量数据中提取更多的价值。通过资格鉴定工具,我们可以了解哪些作业能够从中受益;同时,NVIDIA AI Enterprise提供了生产支持服务。
**下面是一些演讲现场的精彩瞬间:**
全球数据量的增长呈指数级趋势,预计到2026年将增至221泽字节,据国际数据公司(IDC)统计。
Apache Spark 3具有资源感知调度、自定义插件以及对GPU加速的列式数据处理的支持。

Spark能够将SQL查询优化为可利用GPU加速以提高处理速度的优化物理计划。

亚马逊云科技已与一家大型零售商合作部署了Rapids Spark,以便在不增加成本的前提下定期更新电子商务网站内容。

英伟达为客户提供专业服务并承诺服务等级协议(SLA),以支持各组织部署用于加速数据分析的Rapids Spark。

## 总结
NVIDIA在re:Invent(Amazon Summit)的亚马逊云科技(Amazon Web Services)展览中,着重展示了如何利用RAPIDS加速器提高Apache Spark在[Amazon EMR](https://aws.amazon.com/cn/emr/?trk=cndc-detail)上的处理速度。随着数据量的持续快速增长,企业迫切需要能够快速且经济高效地处理这些数据。Spark的GPU加速器插件是一款开源产品,使得Spark工作负载能够利用GPU进行加速处理,而无需修改代码。通过将Spark物理执行计划中的基于CPU的操作替换为来自RAPIDS库的基于GPU的等效操作来实现这一目标。基准测试结果显示,GPU在处理具有复杂聚合、连接和窗口操作的高基数数据方面表现优异。
鉴定工具可以帮助分析现有的Spark作业,推荐哪些作业适合进行GPU加速,并提供预计的速度提升和成本节省。零售商、电信公司和广告技术公司等客户已在EMR上使用Spark和RAPIDS来降低成本并加速现有集群范围内的作业,尽管数据量仍在持续增长。
英伟达的企业AI计划提供支持,包括调整、分析和优化用于部署Spark的RAPIDS的补丁。丰富的学习资源如文档和开源社区可供用户了解更多并开始学习使用。借助RAPIDS和GPU,Spark工作负载能够在不扩大计算资源的情况下应对数据增长的挑战。
## 演讲原文
## 想了解更多精彩完整内容吗?立即访问re:Invent 官网中文网站!
[2023亚马逊云科技re:Invent全球大会 - 官方网站](https://webinar.amazoncloud.cn/reInvent2023/?s=8739&smid=19458 "2023亚马逊云科技re:Invent全球大会 - 官方网站")
[点击此处](https://aws.amazon.com/cn/new/?trk=6dd7cc20-6afa-4abf-9359-2d6976ff9600&trk=cndc-detail "点击此处"),一键获取亚马逊云科技全球最新产品/服务资讯!
[点击此处](https://www.amazonaws.cn/new/?trk=2ab098aa-0793-48b1-85e6-a9d261bd8cd4&trk=cndc-detail "点击此处"),一键获取亚马逊云科技中国区最新产品/服务资讯!
## 即刻注册亚马逊云科技账户,开启云端之旅!
[【免费】亚马逊云科技“100 余种核心云服务产品免费试用”](https://aws.amazon.com/cn/campaigns/freecenter/?trk=f079813d-3a13-4a50-b67b-e31d930f36a4&sc_channel=el&trk=cndc-detail "【免费】亚马逊云科技“100 余种核心云服务产品免费试用“")
[【免费】亚马逊云科技中国区“40 余种核心云服务产品免费试用”](https://www.amazonaws.cn/campaign/CloudService/?trk=2cdb6245-f491-42bc-b931-c1693fe92be1&sc_channel=el&trk=cndc-detail "【免费】亚马逊云科技中国区“40 余种核心云服务产品免费试用“")
如何在Amazon EMR上使用RAPIDS加速Apache Spark流水线(由NVIDIA赞助)
云计算
re:Invent

 0
0 0
0亚马逊云科技解决方案 基于行业客户应用场景及技术领域的解决方案
联系亚马逊云科技专家
亚马逊云科技解决方案
基于行业客户应用场景及技术领域的解决方案
联系专家

0
目录

 分享
分享 点赞
点赞 收藏
收藏 目录
目录立即注册,开启您的免费套餐
立即关注

亚马逊云开发者
公众号

User Group
公众号

亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
关于我们 
更多资源
开发者工具
更多支持
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
