## 视频
<video src="https://dev-media.amazoncloud.cn/30-LibaiGenerate/31-LiBaiRebrandingVideo/STG358-Optimizing_performance_for_machine_learning_training_on_Amazon_S3-LBrebrandingWCaptionCN.mp4" class="bytemdVideo" controls="controls"></video>
## 导读
[Amazon S3](https://aws.amazon.com/cn/s3/?trk=cndc-detail)提供了业界领先的可扩展性、数据可用性、安全性和性能。您可以使用[Amazon S3](https://aws.amazon.com/cn/s3/?trk=cndc-detail)进行[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)用例,以存储工件,包括训练数据和检查点。在本课程中,了解如何在读取[Amazon S3](https://aws.amazon.com/cn/s3/?trk=cndc-detail)中的训练数据以及读取和写入模型检查点时,在保持架构简单的同时实现最高性能。具体来说,本课程探讨了从Kubernetes应用程序访问[Amazon S3](https://aws.amazon.com/cn/s3/?trk=cndc-detail)的最佳实践和工具,以及访问流行的开源框架(如PyTorch)的最佳实践和工具。
## 演讲精华
<font color = "grey">以下是小编为您整理的本次演讲的精华,共1500字,阅读时间大约是8分钟。如果您想进一步了解演讲内容或者观看演讲全文,请观看演讲完整视频或者下面的演讲原文。</font>
大卫·库马尔,作为亚马逊S3团队的产品经理,在一场关于如何优化[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)训练性能的会议上欢迎与会者。他与同事詹姆斯·萨雷尔温尼和亚历山大·阿扎诺夫一起概述了实现S3中ML工作负载的高吞吐量和低延迟数据访问的新功能和最佳实践。
大卫首先向观众调查了他们使用S3以及针对[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)优化存储性能的熟悉程度。正如所料,大家都使用S3,但只有一部分人专门从事过针对ML的存储优化工作。大卫表示,随着亚马逊云科技的近期推出,观众们不再需要这样做——新功能将自动优化用于ML使用情况的存储访问。
大卫进一步详细说明,[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)始于数据,而由于其无限的可扩展性、高弹性吞吐量性能和高持久性,S3是存储数据的最佳场所。各行各业的客户都在S3中存储数PB的数据,以用于如数据湖、媒体、IoT、基因组学、医疗保健等使用案例。当数据已经驻留在S3中时,将其用于[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)也是合乎逻辑的。
接下来,大卫解释了为什么S3非常适合ML工作负载的几个关键原因:
首先,[Amazon S3](https://aws.amazon.com/cn/s3/?trk=cndc-detail)根据数据访问模式、成本要求和数据恢复需求,提供了多种存储类别选择。例如,智能分层是用于ML和数据湖的最受欢迎的存储类之一,因为它会自动将不经常访问的对象移动到较低成本的层,从而在不影响性能或减少运营开销的情况下节省成本。生命周期策略可以通过自动将对象转换为其他存储类来进一步优化成本。
其次,S3提供了非常高的总体吞吐量,这对于ML训练至关重要。最近推出的客户端侧优化,如S3挂载点、亚马逊云科技通用运行时集成在SageMaker Python SDK中和PyTorch的S3连接器,提供了S3和ML计算作业之间的高速数据传输速率。客户端在后台处理优化,如请求并行化、重试和超时,以便用户无需编写任何代码即可实现。
最终,新推出的S3 Express One Zone存储类别专为低延迟访问而设计,适用于高性能工作负载,如大量随机数据访问的训练任务。客户可以选择可用区来进一步优化性能,并通过选择计算和存储位置来实现更好的性能。
戴夫提供了一个客户案例研究,以展示S3在[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)工作负载中的可扩展性。新加坡科技与设计大学(TII)使用S3和SageMaker构建了具有180亿参数的Falcon自然语言模型,该模型在3.5万亿令牌的数据集上使用数百个ML实例进行训练。他们通过使用S3的弹性和与SageMayer Python SDK的集成实现了高吞吐量。尽管S3可以扩展到最大模型,但性能优化对任何大小的ML工作负载都具有重要意义。
戴夫然后将演讲交给了同事亚历山大·阿列克山德罗夫,以更详细地介绍如何在S3上优化整个[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)生命周期。
亚历山大重申,无论使用何种工具和框架,优化ML的数据I/O性能都至关重要。在训练过程中,如果数据访问不佳,GPU资源可能会闲置等待数据,从而降低计算资源的利用率。这将延长训练时间并减慢开发工作流程。
他解释说,一个典型的ML项目通常遵循相同的工作流程——数据探索,模型构建/测试,分布式训练至收敛,部署。在这个工作流程中,S3上的数据格式和结构将持续演变。例如,一个自然语言模型的预训练数据可能从网络文本开始,然后清理和过滤成更结构化的Parquet格式的数据集进行训练。训练快照可能产生数百兆字节的模型权重,也存储在S3上。
亚历山大强调,在整个工作流程中,将数据存储在S3中的最佳格式、位置和存储类以获得最佳性能非常重要。
关键考虑因素包括:
- 总数据集大小和文件数量
- 小文件与大文件的组成
- 需要预先下载还是按需流式传输
- 访问模式 - 顺序访问还是随机访问
为了说明性能影响,亚历山大提供了一个例子。对于计算机视觉工作负载,若数据被序列化为大型150MB的对象,并由单个客户端顺序读取,那么吞吐量可以达到约140 MB/秒。然而,如果以随机方式读取原始图像文件,由于多个API调用的开销,吞吐量将急剧下降到约1 MB/秒。
尽管S3可以通过并行请求提供更高的总体吞吐量,但建议使用顺序访问以减少CPU开销。然而,有些工作负载本质上需要随机访问。为了解决这个问题,新推出的S3 Express One Zone存储类为高性能工作负载提供了比S3标准低10倍的延迟。
亚历山大随后讨论了如何使用SageMaker来自动管理从S3中加载数据的过程。SageMaker训练作业包括计算实例的自动调配、存储卷的挂载、容器镜像的拉取、脚本的注入以及在完成后的资源销毁。
SageMaker支持两种访问S3中的数据的方式:
1. 文件模式:在训练开始之前将数据预先复制到本地存储中,然后进行训练。这种方式提供了低延迟的随机访问,但启动延迟与数据集大小成比例。
2. 管道模式:根据训练脚本的需求,实时流式传输数据。这种方式的启动时间接近即时,对数据大小没有限制,但吞吐量取决于实例存储性能。
现在,管道模式还支持除了其他存储类之外的S3 Express One Zone存储类,从而允许在没有代码更改的情况下实现高吞吐量的随机数据访问。
亚历山大强调,无论使用哪种[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)工具和框架,了解数据如何在S3和计算之间流动是很重要的。接下来,他将舞台交给了詹姆斯,以概述一些专为优化S3访问而设计的解决方案。
詹姆斯首先指出,S3的关键目标是使数据访问既容易又快速,而不需要用户手动调整性能。S3团队花费了大量时间来思考如何以无缝的方式提高简单性和性能。
在这个方向上最近的一个创新是S3挂载点,它将S3存储桶作为本地文件系统呈现,同时仍然提供原生S3的可扩展性和性能。这允许为文件访问设计的应用程序在不进行任何代码更改的情况下利用S3。具有内置文件支持的任何[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)框架都可以通过挂载点从S3中读取数据。
1. 在设计数据访问模式和存储布局时,应充分考虑以优化亚马逊S3的性能。
2. 如果适用,可以通过使用S3挂载点来提供一个无缝的文件系统界面。
3. 在必要时,可以利用针对特定框架(如PyTorch)的专用集成,例如PyTorch S3连接器。
由于S3具有卓越的可扩展性、成本效益以及与其[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)服务和框架的紧密整合,使其成为推动[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)工作负载的理想数据湖解决方案。近期的优化自动实现了更多的性能提升,使得客户能够更快速地构建出强大的模型。
在这次演讲中,发言者在谈论客户如何通过充分利用亚马逊[Amazon S3](https://aws.amazon.com/cn/s3/?trk=cndc-detail)的功能来训练他们的[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)模型时表现出了极大的热情。他们鼓励观众积极提问并提供更多的意见和建议。
**下面是一些演讲现场的精彩瞬间:**
领导者注意到了[Amazon S3](https://aws.amazon.com/cn/s3/?trk=cndc-detail)在[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)应用中的广泛应用。

作为一家企业,TII公司利用[Amazon S3](https://aws.amazon.com/cn/s3/?trk=cndc-detail)和SageMaker训练了一个包含3.5万亿个标记的数据集,参数数量达到了1800亿,并成功推出了受欢迎的Falcon系列模型。

领导者探讨了PyTorch为何逐渐成为训练[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)模型的首选框架。

在亚马逊云科技举办的re:Invent上,宣布了一款新的[Amazon S3](https://aws.amazon.com/cn/s3/?trk=cndc-detail)连接器,它将S3与PyTorch训练管道紧密结合,实现高效的数据进出。

在[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)训练过程中,检查点是影响训练时间和成本的耗时操作,因此优化检查点存储性能至关重要。

亚马逊云科技意识到现有的工具无法解决所有数据加载问题,因此通过提供Boto3和CLI等API支持,允许用户定制解决方案。
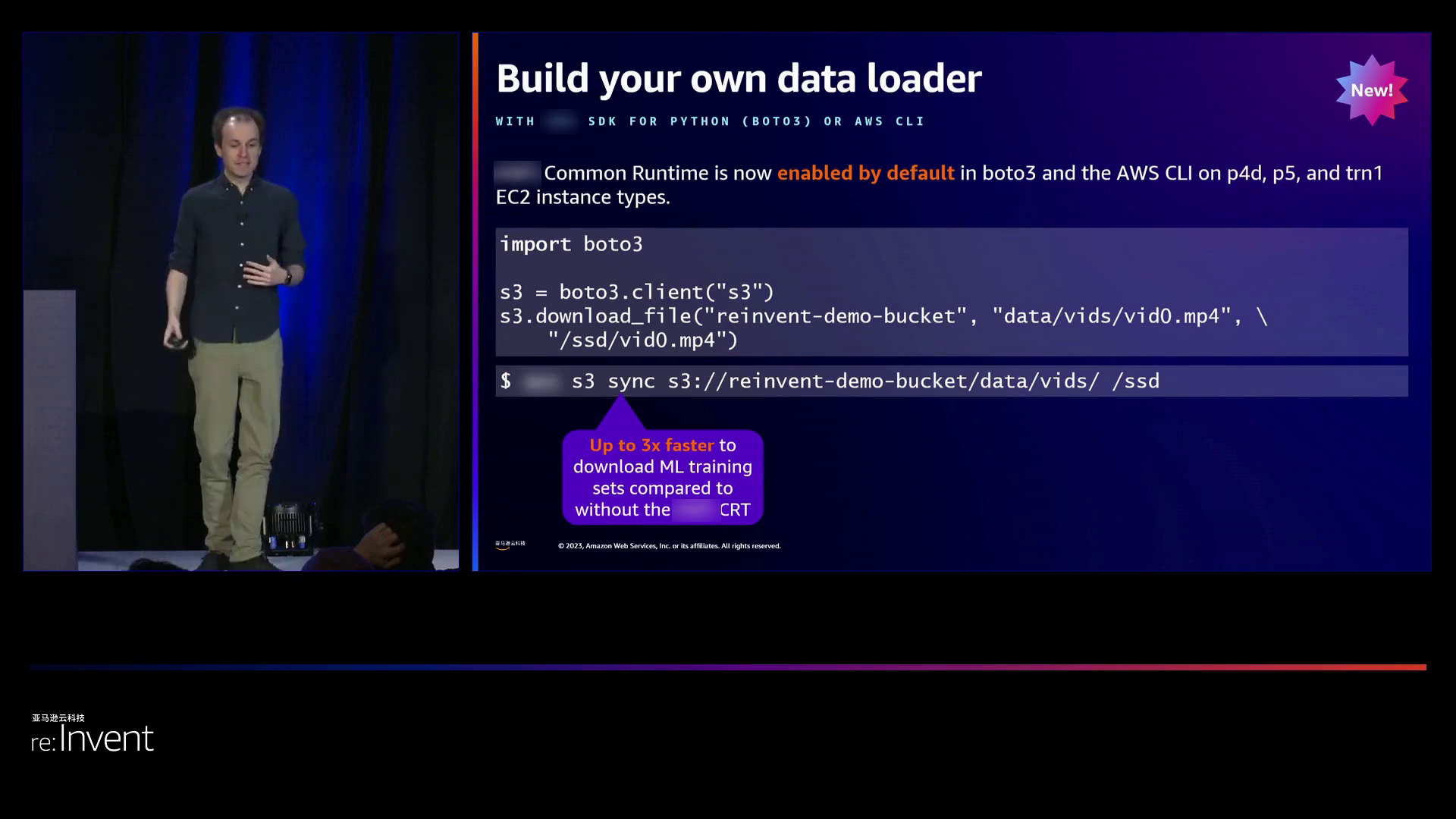
对于训练大型模型或保存大型模型检查点来说,S3连接器是PyTorch的一个非常合适的选择。

## 总结
亚马逊S3是[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)工作负载的理想存储解决方案,因其具有无限的可扩展性、高性能和高成本效益。在S3上训练ML模型时,优化数据访问模式对于最大化性能至关重要。
顺序读取允许连续访问数据,从而最小化延迟。相比之下,随机读取每次请求都会产生延迟。将数据存储在较大的对象中可以实现顺序访问。亚马逊S3的新S3 Express One Zone存储类提供了单位数毫秒的延迟,以缓解随机读取造成的瓶颈。
多种客户端选项简化了在S3上进行ML训练的过程。亚马逊SageMaker提供了管理数据加载的训练作业。亚马逊云科技的Mount Points将S3对象作为本地文件系统中的文件提供,以便实现透明且高性能的访问。新的PyTorch S3连接器有助于高效地加载数据和保存模型检查点。
总的来说,S3的可扩展性、弹性吞吐量、与ML服务的集成以及新的性能特性使其成为[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)的理想基础。调整数据访问模式是关键,而像S3 Express One Zone这样的新客户端选项可以简化直接从S3进行的训练。
## 演讲原文
## 想了解更多精彩完整内容吗?立即访问re:Invent 官网中文网站!
[2023亚马逊云科技re:Invent全球大会 - 官方网站](https://webinar.amazoncloud.cn/reInvent2023/?s=8739&smid=19458 "2023亚马逊云科技re:Invent全球大会 - 官方网站")
[点击此处](https://aws.amazon.com/cn/new/?trk=6dd7cc20-6afa-4abf-9359-2d6976ff9600&trk=cndc-detail "点击此处"),一键获取亚马逊云科技全球最新产品/服务资讯!
[点击此处](https://www.amazonaws.cn/new/?trk=2ab098aa-0793-48b1-85e6-a9d261bd8cd4&trk=cndc-detail "点击此处"),一键获取亚马逊云科技中国区最新产品/服务资讯!
## 即刻注册亚马逊云科技账户,开启云端之旅!
[【免费】亚马逊云科技“100 余种核心云服务产品免费试用”](https://aws.amazon.com/cn/campaigns/freecenter/?trk=f079813d-3a13-4a50-b67b-e31d930f36a4&sc_channel=el&trk=cndc-detail "【免费】亚马逊云科技“100 余种核心云服务产品免费试用“")
[【免费】亚马逊云科技中国区“40 余种核心云服务产品免费试用”](https://www.amazonaws.cn/campaign/CloudService/?trk=2cdb6245-f491-42bc-b931-c1693fe92be1&sc_channel=el&trk=cndc-detail "【免费】亚马逊云科技中国区“40 余种核心云服务产品免费试用“")
加速Amazon S3上的机器学习训练,3个小技巧助你节省时间和金钱
云计算
re:Invent

 0
0 0
0亚马逊云科技解决方案 基于行业客户应用场景及技术领域的解决方案
联系亚马逊云科技专家
亚马逊云科技解决方案
基于行业客户应用场景及技术领域的解决方案
联系专家

0
目录

 分享
分享 点赞
点赞 收藏
收藏 目录
目录立即注册,开启您的免费套餐
立即关注

亚马逊云开发者
公众号

User Group
公众号

亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
关于我们 
更多资源
开发者工具
更多支持
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
