## 视频
<video src="https://dev-media.amazoncloud.cn/30-LibaiGenerate/31-LiBaiRebrandingVideo/CMP208-Cutting_edge_AI_with_AWS_and_NVIDIA-LBrebrandingWCaptionCN.mp4" class="bytemdVideo" controls="controls"></video>
## 导读
多年来,组织一直在使用亚马逊云科技为自动驾驶、机器人自动化、个性化推荐、自动内容管理和增强现实,训练和部署[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)模型。生成式 AI 最新取得重大进展,各大公司正在为消费者重新打造用户体验,并改变工作场所。在本论坛中,了解如何在生成式 AI 过程的每个阶段(从模型训练到部署)使用 GPU 加速实例。了解组织如何采用全新 [Amazon EC2 ](https://aws.amazon.com/cn/ec2/?trk=cndc-detail)P5 实例训练模型,并利用 [Amazon EC2 ](https://aws.amazon.com/cn/ec2/?trk=cndc-detail)G5 实例划算地将模型部署到生产。
## 演讲精华
<font color = "grey">以下是小编为您整理的本次演讲的精华,共1500字,阅读时间大约是8分钟。如果您想进一步了解演讲内容或者观看演讲全文,请观看演讲完整视频或者下面的演讲原文。</font>
近年来,人工智能领域取得了重大突破,激发了人们的集体想象力。在过去几个月里,关于人工智能的讨论已成为社会的重要组成部分。然而,我们仅仅处于这一变革性技术的旅程的开始阶段。
本次讨论将重点关注如何利用亚马逊的云计算基础设施来推动最先进的人工智能技术。这得益于亚马逊与AI计算领域领导者Nvidia之间的长期合作关系。他们共同致力于构建云中功能最强的[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)计算实例。
演讲者包括BB,亚马逊EC2的高级产品经理;Samantha,同样是EC2的产品经理;以及Sorena,Pinterest的资深工程师。他们将涵盖一系列主题,从塑造人工智能发展关键趋势开始。
首先,过去几年里大型语言模型的爆炸式增长是一个显著趋势。这些模型的规模已从几年前的数百亿参数扩大到如今超过1万亿参数的最大模型。为了理解其庞大的规模,每个参数仅需1-2字节的内存。这意味着一个拥有1万亿参数的模型需要1太字节的内存来存储模型本身,而无需考虑数据集或任何工作内存。这在训练和推理过程中迫使模型在多个GPU上分割。
其次,训练这些模型所需的数据集规模也在不断扩大。随着语言模型越来越多地包含除文本之外的视觉和多模态特征,数据集可以轻松达到PB级别。处理如此大量的原始数据给训练流程带来了新的挑战,必须解决这些问题。
最终,训练工作的规模已经扩大,如今一些公司正在同时使用超过10,000个GPU。在数个月内协调数千个GPU训练一个模型需要高度关注的弹性和容错能力,以尽量减少中断。为了降低大规模训练的相关高昂成本,亚马逊云科技最近推出了[Amazon Bedrock](https://aws.amazon.com/cn/bedrock/?trk=cndc-detail),它提供了对预训练模型的即开即用访问,这些模型来自像Anthropic、Cohere和AI21 Labs这样的合作伙伴。这使得企业可以在不需要从头开始训练模型的情况下受益于强大的模型。
第二个主要趋势是开源AI社区中涌现的创新。公司正在构建像Ray和MosaicML这样的开源框架,以规模化地协调分布式训练。优化库如Meta的FSDP和Nvidia的Megatron加速了训练过程的关键部分。这些创新使得新技巧如生成性AI能够在智能聊天机器人、代码生成和创意媒体合成等用例中得到更快速的采用。
第三个趋势是对能源效率和可持续性的日益关注。客户越来越希望他们的ML基础设施能够环保,这促使亚马逊云科技在每推出新一代硬件时都能继续提高性能功耗比。亚马逊云科技仍然致力于支持亚马逊到2040年实现全球运营净零碳排放的目标。
在选择合适的ML基础设施时,客户会考虑几个关键因素。首先是性能,它决定了训练收敛时间和推断延迟。随着实例数量的线性扩展性能的能力也非常重要,尤其是在扩展到数百或数千个GPU时。在如此大的规模上,易于管理变得至关重要,以减少开销。成本也很重要,因为最先进的模型所需的基础设施可能非常昂贵。最后,对流行框架如PyTorch、TensorFlow和JAX的支持是关键,以便数据科学家可以立即高效地工作。
为了满足这些需求,亚马逊云科技的ML基础设施堆栈具有几层。在顶部是像图像识别和自然语言处理这样的全托管AI服务,它们提供对预训练模型的API访问。在中间是简化构建、训练和部署自定义模型的[Amazon SageMaker](https://aws.amazon.com/cn/sagemaker/?trk=cndc-detail)。
EC2实例在底层基础设施、网络、存储以及与其他开源框架的集成方面表现出色。作为亚马逊云科技的产品之一,它提供了来自Nvidia、AMD、Amazon Inferentia等公司的GPU加速计算能力,从而实现灵活性。例如,S3和FSx for Lustre等存储选项可以提供高效的Petabyte级容量。
弹性织物适配器(EFA)技术支持低延迟的GPU到GPU通信,以满足对实时响应要求较高的工作负载。诸如EKS、ParallelCluster和SageMaker等协调服务有助于高效地管理大规模集群。此外,与PyTorch等开源项目的深度集成使得客户能够迅速将解决方案部署到亚马逊云科技平台上。
在选择实例时,P系列提供了最强的GPU,如采用Hopper架构的Nvidia H100的新P5。每个H100 GPU都能达到惊人的8000太浮点数的FP16性能。通过NVSwitch互连,实现实例中任何两个GPU之间高达900 GB/秒的连通性。
另一方面,G系列实例为规模较小且需要进行训练和推断的应用提供了一个更通用的选择。新的G5配备了Nvidia的A10G GPU,相较于前一代产品,其价格性能提升了三倍。客户可以根据自己的需求选择合适的GPU、CPU、内存、存储和网络组合。
支持需要数千个GPU的高性能应用的关键技术就是弹性织物适配器。EFA通过网络提供超低直接GPU到GPU通信延迟,从而完全绕过多余的CPU处理过程。对于分布式训练中常见的集合通信操作,EFA可以加速P5实例上的数据传输速度,相较上一代的P4,速度提高了5倍。
为了满足高性能计算的需求,亚马逊云科技还提供了UltraClusters,今年进行了重新设计,以支持超过20,000个GPU的使用,同时降低了实例间的延迟。这对于网络密集型工作负载,如使用3D并行性、张量并行性和流水线模型并行性等方法进行的大型语言模型训练,具有显著优势。
针对不同类型的[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)应用场景,基础设施需求也会有所不同。例如,在规模化预训练过程中,大型语言模型需要依赖UltraClusters和P4或P5实例;而对于推断任务,较小的蒸馏模型可以在G4或G5实例上运行,而较大的模型则需要P4或P5实例具备足够的内存资源。
计算机视觉训练采用UltraClusters进行生成模型的训练,而较小的鉴别模型则适用于G5或P4d实例。除非大型生成模型需要更多的内存,否则推理通常能在G4或G5上顺利运行。推荐系统的训练初期需要UltraClusters和P4的支持,随后逐渐过渡到G5以实现高效且经济的增量更新。在G5或G4实例上可以并行处理推理任务。
为了展示这些技术的实际应用案例,亚马逊云科技的客户,如Adobe,正在使用P4、P5和G5实例来训练模型,以支持诸如Adobe Firefly之类的生成图像创建功能。自2022年初推出以来,Firefly的用户已通过该服务生成了超过40亿张图像。驱动这些AI模型的训练也是在亚马逊云科技上可用的相同类型的P4、P5和G5实例上进行的。
自动驾驶汽车公司Aurora使用P4、DG5和G4dn实例来训练他们的模型,并每天进行数百万次的模拟,以开发自动驾驶解决方案。这使他们在快速迭代的过程中能够将安全性构建到其系统中。
Pinterest已经优化了其基础设施以支持大规模的AI工作负载。他们会根据每个工作负载选择合适的实例类型,如P4d、G5以及通过EFA互连的UltraClusters。通过利用开源创新如PyTorch、CUDA图形和Ray框架,他们将推荐器模型的推理延迟降低了30%,相较于基于CPU的基础设施。
通过优化其模型和基础设施,他们已经能够在服务更大、更复杂的模型的同时提高效率。Pinterest强调了一个事实,即不再是一个尺寸适合所有情况——基础设施必须针对每个使用场景进行定制。优化基础设施,然后根据该信息优化模型,然后再重复这一过程,这推动了性能和效率的改进。
总之,有三个关键趋势正在推动AI的发展:爆炸性的大语言模型增长、开源社区创新以及对能源效率和可持续性的日益关注。客户在选择ML基础设施时会考虑性能、成本、可扩展性、易管理性和框架支持。
亚马逊云科技提供了一系列广泛的服务,包括EC2实例、网络、存储、协调和集成等,以满足各种需求。例如,EFA和UltraClusters等技术使得客户能够跨越数千个GPU来扩展高要求的工作负载。通过精心挑选合适的实例并根据每个应用场景定制基础设施,客户(如Pinterest)在部署前沿的人工智能创新时可以实现价格与性能的最佳平衡。
**下面是一些演讲现场的精彩瞬间:**
领导者们探讨了亚马逊与英伟达合作如何将云计算赋予强大的人工智能和[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)能力。

Pinterest指出了诸如框架碎片化等阻碍[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)速度的关键挑战,并提出了提高速度和用户参与度的解决方案。

亚马逊云科技正推出名为弹性GPU的全新功能,允许客户独立调整计算和GPU资源,以优化[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)训练的产出。

亚马逊云科技优化了推理过程,在满足实时模型运行延迟需求的同时,实现了GPU利用率的最大化。

通过将模型图作为整体操作进行静态捕捉,降低了启动时间。
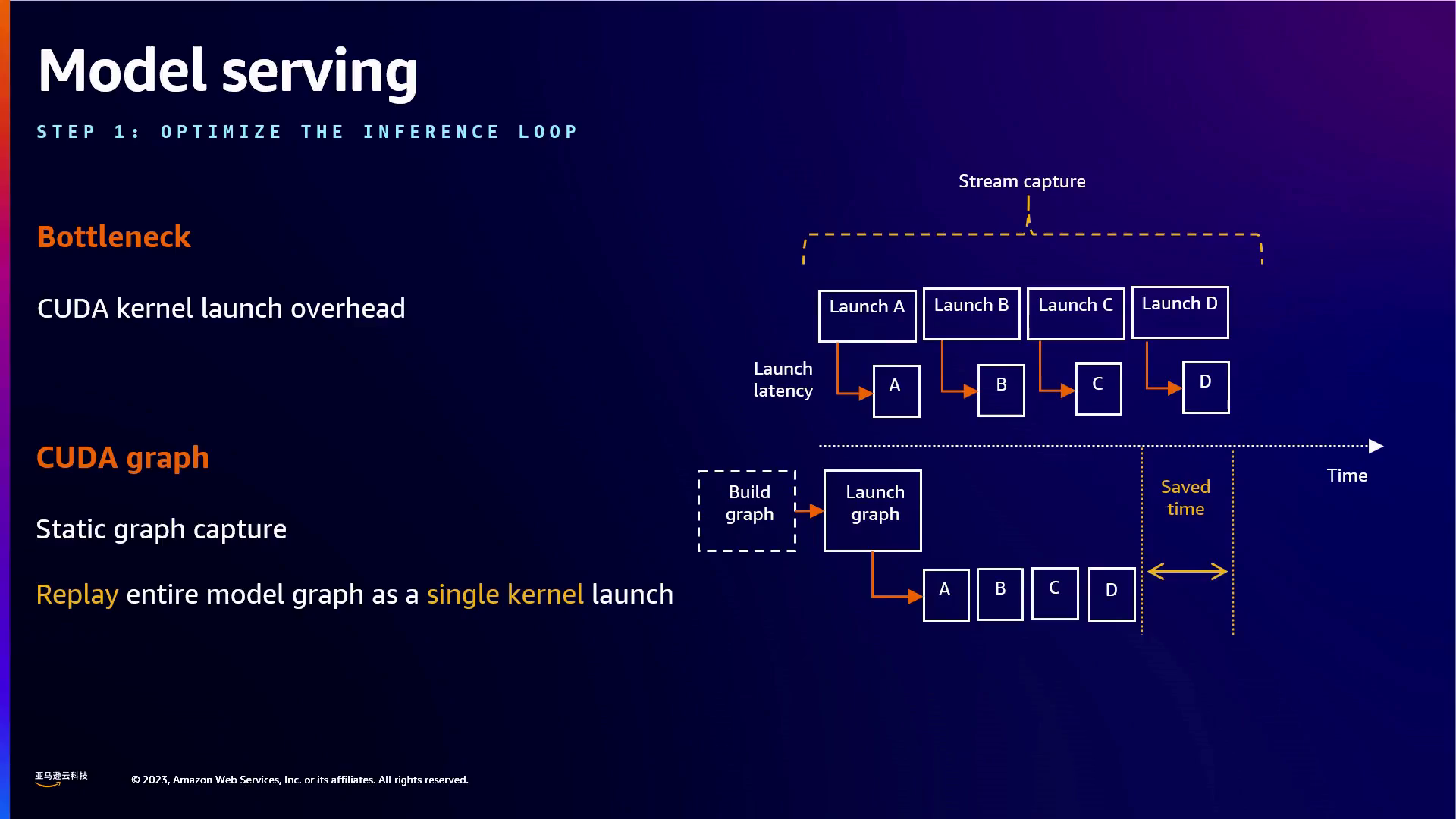
亚马逊云科技采用预分配内存块在CPU和GPU间高效传输数据,以实现更快的推理速度。

借助DCGM和Media Insights等工具对GPU性能进行分析并进行适当的大小调整,以提高效率。

## 总结
该视频探讨了如何通过亚马逊云科技和NVIDIA GPU来推动前沿人工智能技术的进步。视频中强调了塑造AI发展的三个主要趋势:大型语言模型的发展、大量数据集的应用以及在数千个GPU上进行大规模训练。
亚马逊云科技提供了广泛的基础设施服务来支持[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)工作负载,包括针对各种应用场景定制的GPU实例(如P4和G5)、EFA等网络功能以及EKS和Batch等调度服务。诸如Adobe和Aurora等企业正利用这些功能来推动创新的AI应用。
Pinterest结合亚马逊云科技的服务,如UltraClusters、Batch和EFA,以及P4和G5等GPU实例,以运行大规模分布式训练作业并提供低延迟的推断服务。他们通过在飞轮式方法中优化基础设施和模型来实现效率提升。他们的经验教训包括利用开源资源、针对调整大小进行性能分析以及为每个工作负载选择正确的硬件。
## 演讲原文
## 想了解更多精彩完整内容吗?立即访问re:Invent 官网中文网站!
[2023亚马逊云科技re:Invent全球大会 - 官方网站](https://webinar.amazoncloud.cn/reInvent2023/?s=8739&smid=19458 "2023亚马逊云科技re:Invent全球大会 - 官方网站")
[点击此处](https://aws.amazon.com/cn/new/?trk=6dd7cc20-6afa-4abf-9359-2d6976ff9600&trk=cndc-detail "点击此处"),一键获取亚马逊云科技全球最新产品/服务资讯!
[点击此处](https://www.amazonaws.cn/new/?trk=2ab098aa-0793-48b1-85e6-a9d261bd8cd4&trk=cndc-detail "点击此处"),一键获取亚马逊云科技中国区最新产品/服务资讯!
## 即刻注册亚马逊云科技账户,开启云端之旅!
[【免费】亚马逊云科技“100 余种核心云服务产品免费试用”](https://aws.amazon.com/cn/campaigns/freecenter/?trk=f079813d-3a13-4a50-b67b-e31d930f36a4&sc_channel=el&trk=cndc-detail "【免费】亚马逊云科技“100 余种核心云服务产品免费试用“")
[【免费】亚马逊云科技中国区“40 余种核心云服务产品免费试用”](https://www.amazonaws.cn/campaign/CloudService/?trk=2cdb6245-f491-42bc-b931-c1693fe92be1&sc_channel=el&trk=cndc-detail "【免费】亚马逊云科技中国区“40 余种核心云服务产品免费试用“")
亚马逊云科技与 NVIDIA 的尖端 AI
云计算
re:Invent

 0
0 0
0亚马逊云科技解决方案 基于行业客户应用场景及技术领域的解决方案
联系亚马逊云科技专家
亚马逊云科技解决方案
基于行业客户应用场景及技术领域的解决方案
联系专家

0
目录

 分享
分享 点赞
点赞 收藏
收藏 目录
目录立即注册,开启您的免费套餐
立即关注

亚马逊云开发者
公众号

User Group
公众号

亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
关于我们 
更多资源
开发者工具
更多支持
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
