## 视频
<video src="https://dev-media.amazoncloud.cn/30-LibaiGenerate/31-LiBaiRebrandingVideo/BOA308-Generative_AI__Architectures_and_applications_in_depth-LBrebrandingWCaptionCN.mp4" class="bytemdVideo" controls="controls"></video>
## 导读
在快节奏的 AI 世界中,先进的生成式 AI 概念至关重要。为了保持竞争力和创新性,企业必须努力理解和实施复杂的方法。但由于这些讨论的初级阶段,明确和全面的资源可能很稀少,造成有效利用的困难。本论坛通过深入探讨这些新兴概念,解决这个问题。通过讨论实际应用并详细介绍实现最佳实践,本论坛提供了一个具体的理解,使企业能够在生成式 AI 中有效地使用这些前沿发展。
## 演讲精华
<font color = "grey">以下是小编为您整理的本次演讲的精华,共1300字,阅读时间大约是6分钟。如果您想进一步了解演讲内容或者观看演讲全文,请观看演讲完整视频或者下面的演讲原文。</font>
亚马逊云科技在2022年拉斯维加斯举行的re:Invent上举办了一场关于生成性AI的讨论。今年,共有500多名热情观众涌向充满活力的礼堂,期待着了解这一新兴技术的发展。作为亚马逊云科技的开发者倡导者,Mike Chambers和Tiffany Fong专门研究人工智能,他们对众多与会者在繁忙的re:Invent日程中抽出时间参加他们在广阔校园里的1小时讲座表示感激。
Mike指出,今年是会议上唯一一场专门讨论生成性AI的会议。考虑到近年来关于生成性AI的巨大关注和兴趣,他对这么多人在繁忙的re:Invent日程中抽出时间参加他们的讲座表示感谢。
在舞台背景灯光明亮的背景下,Mike开始了互动式的观众调查问题:“您今天在工作负载或工作流中是否使用了生成性AI?”随着实时结果的出炉,Tiffany注意到有超过50%的人已经在他们的工作中使用了像ChatGPT这样的工具,用于生成代码片段或总结长文档等用途。Mike分享说,他本人定期使用生成性AI来创建演示文稿,发现它在制作内容方面非常有用。
在设定好观众对生成性AI的熟悉程度后,Mike简要回顾了一下它的定义以及它独特的地方。简单来说,生成性AI是根据收到的提示生成全新的内容,而不仅仅是预测现有数据。如今,大多数生成性AI应用的基础是大型语言模型(LLM)。Mike解释了LLM是如何工作的——它们在大量的文本数据(通常是TB级别的数据)上进行训练,需要大量的计算资源。2017年的变革性的突破是变换器架构,使模型能够从数百万扩展到数十亿、甚至万亿的参数,这解锁了新的涌现能力。过去的AI模型仅限于单一任务,如翻译或摘要,而LLM可以通用,能够执行各种自然语言任务,如回答问题、生成代码或创建摘要。
Tifani指出,现有的语言模型(LLM)存在一定的局限性。由于它们在广泛的公共数据集上进行预训练,因此缺乏针对特定业务或领域的专有知识。它们的知识在训练过程中被固定,这可能导致在不谨慎设计提示的情况下产生误解或不准确的回应。
为了克服这些限制,Mike深入研究了一种名为检索增强生成技术(RAG)的方法。RAG的核心思想是给LLM提供来自企业数据库或文档的相关数据,以扩展其输入,从而降低误解风险并提高准确性。这种方式并不依赖于LLM的预训练知识,而是利用外部数据源提供相关的事实以纳入输入中。尽管对LLM模型本身进行微调是另一种定制化方法,但与RAG相比,这需要更多的时间和数据。
为了让这些概念更易于理解,Tifani用一个比喻来形容RAG:RAG就像给一个学习巫术的学生提供魔法书一样。LLM是带着广泛的知识离开魔法学校的毕业生。然而,要应对像打败巨魔这样的新挑战,学生需要参考包含21个特定咒语的魔法书。在RAG中,LLM是学生,而像公司数据库这样的数据源扮演着魔法书的角色。
Mike随后通过Python进行了实际代码演示,展示了RAG的应用。他首先将21个示例文本咒语通过一个句子嵌入模型转换为1000维的数值数组,这个数值表示被编码成一个简单的内存向量数据库。接下来,Mike将一个问题嵌入到相同的向量空间中。通过查询索引找到最相似的4个向量,系统从数据库中检索出最相关的文本片段。最后,将这些检索到的文本并入提供给名为Claude的这个LLM的输入中。经过这种增强的输入后,Claude能够生成一个量身定制的准确回应。
Tifani强调了这种方法与无法访问外部数据的标准LLM的不同之处。Mike还澄清说,向量化过程与LLM内部发生的事情是分开的。虽然外部数据要经过一个嵌入模型进行有效的相似性搜索,但检索到的文本作为原始文本被注入回输入中,供LLM处理。
麦克介绍了代理的概念,这些代理本质上提供了API,使长短时记忆(LLM)不仅能够生成文本回应,还能采取行动。作为一个简单的例子,一个代理可以调用一个API来获取当前时间,而不是让LLM猜测时间。更先进的例子包括能够搜索零售网站并代表用户完成购买的代理。
提法尼通过一个完整的架构展示了所有组件是如何组合在一起的。用户的查询被发送到代理,代理会询问LLM是否需要更多数据来形成回应。如果需要,代理会从向量数据库中检索相关信息,用这些数据扩充提示,然后将增强的提示馈送给LLM以生成准确的回应。
麦克展示了亚马逊Bedrock如何在幕后无缝处理这些组件。控制台允许根据使用场景需求选择专门的基础模型,如多语言Jurassic、通用文本模型Claude或图像生成模型Stable Diffusion。数据源被摄入知识库中,自动处理向量化以便于高效检索。预构建的代理提供超过50个常见任务的API,例如与日历或云存储交互。
在重点转移到安全性、审计和合规性等重要主题时,麦克幽默地戴上了一个笔袋和保护领带。他强调了了解生成AI系统不同组件(应用程序、数据源和LLM)之间流动的数据的确切内容的重要性。敏感数据可能暴露给LLM以允许其构造合适的查询。像任何其他接触敏感数据的组件一样,LLM周围的适当记录、治理和合规控制是必不可少的。
提法尼概述了在高度监管的行业(如医疗保健和金融)中帮助满足这些要求的内置选项。S3和CloudWatch对LLM调用的日志记录提供了可能需要用于合规性的详细审计轨迹。PrivateLink支持私有连接,使得数据不会穿越公共互联网,这对于受监管的工作负载至关重要。
在未来,Tiffany表示,随着生成性人工智能(AI)的不断发展,针对准确性和安全性方面的定制化将成为业界关注的焦点。Mike也认同这一点,他认为实验阶段的应用正在逐步转向实际生产环境。他预测,未来的模型将变得更加复杂,甚至会出现诸如视频和音频生成等新的应用领域。最令他兴奋的是,Mike认为生成性AI将通过经济高效地提取数据洞察,从而实现以往因技术复杂性而无法完成的项目。
在总结中,Mike和Tiffany共同呈现了一场深入浅出、引人入胜的演讲,探讨了生成性AI的巨大潜力和负责任开发的重要性。一个小时的讲座通过流畅的概念整合、实时代码演示以及生动的案例讨论,成功地达到了其目标——深入介绍这一革命性技术的架构和应用。与会者们带着更加丰富的知识离开了会场,以便能够更好地推动生成性AI的合理应用并为实现美好未来做好准备。
**下面是一些演讲现场的精彩瞬间:**
领导者强调,生成式人工智能能够通过生成图像和文字等内容,展示出重要的技术进步。

他们指出,为了应对复杂问题和关注新兴领域,拥有适当的数据和工具至关重要。

领导者还探讨了如何将文本数据转化为嵌入空间,以便用于[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)和深度学习。
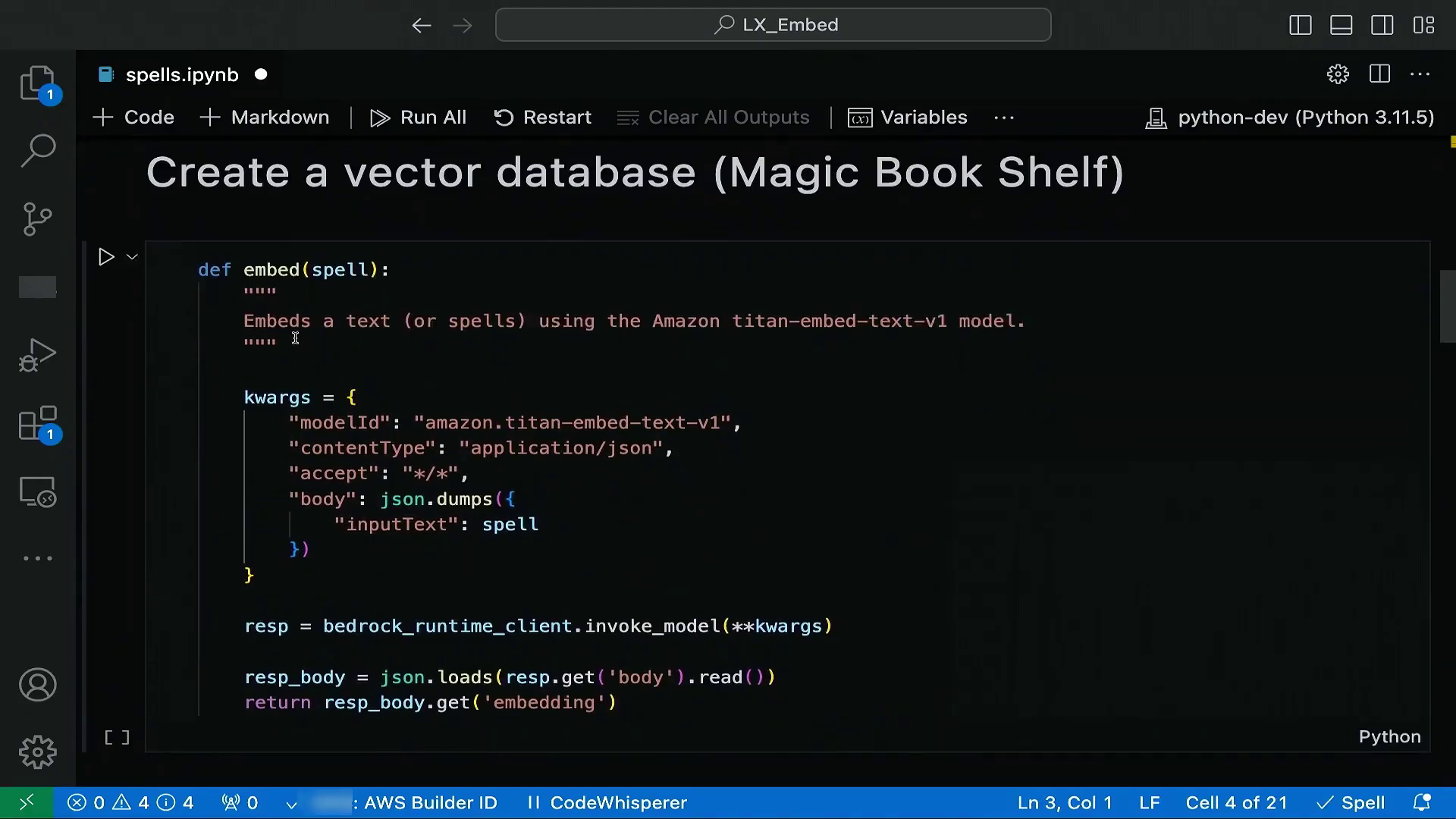
演讲者展示了如何通过[Amazon Bedrock](https://aws.amazon.com/cn/bedrock/?trk=cndc-detail)标准SDK界面调用AI模型,例如进行文本嵌入。

这个应用利用亚马逊云科技的服务来理解自然语言请求、查询数据源以及向用户提供自然语言回应。

亚马逊云科技提供了预先训练好的[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)模型,使得从数据中提取价值变得简单且经济实惠。

## 总结
生成性人工智能作为一项快速发展的技术,具有巨大的潜力。在这次深入剖析的演讲中,全面概述了其从基本概念到前沿应用的发展历程。
演讲者首先阐述了大型语言模型如何成为生成性人工智能的核心。通过对大量数据集进行预训练,这些模型具备了诸如生成图像和文字,以及回答自然语言问题等各种能力。然而,它们的知识仍受限于训练数据。
为了克服这些限制,研究人员采用了检索辅助生成和对话代理的方法。通过这些方法,它们可以为提示提供上下文,减少幻觉并准确地回答问题。演讲者还展示了用于操作向量数据库和提示的代码示例。类似亚马逊Bedrock的全托管服务自动化了整个流程。
随着能力的提高,责任也随之增加。演讲者强调了在监管范围内保护生成性模型的重要性。日志记录、审计和专用端点有助于满足合规需求。
展望未来,定制解决方案的使用将成为关键。这将使以前无法实现的项目得以实现,预示着一个充满希望的生成性人工智能的未来。然而,随着能力的增长,负责任的管理仍将至关重要。
## 演讲原文
## 想了解更多精彩完整内容吗?立即访问re:Invent 官网中文网站!
[2023亚马逊云科技re:Invent全球大会 - 官方网站](https://webinar.amazoncloud.cn/reInvent2023/?s=8739&smid=19458 "2023亚马逊云科技re:Invent全球大会 - 官方网站")
[点击此处](https://aws.amazon.com/cn/new/?trk=6dd7cc20-6afa-4abf-9359-2d6976ff9600&trk=cndc-detail "点击此处"),一键获取亚马逊云科技全球最新产品/服务资讯!
[点击此处](https://www.amazonaws.cn/new/?trk=2ab098aa-0793-48b1-85e6-a9d261bd8cd4&trk=cndc-detail "点击此处"),一键获取亚马逊云科技中国区最新产品/服务资讯!
## 即刻注册亚马逊云科技账户,开启云端之旅!
[【免费】亚马逊云科技“100 余种核心云服务产品免费试用”](https://aws.amazon.com/cn/campaigns/freecenter/?trk=f079813d-3a13-4a50-b67b-e31d930f36a4&sc_channel=el&trk=cndc-detail "【免费】亚马逊云科技“100 余种核心云服务产品免费试用“")
[【免费】亚马逊云科技中国区“40 余种核心云服务产品免费试用”](https://www.amazonaws.cn/campaign/CloudService/?trk=2cdb6245-f491-42bc-b931-c1693fe92be1&sc_channel=el&trk=cndc-detail "【免费】亚马逊云科技中国区“40 余种核心云服务产品免费试用“")
生成式 AI:深度架构和应用程序
云计算
re:Invent

 0
0 0
0亚马逊云科技解决方案 基于行业客户应用场景及技术领域的解决方案
联系亚马逊云科技专家
亚马逊云科技解决方案
基于行业客户应用场景及技术领域的解决方案
联系专家

0
目录

 分享
分享 点赞
点赞 收藏
收藏 目录
目录立即注册,开启您的免费套餐
立即关注

亚马逊云开发者
公众号

User Group
公众号

亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
关于我们 
更多资源
开发者工具
更多支持
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
