## 视频
<video src="https://dev-media.amazoncloud.cn/30-LibaiGenerate/31-LiBaiRebrandingVideo/ARC327-5_things_you_should_know_about_resilience_at_scale-LBrebrandingWCaptionCN.mp4" class="bytemdVideo" controls="controls"></video>
## 导读
十七年的亚马逊云科技运行经验让我们学会了如何针对服务可能出现的问题(尤其是大规模服务)构建缓解措施。参加本讲座,您将了解到更重要的、但却鲜为人知的问题,即如何在意外发生时缩短缓解时间。亚马逊云科技运营领导者在此方面拥有丰富的经验,在许多情况下,他们都是通过艰苦的方式了解到这一点的。
## 演讲精华
<font color = "grey">以下是小编为您整理的本次演讲的精华,共1500字,阅读时间大约是8分钟。如果您想进一步了解演讲内容或者观看演讲全文,请观看演讲完整视频或者下面的演讲原文。</font>
Video presentations by three Amazon Web Services (亚马逊云科技) experts – Alec Peterson, Mike Furr, and Becky Weiss – were introduced at the event. According to Alec, former Amazon Web Services CEO Andy Jassy often stated that "there is no such thing as a compression algorithm for operational experience." This indicates the immense value of practical experience gained from handling large-scale operations over the years.
With a combined experience of approximately 30 years, these speakers are responsible for operating some of the largest and most critical 亚马逊云科技 services. Their goal is to distill their key learnings on achieving internet-scale resilience.
Alec began by delving into the first key concept – dependency management and patterns. He defined dependencies as the things that applications use to provide functionality, such as Amazon Web Services services like S3 and SQS, internal services like the authentication system, and infrastructure elements like the network and DNS.
Dependencies allow applications to leverage external functions to build a service-oriented architecture. However, intersections between dependencies can also create opportunities for failure propagation. Alec emphasized the need to carefully consider how dependencies intersect and plan for their combination in case of failure, particularly as systems scale to internet-scale.
To illustrate this risk, Alec introduced the concept of application "patterns" – basic changes in behavior. He provided a common example, describing how caching could be used in front of a database to improve performance. This pattern was very effective in the early stages. But it could also cause potential issues in the future due to a shift in the pattern.
Specifically, if the cache fails, all application traffic suddenly shifts to the database, which may not be able to handle the sudden surge in load. In the early stages of the application's life cycle, the database might be able to handle the traffic level before the cache. But as time goes by, the front-end system and cache can expand to meet growing demands, while the database does not receive the same expansion signal.
As a result, years later, a cache failure could cause the database to handle more traffic than it was designed to handle alone – an increase of up to 10 or 100 times the original level. This initial improvement in recovery through the cache mechanism has now become a threat to availability due to the sudden shift in patterns.
亚历克分享了一个关于亚马逊云科技的故障类型实际案例。在过去,Route 53的DNS服务器会直接查询中央数据库以检查DNS记录更新。为了减轻数据库负载,亚马逊云科技将更新方式改为发布到S3供服务器访问。这种方法起初取得了良好的效果。
然而有一天,数据库在将更新发布到S3方面出现了滞后。这使得DNS服务器开始频繁地向已经不堪重负的数据库请求获取最新数据。这导致了一个恶性循环,从预期的基于S3的架构突然转变到了直接查询数据库的模式。
基本的教训是,如果备用功能如缓存和冗余数据源不被定期使用,它们可能会削弱长期弹性。最好的方法是完全删除有问题的备用功能,或者经常测试它们以避免在压力下出现突然的模式转换。亚历克强调,要避免潜在的模式转换,或者在无法避免时优雅地处理它们。
接下来,迈克·福尔介绍了第二个关键主题——冲击半径。他将冲击半径定义为组件故障或更改可能造成的范围影响。弹性系统不仅关注最大化可用性,还假设失败会发生,并在整个开发周期(从设计到部署和运营)相应地进行准备。
为了说明这个概念,迈克提供了一个简单的架构示例,其中两个EC2实例使用通用IAM策略授予所需权限来访问一个S3存储桶。这似乎具有很高的可用性,因为实例跨AZ分布,但对IAM策略的冒险更改可能会同时破坏所有实例。
为了解决这个问题,可以引入一个试验实例并首先对其滚动更新政策进行更改,以限制不良更新的冲击半径。然而,对试验实例设置正确的警报阈值可能会很棘手——今天有效的可能在明天整体EC2舰队扩大时不再有效。更好的方法是对每个故障边界进行独立监控,而不是跨不相关的组件平均度量。
对于真正的风险更改,迈克建议采用“先回滚”策略——在部署后立刻回滚,甚至在确认有问题之前。这最小化了任何发生失败的冲击半径和持续时间。
关键在于理解任何变更的潜在影响,并仔细监控特定范围,而非在平均数中稀释信号。通过分段故障边界并缩短恢复时间框架,也有助于降低影响范围。
接下来,Becky Weiss研究的是第三个领域——队列。队列有助于解除系统组件之间的依赖关系。即使在消费者暂时无法处理请求的情况下,生产者仍可以将工作放入队列并成功响应。然而,队列也可能累积状态并导致恢复延迟。
例如,当一个下游消费者服务出现问题时,前面的队列会继续增长,因为生产者会继续入队消息。最终,恢复时间取决于消费者在恢复后能多快地清空积压。
因此,密切关注队列的深度和项目的年龄对于了解可能的恢复时间框架至关重要。如果消费者跟不上生产者的速度,可以通过将旧项目暂存一边并将消费者的能力集中到新项目上来提供帮助。当队列达到阈值时,其他有意使调用失败的压力缓解方法,如故意失败,也是一个选项。
关键在于密切注意队列的增长,并制定限制其增长的计划。否则,即使解决了根本原因,漫长的队列积压也可能显著延长停机时间。快速排空队列是快速恢复的关键。
接着,Becky研究了错误与弹性之间非明显的但重要的关系。她指出,错误通常分为两类:400级别的客户端错误和500级别的服务器错误。
400类错误代表诸如缺少资源或授权失败的案例,这些问题客户端需要解决。500类错误代表客户端无法控制的内部服务器故障。
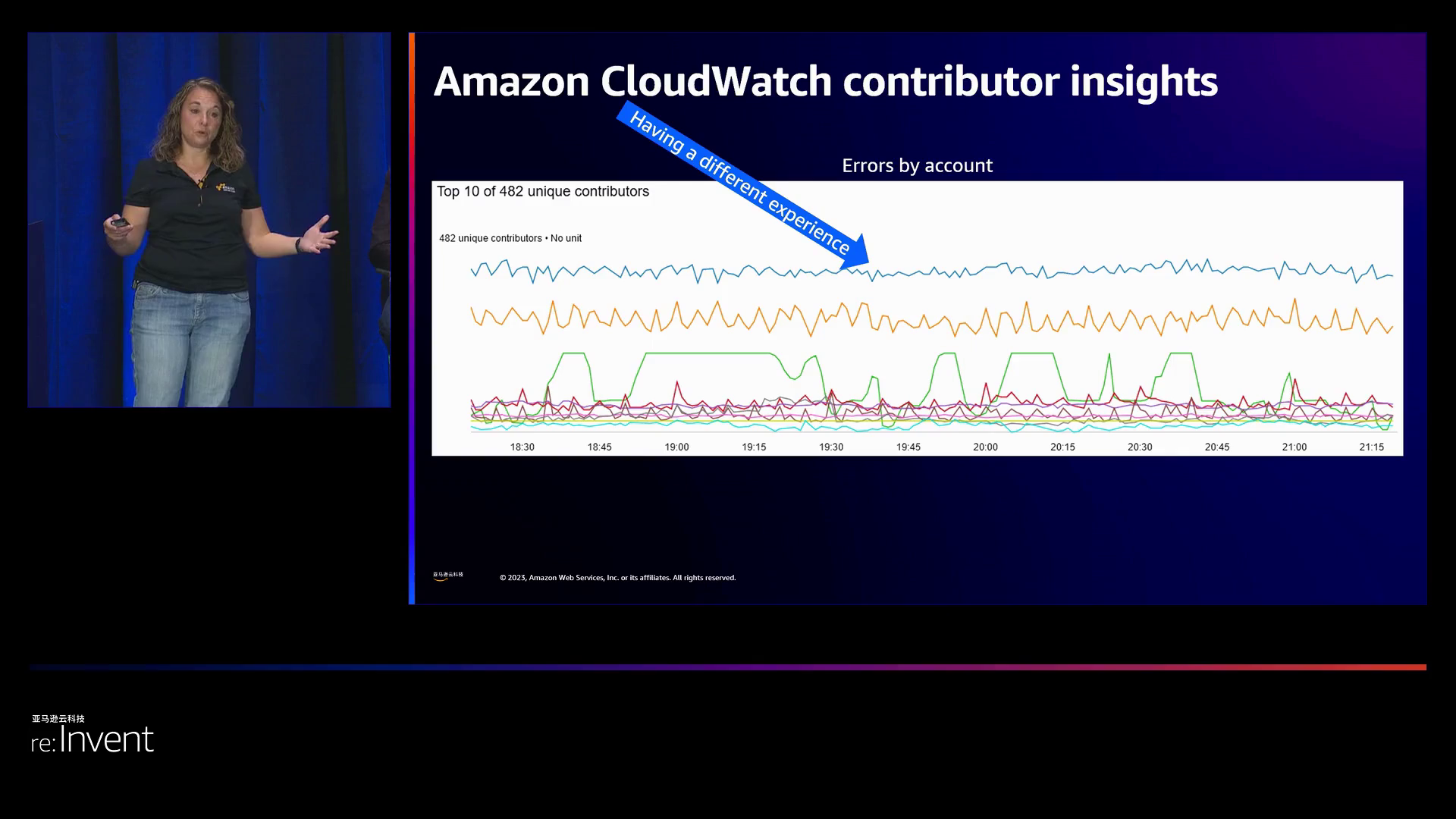
Becky分享了示例图表,展示了这两种错误类型在大规模上呈现出非常不同的模式。500错误在停机期间激增,提供了一个明确的信号问题。400错误稳定在正常范围内,提供了噪音,但没有多少洞察力。
因此,正确地将错误分类为400和500错误在检测实际停机和安全事件方面具有巨大的帮助。甚至具有总体良好可用性的服务也可能存在局部问题——某些用户可能比其他用户体验到更多的500错误。
监控端点而非整个服务,这样可以更好地了解局部故障的情况。Rebecca建议利用CloudWatch的贡献者洞察来快速定位出现异常错误率的用户。
其主要观点是,要确保对错误进行细致的分类,以便快速发现潜在问题。不应让400级别的噪声掩盖掉真正的500级别错误信号。通过细粒度的监控和分段分析,可以发现可能被全局平均所忽略的问题。
此外,Alec讨论了重试策略的利弊。尽管重试有助于掩盖短暂的服务中断,但它会增加已紧张组件的负载。在具有多个嵌套服务调用的系统中,这种影响会产生级联效应。例如,如果服务A调用服务B,而服务B又调用服务C,且C发生故障,那么当A和B都重复调用C时,C将会面临指数级的更多流量。这可能导致C的恢复时间被推迟。
理想情况下,如果C发生故障,中间服务如B不应重试。然而,跳过重试会降低B的可用性指标。一个更好的方法是,如果C发生故障,B应快速拒绝来自A的调用,而不是无谓地多次重试C。这样,可以通过避免向C发送来自多个层次的重复重试来加速恢复过程。
当重试真的很重要时,Alec分享了EC2的内部DNS解析器所采用的一种方法。他们主动向上游DNS服务发送重复的请求,而不是在失败时重试。这避免了DNS流量的突然激增,从而以更高的基线负载为代价。
总之,重试不可避免地增加了故障组件的负担。诸如快速失败、退避、重试预算和大规模重复请求等技术可以帮助减轻损害。但在优化可用性和加速恢复之间存在基本权衡。
Alec通过回顾主要收获来总结:避免有问题的模式转换,限制破坏范围,关注队列增长,仔细分类错误,并警惕级联重试。牢记这些原则将有助于构建更健壮的系统,能在互联网规模上可靠地运行。
尽管已经将内容简化为了关键信息,但这份详尽的概述旨在精确而全面地呈现视频中亚马逊云科技专家涉及的所有细节、案例和建议。其核心在于在保证技术准确性的同时,以通俗易懂且详尽的故事方式解读视频中的概念和现实世界的洞察。
**下面是一些演讲现场的精彩瞬间:**
演讲者鼓励听众将所学知识应用于他们的项目,以便从中汲取亚马逊云科技的实践经验。

他强调了对高风险变更具备快速回滚策略的重要性,以确保能够快速恢复正常运行。

演讲者还强调了了解客户需求模式以优化服务质量的重要性。
他详细解释了如何通过重试和错误代码(如500)帮助应用程序优雅地应对临时性服务问题。

演讲者强调,在处理故障时,弹性和稳定性往往比追求完美更为重要。

他还探讨了如何处理代码中的依赖关系、设计模式、影响范围、警告、错误、重试以及意外连接等问题。

## 总结
关注依赖关系和模式": 编辑认为,应重点关注系统的依赖关系和模式,以确保它们的交互不会导致故障。例如,尽管亚马逊云科技服务或内部组件之间的依赖关系本身并无不妥,但这些依赖关系的交集可能会成为问题的根源。此外,模式的变化,通常是通过对弹性进行优化的回退路径来实现,但实际上可能会长期降低系统的弹性,因为它们并未对主要路径进行足够的锻炼。因此,应尽量消除这些回退路径,或者在必要时频繁切换模式,以防止意外的弹性损失。
"管理爆炸半径": 编辑建议,为了减小潜在故障的影响范围,应采用诸如金丝雀部署等故障隔离技术来限制故障的损害。同时,应仅监控各个隔离边界的状况,而非仅仅关注聚合指标。对于高风险的更改,应积极执行回滚操作,以减轻爆炸半径带来的时间压力。
"队列和积压的管理": 编辑强调,队列可以解耦合系统并提高其可用性。但是,长时间的停机可能会导致队列中堆积大量过时的工作,从而延缓恢复进程。因此,应密切关注队列的长度和项目的年龄,并适时丢弃过时的项目。同时,还应了解队列的排放速率,并通过合理地绑定队列来控制积压情况。
"错误处理的优化": 编辑指出,应在监控系统中明确区分客户端错误和服务器错误。服务器错误可以作为停机信号,而客户端错误则可能导致误报。通过正确地识别和处理错误类型,可以更清晰地展示真正的信号,从而有助于快速发现和解决故障。
"重试策略的调整": 编辑建议在依赖关系中尽量避免不必要的重试,因为在某些情况下,重试可能会增加失败服务的负担,进而加剧停机时间。而在必须进行重试的关键场景下,可以在正常操作过程中主动进行重试,以减轻剧变带来的影响。
总结起来,应关注依赖关系和模式、管理爆炸半径、优化队列和积压管理、正确处理错误以及调整重试策略。通过这些实践,可以提高系统在大规模环境下的弹性能力。
## 演讲原文
## 想了解更多精彩完整内容吗?立即访问re:Invent 官网中文网站!
[2023亚马逊云科技re:Invent全球大会 - 官方网站](https://webinar.amazoncloud.cn/reInvent2023/?s=8739&smid=19458 "2023亚马逊云科技re:Invent全球大会 - 官方网站")
[点击此处](https://aws.amazon.com/cn/new/?trk=6dd7cc20-6afa-4abf-9359-2d6976ff9600&trk=cndc-detail "点击此处"),一键获取亚马逊云科技全球最新产品/服务资讯!
[点击此处](https://www.amazonaws.cn/new/?trk=2ab098aa-0793-48b1-85e6-a9d261bd8cd4&trk=cndc-detail "点击此处"),一键获取亚马逊云科技中国区最新产品/服务资讯!
## 即刻注册亚马逊云科技账户,开启云端之旅!
[【免费】亚马逊云科技“100 余种核心云服务产品免费试用”](https://aws.amazon.com/cn/campaigns/freecenter/?trk=f079813d-3a13-4a50-b67b-e31d930f36a4&sc_channel=el&trk=cndc-detail "【免费】亚马逊云科技“100 余种核心云服务产品免费试用“")
[【免费】亚马逊云科技中国区“40 余种核心云服务产品免费试用”](https://www.amazonaws.cn/campaign/CloudService/?trk=2cdb6245-f491-42bc-b931-c1693fe92be1&sc_channel=el&trk=cndc-detail "【免费】亚马逊云科技中国区“40 余种核心云服务产品免费试用“")
关于规模弹性,您应该知道的 5 件事
云计算
re:Invent

 0
0 0
0亚马逊云科技解决方案 基于行业客户应用场景及技术领域的解决方案
联系亚马逊云科技专家
亚马逊云科技解决方案
基于行业客户应用场景及技术领域的解决方案
联系专家

0
目录

 分享
分享 点赞
点赞 收藏
收藏 目录
目录立即注册,开启您的免费套餐
立即关注

亚马逊云开发者
公众号

User Group
公众号

亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
关于我们 
更多资源
开发者工具
更多支持
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
