## 视频
<video src="https://dev-media.amazoncloud.cn/30-LibaiGenerate/31-LiBaiRebrandingVideo/ANT319-Building_an_open_source_data_strategy_on_AWS-LBrebrandingWCaptionCN.mp4" class="bytemdVideo" controls="controls"></video>
## 导读
参加本讲座,了解如何充分利用开源解决方案,同时利用亚马逊云科技云端的可扩展性、灵活性和成本效益。亚马逊云科技为流行的开源框架和格式提供广泛支持,例如 Apache Spark、Apache Hive、Trino、Apache-Iceberg、OpenSearch、Apache-Flink、Apach Kafka 等。了解亚马逊云科技如何与开源分析社区合作,以交付和加速创新。了解亚马逊云科技在众多服务中的集成和支持如何帮助您实现更深入、更快的见解。
## 演讲精华
<font color = "grey">以下是小编为您整理的本次演讲的精华,共1300字,阅读时间大约是6分钟。如果您想进一步了解演讲内容或者观看演讲全文,请观看演讲完整视频或者下面的演讲原文。</font>
在过去几十年里,开源软件彻底改变了软件工程的面貌。正如来自亚马逊云科技的Ian Massingham和Narayanan Navaneethan两位专家所述,开源使得基于社区的创新、透明度和生产力得以在打造世界一流软件方面实现。作为领先的云计算平台,亚马逊云科技拥有超过200项服务,致力于利用开源以客户需求为导向,并从活跃的开源社区中汲取经验,同时也有助于提高开源项目的质量、安全和性能。
专家们指出,亚马逊云科技已经创建了一个广泛且兼容的开源服务组合,这些服务共同帮助客户实现从数据处理到专用数据库构建端到端的数据分析架构。在云上大规模运行开源软件可以降低客户的维护费用高达75%,同时他们仍然可以灵活地定制和扩展现有开源平台。亚马逊云科技还为上游开源项目贡献了诸如高可用性、可扩展性和易维护性等功能。该公司还与开源领导者及社区建立了紧密的合作关系,而非单打独斗。
为了详述这一点,亚马逊云科技将其架构划分为两个层面:控制平面(包括API和终端)和数据平面(包括底层基础设施和服务实例)。在数据平面上大量采用开源,同时仍通过亚马逊云科技的控制平面实现易于管理。专家们阐述了亚马逊云科技开源方法的两种模式。在托管开源模式下,如[Amazon EMR](https://aws.amazon.com/cn/emr/?trk=cndc-detail)、Managed Kafka、Managed Airflow等服务允许客户在自己的账户中运行开源软件,与上游开源发布的版本保持一致,时间不超过30-60天。例如,像Zomato这样的客户使用EMR和开源Druid、Presto来提高性能25%并降低计算成本30%,这些都在亚马逊云科技Graviton处理器上运行。在兼容模式下,如[Amazon DocumentDB](https://aws.amazon.com/cn/documentdb/?trk=cndc-detail)、[Amazon Keyspaces](https://aws.amazon.com/cn/keyspaces/?trk=cndc-detail)等服务展示出与开源的API或协议兼容性,而无需一定要在相同的开源代码上实施。
构建一个强大且可扩展的数据湖是高级分析的关键基石。作为主要的数据湖选择之一,[Amazon S3](https://aws.amazon.com/cn/s3/?trk=cndc-detail)提供了卓越的持久性(99.999999999%,即11个9)、可用性(99.99%)以及对太字节级数据的可扩展性。S3的智能分层功能能自动将不常访问的数据迁移到低成本的存储层,从而优化成本高达75%。演讲者强调了如何使用像Apache Iceberg这样的开源表格式来创建交易数据湖。Iceberg支持插入、更新、删除操作,具有最快可达100倍的更快扫描规划速度和可变的数据湖存储模式。亚马逊云科技服务如[Amazon EMR](https://aws.amazon.com/cn/emr/?trk=cndc-detail)支持读取和写入Iceberg表格式。亚马逊云科技在Iceberg社区中有4位贡献者,以提高在像Apache Spark等项目上的性能。例如,Traloca等客户使用基于S3的Iceberg来标准化API合约的创建和管理。
亚马逊云科技为客户提供一系列超过100种专为特定目的设计的数据库选项,包括关系型、键值对、文档、图形和时间序列数据库。演讲者描述了如何像[Amazon Aurora](https://aws.amazon.com/cn/rds/aurora/?trk=cndc-detail)、[Amazon DocumentDB](https://aws.amazon.com/cn/documentdb/?trk=cndc-detail)、[Amazon Keyspaces](https://aws.amazon.com/cn/keyspaces/?trk=cndc-detail)、[Amazon Neptune](https://aws.amazon.com/cn/neptune/?trk=cndc-detail)和[Amazon Timestream](https://aws.amazon.com/cn/timestream/?trk=cndc-detail)这样的一些数据库集成了开源功能兼容性,同时提供了完全托管服务的优势。例如,[Amazon Aurora](https://aws.amazon.com/cn/rds/aurora/?trk=cndc-detail)提供MySQL和PostgreSQL兼容性,同时提供比开源数据库引擎快5倍的性能。DocumentDB提供了MongoDB 4.2协议兼容性,同时本机集成到亚马逊云科技的基础设施以实现可扩展性和安全性。
Apache Kafka正成为构建实时数据管道的事实上的事件流平台。大多数组织在运行Kafka方面都面临挑战。Amazon MSK或Managed Streaming for Kafka使客户能够轻松运行安全且高可用性的Kafka集群,存储数PB的数据。亚马逊云科技利用多年运行Kafka的经验,为客户提供良好的架构默认设置和自动扩展能力。对于希望实现[无服务器](https://aws.amazon.com/cn/serverless/?trk=cndc-detail)化的客户,MSK Serverless可以免除所有集群管理任务。亚马逊云科技还在创新诸如分层存储等特性,以分离Kafka的计算和存储,实现几乎无限期的保留。
对于数据处理,[Amazon EMR](https://aws.amazon.com/cn/emr/?trk=cndc-detail)提供了高效运行大数据框架的方法,包括支持批量和交互式工作负载的Apache Spark、Hive和Hadoop。EMR具有自动配置、集群优化以及对超过25个开源框架的版本管理等功能。例如,新的Spark版本在EMR中可在开源发布后90天内获得。EMR与EC2、S3、EKS等亚马逊云科技服务以及混合选项(如在Outposts上运行EMR)相结合,为客户部署大数据工作负载提供了灵活性。Augury使用EMR和Spark实现在规模上的低延迟[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)。对于实时流处理,如亚马逊MSK和用于Apache Flink的亚马逊托管流处理等服务简化了运行规模的Kafka和Flink集群实现每秒数百万次读取和写入。
在搜索和运营分析领域,亚马逊最近推出了[Amazon OpenSearch Service](https://aws.amazon.com/cn/opensearch-service/?trk=cndc-detail),轻松部署和扩展OpenSearch集群。作为Elasticsearch的开源替代方案,OpenSearch已迅速获得超过3亿次的采用。亚马逊云科技还为Prometheus和Grafana等开源观测工具提供完全管理的服务,以便进行指标监控。演讲者强调了使用亚马逊云科技服务,如用于Apache Airflow的亚马逊托管工作流程和如亚马逊云科技CloudFormation等基础设施即代码工具,如何使客户能够在云上轻松地编排和自动化他们的端到端数据管道。可重复使用的基础设施模板有助于快速在账户和区域之间复制架构。
为了更具体地说明这些概念,演讲者通过一些常见的客户架构模式来说明流处理、批处理和[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)平台的工作负载。对于诸如分析金融交易等流处理用例,典型的架构可能包括将数据流入亚马逊MSK,使用亚马逊托管流处理进行Apache Flink的实时流处理以实现秒级聚合,将聚合的数据存储到使用开放格式的亚马逊S3数据湖中(如Apache Iceberg),使用亚马逊云科技Glue进行目录管理,并使用亚马逊Athena让分析师运行交互式SQL查询。检测到
在批量处理架构中,来自不同来源(如数据库、SaaS应用程序和存储)的数据可以被输入到亚马逊S3中。作为一家全球领先的云计算公司,亚马逊云科技通过其提供的服务,如数据库迁移服务、亚马逊Appflow和数据同步服务等,实现了强大的数据传输机制。原始数据被存储在亚马逊S3的数据湖中,随后使用诸如运行Spark的亚马逊EMR或亚马逊Glue等服务进行转换,以便进行编目以供分析。同一份数据还可以用于在亚马逊SageMaker中训练[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)模型。
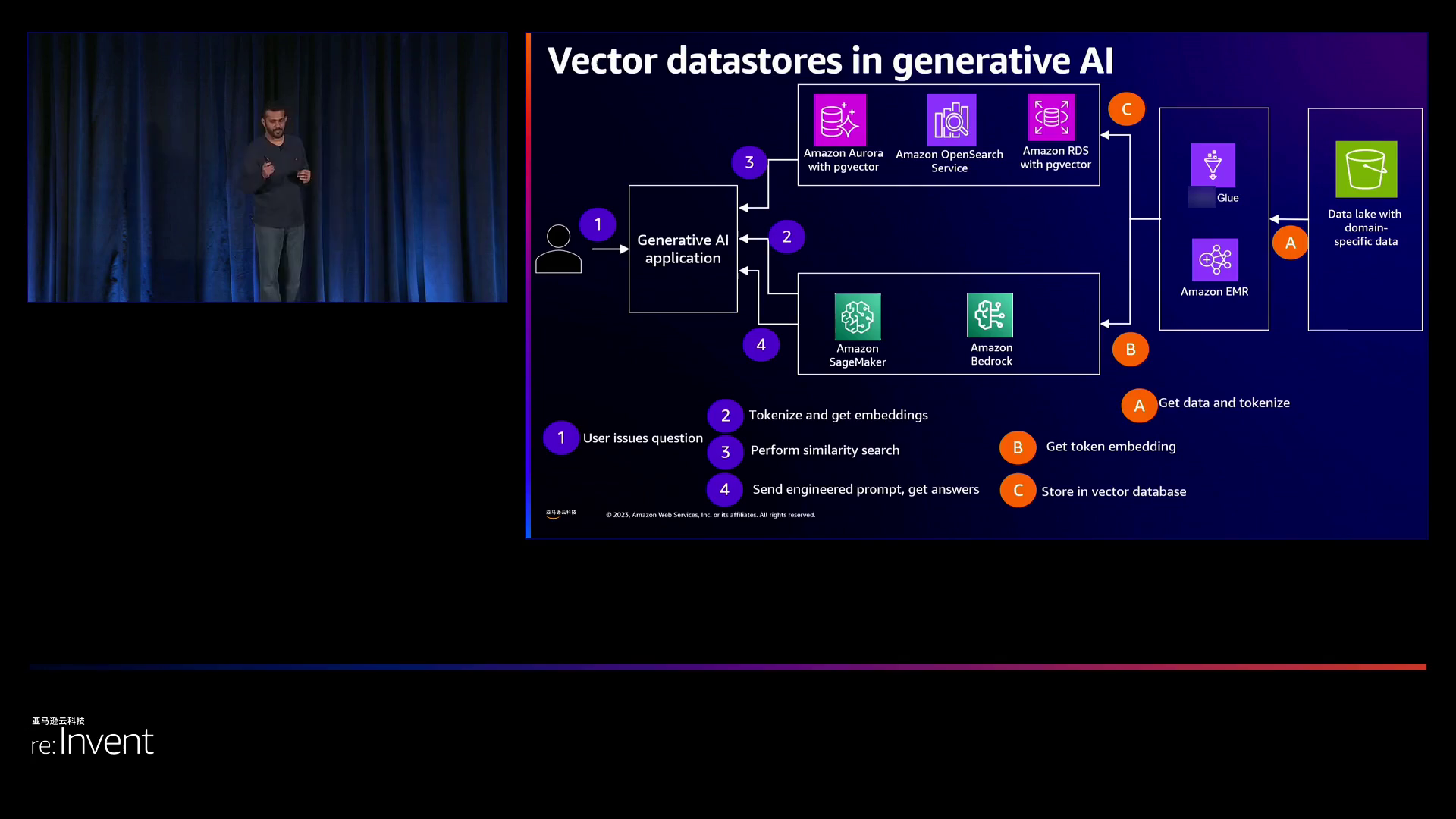
针对生成性AI用例(如自然语言生成),该架构模式重点关注向[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)模型提供存储有PB级数据的相关上下文数据,从而提高准确性。数据在处理和索引方面使用了像[Amazon Aurora](https://aws.amazon.com/cn/rds/aurora/?trk=cndc-detail)或[Amazon OpenSearch Service](https://aws.amazon.com/cn/opensearch-service/?trk=cndc-detail)这样的向量数据库,这些数据库拥有数十亿个向量。在运行过程中,客户问题会被映射到向量,然后从数千亿的比较中查找相似的上下文向量,以扩充输入到ML模型。这使得亚马逊云科技能够为开发、部署和运行基于[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)的对话式应用程序提供一整套解决方案。
总的来说,演讲者强调了亚马逊云科技如何通过提供超过100项管理和兼容的开源服务,共同构建一个端到端的架构,使客户能够在云上构建完整的数据平台。亚马逊云科技在改进开源项目的同时,也抽象了大规模运行它们的复杂性。常见的架构模式利用这些强大的服务来处理流处理、大数据和[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)工作负载。亚马逊云科技的开放源策略强调以客户为中心并与社区紧密合作,以推动分析和[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)生态系统中的创新。
**下面是一些演讲现场的精彩瞬间:**
亚马逊云科技致力于简化开源软件的维护和扩展性,使得这些软件变得更加易于使用。

亚马逊云科技的众多客户已经在使用诸如Backstage、EMR、Druid和Presto等开源平台,通过这些平台在亚马逊云科技上提升了性能并降低了成本。

亚马逊的EMR服务提供了灵活的部署选项,例如基于EC2的EMR,以便优化和定制长期运行的集群。

领导者们强调,亚马逊的MSK服务如何轻松地运行Apache Kafka集群,将亚马逊的经验和最佳实践作为默认选项提供给客户。

用户可以访问一个生成性的应用程序,该应用程序将问题分解成多个元素,查询模型并返回与上下文相关的响应。
演讲者在演讲结束时对观众表示感谢,并邀请他们提出问题。

## 总结
亚马逊云科技运用开源工具协助客户制定全面的数据策略。开源技术带来了透明度、可扩展性和由社区驱动的发展。亚马逊云科技运营诸如Apache Spark和Elasticsearch等开源软件的托管版本,并将成果回馈给这些社区。此外,亚马逊云科技还开发了一些与开源兼容的专有服务,例如Keyspaces和DocumentDB。
对于数据湖,亚马逊建议采用S3存储和Iceberg进行表管理,这两者都是开源的。处理方案包括EMR(一个托管的Spark和Hadoop服务)以及针对Apache Kafka的Amazon Managed Streaming。专为特定目的设计的数据库,如Neptune、Elasticsearch Service和MemoryDB,可以作为数据湖的补充。
亚马逊云科技的Glue数据目录负责元数据和发现的管理,而编排则可以通过Apache Airflow来处理。生成性AI应用利用在特定领域数据上经过微调的大型语言模型。亚马逊云科技提供的向量数据库有助于提高模型的准确性。总之,亚马逊云科技通过基于开源的全栈解决方案,为客户提供安全、可靠的数据策略。
## 演讲原文
## 想了解更多精彩完整内容吗?立即访问re:Invent 官网中文网站!
[2023亚马逊云科技re:Invent全球大会 - 官方网站](https://webinar.amazoncloud.cn/reInvent2023/?s=8739&smid=19458 "2023亚马逊云科技re:Invent全球大会 - 官方网站")
[点击此处](https://aws.amazon.com/cn/new/?trk=6dd7cc20-6afa-4abf-9359-2d6976ff9600&trk=cndc-detail "点击此处"),一键获取亚马逊云科技全球最新产品/服务资讯!
[点击此处](https://www.amazonaws.cn/new/?trk=2ab098aa-0793-48b1-85e6-a9d261bd8cd4&trk=cndc-detail "点击此处"),一键获取亚马逊云科技中国区最新产品/服务资讯!
## 即刻注册亚马逊云科技账户,开启云端之旅!
[【免费】亚马逊云科技“100 余种核心云服务产品免费试用”](https://aws.amazon.com/cn/campaigns/freecenter/?trk=f079813d-3a13-4a50-b67b-e31d930f36a4&sc_channel=el&trk=cndc-detail "【免费】亚马逊云科技“100 余种核心云服务产品免费试用“")
[【免费】亚马逊云科技中国区“40 余种核心云服务产品免费试用”](https://www.amazonaws.cn/campaign/CloudService/?trk=2cdb6245-f491-42bc-b931-c1693fe92be1&sc_channel=el&trk=cndc-detail "【免费】亚马逊云科技中国区“40 余种核心云服务产品免费试用“")
在亚马逊云科技上构建开源数据策略
云计算
re:Invent

 0
0 0
0亚马逊云科技解决方案 基于行业客户应用场景及技术领域的解决方案
联系亚马逊云科技专家
亚马逊云科技解决方案
基于行业客户应用场景及技术领域的解决方案
联系专家

0
目录

 分享
分享 点赞
点赞 收藏
收藏 目录
目录立即注册,开启您的免费套餐
立即关注

亚马逊云开发者
公众号

User Group
公众号

亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
关于我们 
更多资源
开发者工具
更多支持
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
