TiDB 6.5 LTS 版本已经发布了。这是 TiDB V6 的第二个长期支持版,携带了诸多备受期待的新特性:**产品易用性进一步提升、内核不断打磨,更加成熟、多样化的灾备能力、加强应用开发者生态构建**……
TiDB 6.5 新特性解析系列文章由 PingCAP 产研团队重磅打造,从原理分析、技术实现、和产品体验几个层面展示了 6.5 版本的多项功能优化,**旨在帮助读者更简单、更全面的体验 6.5 版本**。
本文为系列文章的第一篇,介绍了 TiFlash 在高并发场景下的稳定性和资源利用率的优化原理。
## 缘起
最近的某天,我们测试 TiFlash 在高并发查询场景下的稳定性时,发现 TiFlash 终于可以长时间稳定将 CPU 完全打满,这意味着我们能充分的利用 CPU 资源。回想一年多前,我们还在为高并发查询下的 OOM(out-of memory)、OOT(out-of thread)、CPU 使用率不高等各种问题而绞尽脑汁。是时候来回顾一下我们做了哪些事情,让量变引起质变。
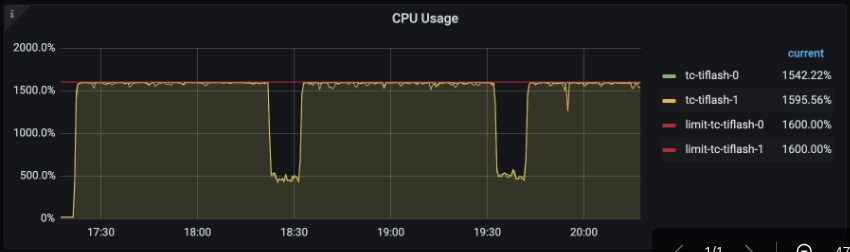
<center>👆 CPU 使用率打满</center>
我们都知道,对于分析型的查询来说,有时候一个请求就能将机器的 CPU 资源打满。所以,大部分 OLAP 系统在设计和实现的时候,很少考虑系统在高查询并发下的表现——早期的 TiFlash 也没在这方面考虑太多。
早期的 TiFlash 的资源管理比较初级——没有高效的线程管理机制、缺少健壮的查询任务调度器、每个查询的内存使用没有任何限制、最新写入的数据存储和管理也有较大优化空间。这些优化措施的缺位,导致早期的 TiFlash 在高并发查询场景下表现不佳,经常无法将 CPU 使用率打满,稍有不慎还可能出现 OOM 或 OOT。
过去一年里,针对 TiFlash 在高并发场景下的稳定性和资源利用率这个问题,我们在存储和计算上都做了不少尝试和努力。如今回头看,有了上面的结果,也算是达到了一个小里程碑。
## DynamicThreadPool
TiFlash 最开始的线程管理非常简单粗暴:请求到来时,按需创建新线程;请求结束之后,自动销毁线程。在这种模式下,我们发现:对于一些逻辑比较复杂,但是数据量不大的查询,无论怎么增加查询的并发,TiFlash 的整机 CPU 使用率都远远不能打满。
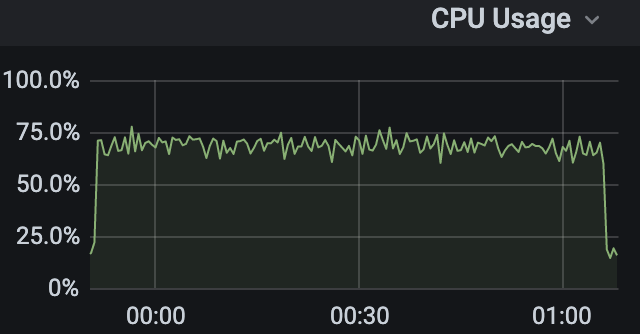
<center>👆 CPU 使用率始终保持在 75% 以下</center>
经过一系列的研究之后,我们终于定位到问题的根本原因:高并发下,TiFlash 会频繁地创建线程和释放线程。在 Linux 内核中,线程在创建和释放的时候,都会抢同一把全局互斥锁,从而在高并发线程创建和释放时, 这些线程会发生排队、阻塞的现象,进而导致应用的计算工作也被阻塞,而且并发越多,这个问题越严重,所以 CPU 使用率不会随着并发增加而增加。具体分析可以参考文章:[深入解析 TiFlash丨多并发下线程创建、释放的阻塞问题](https://cn.pingcap.com/blog/deep-interpreting-of-tiflash?utm_source=wechat&utm_medium=social)。
解决这个问题的直接思路是使用线程池,减少线程创建和释放的频率。但是,我们目前的查询任务使用线程的模式是非抢占的,对于固定大小的线程池,由于系统中没有全局的调度器,会有死锁的风险。为此,我们引入了 DynamicThreadPool 这一特性。
在 DynamicThreadPool 中,线程分为两类:
1. 固定线程:固定数量的线程,生命期与整个线程池相同。
2. 动态线程:运行过程中随着负载升高而创建,会自行在冷却后销毁。
每当有新任务需要执行时,DynamicThreadPool 会按以下顺序查找可用线程:
1. 空闲的固定线程。
2. 空闲的动态线程。
3. 当没有可用线程时,创建新的动态线程服务当前任务。
所有空闲的动态线程会组成一个 LIFO 的链表,每个动态线程在处理完一个任务后都会将自身插入到链表头部,这样下次调度时会被优先使用,从而达到尽可能复用最近使用过的动态线程的目的。链表尾部的动态线程会在超过一个时间阈值没有收到新任务之后判断自身已冷却,自行退出。
## MinTSOScheduler
由于 DynamicThreadPool 没有限制线程的数量,在遇到高并发查询时,TiFlash 仍然有可能会遇到无法分配出线程(OOT)的问题。为了解决此问题,我们必须控制 TiFlash 中同时使用的线程数量。
为了控制同时使用的计算线程数量,同时避免死锁,我们为 TiFlash 引入了名为 MinTSOScheduler 的查询任务调度器——一个完全分布式的调度器,它仅依赖 TiFlash 节点自身的信息。
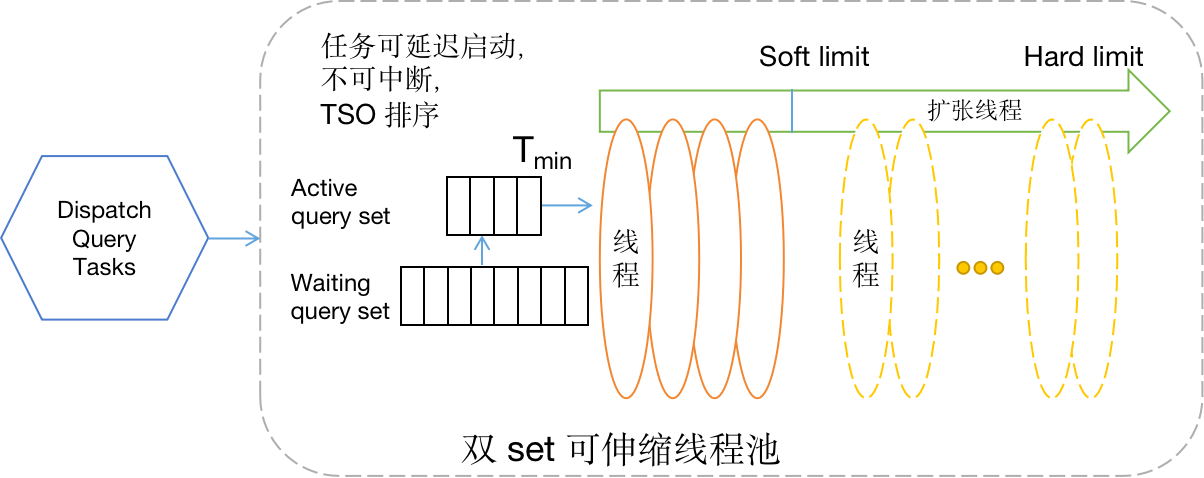
<center>👆 MinTSOScheduler 的基本原理</center>
MinTSOScheduler 的基本原理是:保证 TiFlash 节点上最小的 start_ts 对应的所有 MPPTask 能正常运行。因为全局最小的 start_ts 在各个节点上必然也是最小的 start_ts,所以 MinTSOScheduer 能够保证全局至少有一个查询能顺利运行从而保证整个系统不会有死锁。而对于非最小 start_ts 的 MPPTask,则根据当前系统的线程使用情况来决定是否可以运行,所以也能达到控制系统线程使用量的目的。
## MemoryTracker
DynamicThreadPool 和 MinTSOScheduler 基本上解决了线程频繁创建和销毁、线程使用数量不受控制两大问题。对于一个运行高并发查询的环境,还有一个重要的问题要解决——减少查询之间的相互干扰。
实践中,我们发现最重要的一点就是要避免其中某一个查询忽然消耗掉大量内存,导致整个节点 OOM。为了避免某个大查询导致的 OOM,我们显著增强了 MemoryTracker 跟踪和记录每个 MPPTask 使用的内存的精确度。当内存使用超过限制时,可以强行中止请求,避免 OOM 影响其它请求。
## PageStorage
PageStorage 是 TiFlash 中的一个存储的抽象层,类似对象存储。它主要是为了存储一些较小的数据块,如最新数据和 TiFlash 存储引擎的元数据。所以,PageStorage 主要面向新写入数据的高频读写设计。v6.1 及之前 TiFlash 使用的是 PageStorage 的 v2 版本(简称 PSv2)。
经过一系列的迭代和业务打磨,我们发现 PSv2 存在一些问题亟需改进:
1. 在一些写入负载,特别是 append-only 负载下,容易触发激进的 GC 策略对硬盘数据进行重写。重写数据时引起较大的写放大,以及内存的周期性快速上涨,造成系统不稳定。同时也会挤占前台写入和查询线程 CPU。
2. 在 snapshot 释放时进行内存中的垃圾回收,其中涉及较多内存小对象的拷贝。在高并发写入和查询的场景下,snapshot 释放的过程与读写任务挤占 CPU。
这些问题在大部分写入和查询并发较低的 OLAP 场景下,对系统的影响有限。但是,TiFlash 作为 TiDB 的 HTAP 架构中重要的一环,经常需要面对高并发的写入和查询。为此,我们重新设计并实现了全新的 PageStorage (简称 PSv3)以应对更严苛的 HTAP 负载需求。
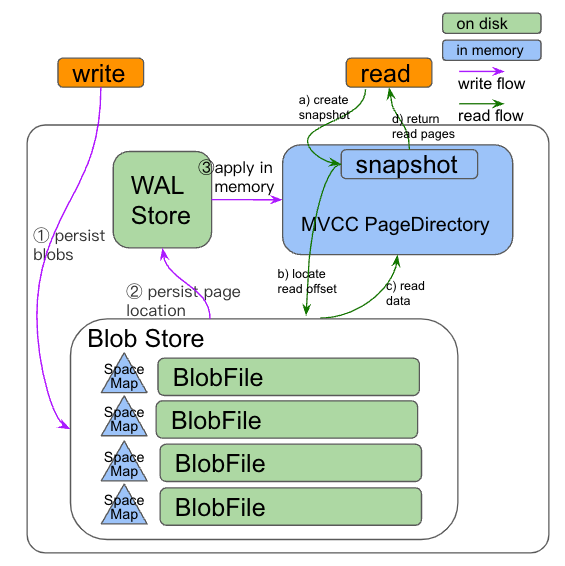
<center>👆 PSv3 架构图</center>
上图是 PSv3 的整体架构。其中,橙色块代表接口,绿色块代表在硬盘上存储的组件,蓝色块代表在内存中的组件。
- WALStore 中维护数据(page)在 BlobFile 中位置,内存中的 PageDirectory 实现了 MVCC 支持。
- 数据保存在 BlobFile 中,如果其中的数据反复重写,会造成 CPU 以及 IO 资源的浪费。我们通过 SpaceMap 记录了 BlobFile 上的数据块使用情况(空闲或占用)。删除数据时,只需要更新一下标记。写入数据时,可以直接从 SpaceMap 查找符合要求的空闲块直接写入。大部分情况下,BlobFile 可以直接复用被删除的空闲数据块,避免数据重写的发生,最大程度地减少了垃圾回收的需求,从而显著减少 CPU 和内存空间使用。
- 由于有 SpaceMap 的存在,写线程在 SpaceMap 中分配好数据块位置之后,多个写线程的 IO 操作可以并发执行。在复用空间时 BlobFile 文件大小不变,可以减少了文件元数据的 sync 操作。TiFlash 整体的写延迟降低,进而减少等待数据一致性的 wait index 阻塞时间,提升查询线程的 CPU 利用率。
- 让读写线程 snapshot 创建和释放时的操作更高效,内存对象的整理的时间从释放 snapshot 时改为在后台线程进行回收,减少了对前台读写任务的影响,从而提升了查询线程的 CPU 利用率。
## 总结
| DynamicThreadPool | MinTSOScheduler | PageStorageV3 | CPU 最大使用率 |
| --- | --- | --- | --- |
| enable | enable | enable | 100% |
| disable | disable | enbale | 75% |
| enable | disable | enable | 90% |
| enable | enable | disable | 75% |
| disable | enable | enable | 85% |
上面这个表格总结了本文介绍的这几个提升 TiFlash 稳定性和 CPU 使用率的关键特性的组合情况,可以看出:
- DynamicThreadPool 解决了频繁创建和销毁线程带来的开销;PageStorage v3 大大降低了 GC 和 snapshot 的开销,提升了高并发写入和查询的稳定性。这两者对提升 CPU 利用率有明显的效果。
- MinTSOScheduler 调度器限制了查询使用线程的数量,避免了出现分配不出线程的情况,可以有效防止高并发请求导致的 OOM、OOT。
- 而 MemoryTracker(内存限制)通过主动 cancel 掉部分请求来防止整个进程 OOM,可以有效避免一个大查询导致整个节点不可用(OOM)的情况发生。
除此之外,过去一年,TiFlash 在性能和功能方面也做了不少优化,感兴趣的朋友可以关注我们的 github 代码和官方文档。以上全部改动可以在 TiDB v6.5 LTS 版本中体验到,欢迎尝试。
TiDB 6.5 新特性解析丨过去一年,我们是如何让 TiFlash 高效又稳定地榨干 CPU?
数据库
开源

 0
0 0
0亚马逊云科技解决方案 基于行业客户应用场景及技术领域的解决方案
联系亚马逊云科技专家
亚马逊云科技解决方案
基于行业客户应用场景及技术领域的解决方案
联系专家

0
目录

 分享
分享 点赞
点赞 收藏
收藏 目录
目录立即注册,开启您的免费套餐
立即关注

亚马逊云开发者
公众号

User Group
公众号

亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
关于我们 
更多资源
开发者工具
更多支持
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
