{"value":"### **December 12th, 2022 - Instalment #138**\n### **Welcome**\n\nWelcome to the AWS open source newsletter, edition #138. After a week off due to re:Invent, this edition is packed with content on many of the open source related announcements. As always, we have a great line up of new projects for you to practice your four freedoms on. In no particular order, we have projects like \"eks-node-viewer\", a nice visualisation tool for your Amazon EKS clusters, \"pg_tle\" a great new project to make your PostgreSQL environments safer, \"dyna53\" a fun project that finally turns Amazon Route 53 into a database, \"dynamodb-mass-migrations\" a tool to help you migrate to Amazon DynamoDB, \"visual-asset-management-system\" a very nice digital asset management tool, \"fast-differential-privacy\" implement differential privacy in your PyTorch models, \"migration-hadoop-to-emr-tco-simulator\" a handy total cost of ownership calculator for Amazon EMR, \"realtime-toxicity-detection\" a tool to help you stay on top of your online communities, \"functionclarity\" a very cool tool to check the integrity of your serverless functions before executing, and many more.\n\nWe also feature this week content on a broad array of open source technologies, such as Rez, Terraform, PostgreSQL, Apache Hudi, Delta Lake, Amazon EMR, Apache Iceberg, Apache Spark, OpenZFS, Ray, MySQL, Kubernetes, Apache Kafka, Open Invention Network, AWS IoT Greengrass, Ray, Modin, Amazon Corretto, Firecracker, DeeQu, AWS SDK for pandas, Amazon Braket, Yocto, Log4shell, MQTT, Redis, and many more. Finally, make sure you check out the Video section, where I share what i think are the best videos from re:Invent on open source.\n\n### **Amazon Joins the Open Invention Network**\n\n++[Open Invention Network (OIN)](https://aws-oss.beachgeek.co.uk/2bl)++ is a company that acquires patents and licenses them royalty-free to its community members who, in turn, agree not to assert their own patents against Linux and Linux-related systems and applications. Announced last week, David Nalley wrote about Amazon joining OIN, and what this means to us. Nithya Ruff also added:\n\n“By joining OIN, we are continuing to strengthen open source communities and helping to ensure technologies like Linux remain thriving and accessible to everyone.”\n\n\n### **Feedback**\n\nPlease let me know how we can improve this newsletter as well as how AWS can better work with open source projects and technologies by completing ++[this very short survey](https://eventbox.dev/survey/NUSZ91Z)++ that will take you probably less than 30 seconds to complete. Thank you so much!\n\n### **Celebrating open source contributors**\n\nThe articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.\n\nSo thank you to the following open source heroes: Donnie Prakoso, Todd Neal, Tyler Lynch, Thomas Roos, Darko Mesaros, Curtis Evans, Ariel Shuper, Channy Yun, Jeff Barr, Álvaro Hernández, Heitor Lessa, Abbey Fuller, Noritaka Sekiyama, Gonzalo Herreros, Mohit Saxena, Abdel Jaidi, Anton Kukushkin, Lucas Hanson, Leon Luttenberger, Zach Mitchell, Ishan Gaur, Kinshuk Pahare, Derek Liu, Pathik Shah and Raj Devnath\n\n### **Latest open source projects**\nThe great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution.\n\n**Tools**\n**pg_tle**\n\n++[pg_tle](https://aws-oss.beachgeek.co.uk/2cf)++ Trusted Language Extensions (TLE) for PostgreSQL (pg_tle) is an open source project that lets developers extend and deploy new PostgreSQL functionality with lower administrative and technical overhead. Developers can use Trusted Language Extensions for PostgreSQL to create and install extensions on restricted filesystems and work with PostgreSQL internals through a SQL API. You can learn more about Trusted Language Extensions in the AWS News blog post, ++[New – Trusted Language Extensions for PostgreSQL on Amazon Aurora and Amazon RDS](https://aws-oss.beachgeek.co.uk/2bh)++ where Channy Yun provides a hands on guide to getting started with this project.\n\n### **eks-node-viewer**\n\n++[eks-node-viewer](https://aws-oss.beachgeek.co.uk/2cq)++ is a tool developed by Todd Neal for visualising dynamic node usage within a cluster. It was originally developed as an internal tool at AWS for demonstrating consolidation with Karpenter. Check out ++[this short video](https://aws-oss.beachgeek.co.uk/2cr)++ from Justin Garrison that looks at this tool running. Hat tip to Tyler Lynch for sharing this with me.\n\n\n\n\n### **functionclarity**\n\n++[functionclarity](https://aws-oss.beachgeek.co.uk/2co)++ is a code integrity solution for serverless functions. It allows users to sign their serverless functions and verify their integrity prior to their execution in their cloud environments. FunctionClarity includes a CLI tool, complemented by a \"verification\" function deployed in the target cloud account. The solution is designed for CI/CD insertion, where the serverless function code/images can be signed and uploaded before the function is created in the cloud repository.\n\n\n\nCheck out this blog post ++[A New Open-Source Tool that Fills a Critical Serverless Security Gap](https://aws-oss.beachgeek.co.uk/2cp)++, where Ariel Shuper looks at this in more detail including how you can get started.\n\n\n### **dyna53**\n\n++[dyna53](https://aws-oss.beachgeek.co.uk/2br)++ a fun project from AWS Hero, Álvaro Hernández, dyna53 is a database (with limited functionality). It is in reality a frontend to another database. The frontend is DynamoDB API compatible. That is, it implements (a limited subset of) the same API that DynamoDB exposes. Therefore it is (should be) compatible with DynamoDB clients and tools. The main goal is to support very basic operations (create table, put item, basic querying capabilities). The backend is AWS Route 53, a DNS service. This is where data is stored and queried from. As Alvaro notes in the README\n\nUsing DNS \"as a database\" is not a novel idea, but the concept of running a database on top of Route 53 has not been explored deep enough.\n\nWhat do you think? Get in touch with Alvaro if you try this out, and let him know what you think.\n\n\n### **dynamodb-mass-migrations**\n\n++[dynamodb-mass-migrations](https://aws-oss.beachgeek.co.uk/2cl)++ this repo provides a tool using AWS Step Functions Distributed Map to run massively parallel DynamoDB migrations in AWS CDK. Thanks to recent accouncement of Step Functions Distributed Map, we can now run 10,000 of parallel executions in Step Functions. This is especially useful for transforming/migrating big datasets in DynamoDB.\n\n\n\n### **aws-kms-xksproxy-api-spec**\n\n++[aws-kms-xksproxy-api-spec](https://aws-oss.beachgeek.co.uk/2cg)++ if you missed the ++[announcement](https://aws-oss.beachgeek.co.uk/2ch)++ at re:Invent, AWS Key Management Service (AWS KMS) introduces the External Key Store (XKS), a new feature for customers who want to protect their data with encryption keys stored in an external key management system under their control. This capability brings new flexibility for customers to encrypt or decrypt data with cryptographic keys, independent authorisation, and audit in an external key management system outside of AWS. This repo contains the specification, an example XKS client and some test clients. There is also a link to the launch blog post to help get you started.\n\n### **visual-asset-management-system**\n\n++[visual-asset-management-system](https://aws-oss.beachgeek.co.uk/2bo)++ VAMS for short, is a purpose-built, AWS native solution for the management and distribution of specialised visual assets used in spatial computing. VAMS offers a simplified solution for organisations to ingest, store, and manage visual assets in the cloud, which empowers any user with a web browser to upload, manage, visualise, transform, and retrieve visual assets. Existing workflows that leverage both custom code and pre-built or third-party applications can also be migrated to VAMS and ran in the AWS cloud, as opposed to being limited by the on-premise capacity available. VAMS is customisable and expandable with option of being further tailored to specific use-cases by development teams.\n\n\n\n\n### **aws-cloud9-auto-root-volume-resize**\n\n++[aws-cloud9-auto-root-volume-resize](https://aws-oss.beachgeek.co.uk/2ca)++ this is a project that I think a lot of folk (including myself, who comes up against this every time I provision a new environment) will find useful. Cloud9 provides a consistent environment for development teams that allows for ease of development by easily integrating with AWS. However, when launching a Cloud9 instance environment, no options are provided that will allow for adjusting the size of the root volume and the environment will launch using the default size of 10 GiB. This limited size can prove cumbersome if teams start development work in the Cloud9 instance environment without realising this storage space is limited without intervention. This solution allows for a near-seamless integration with the existing Cloud9 instance environment launch process but utilising an optional tag (\"cloud9:root_volume_size\") to indicate the desired root volume size in GiB.\n\n### **fast-differential-privacy**\n\n++[fast-differential-privacy](https://aws-oss.beachgeek.co.uk/2cc)++ is a library that allows differentially private optimisation of PyTorch models, with a few additional lines of code. It supports all PyTorch optimisers, popular models in TIMM, torchvision, HuggingFace (up to supported modules), multiple privacy accountants, and multiple clipping functions. The library has provably little overhead in terms of training time and memory cost, compared with the standard non-private optimisation.\n\n### **aws-organizations-alternate-contacts-management-via-csv**\n\n++[aws-organizations-alternate-contacts-management-via-csv](https://aws-oss.beachgeek.co.uk/2ce)++ Nowadays, customers have several linked accounts in their AWS Organizations. These linked accounts might require different alternate contacts for many reasons and keeping such contacts updated is fundamental. Unfortunately, populating such contacts might be a complex and time-consuming activity. Customers would like to fill in their AWS linked accounts alternate contacts in a simple and quick way, closer to their daily way of working, like exporting to a CSV file, modifying it keeping the original formatting, and importing the updated contacts from the management account. This is what the script does. The script leverages on AWS CLI 2.0 and AWS CloudShell to enable the AWS Organizations management account to easily export all the linked accounts alternate contacts to a regular CSV file. Then, the file can be integrated or updated, and uploaded again.\n\n### **migration-hadoop-to-emr-tco-simulator**\n\n++[migration-hadoop-to-emr-tco-simulator](https://aws-oss.beachgeek.co.uk/2cj)++ this repo provides you with help if you are looking to move off self managed Hadoop, and migrate onto a managed service like Amazon EMR. This tool may be useful when examining and estimating the cost of migration, so well worth checking out.\n\n\n\n\n### **aws-medialive-channel-orchestrator**\n\n++[aws-medialive-channel-orchestrator](https://aws-oss.beachgeek.co.uk/2cm)++ this repository contains sample code to deploy a web app that can be used to simplify the management of AWS MediaLive Channels. Supported functionality includes starting/stopping channels, input switching, motion graphic overlays, and much more. If you use AWS MediaLive Channels, then this repo is something you should check out.\n\n\n\n\n\n### **amazon-gamelift-testing-toolkit**\n\n++[amazon-gamelift-testing-toolkit](https://aws-oss.beachgeek.co.uk/2cn)++ this repo provides a test harness and visualisation tool for Amazon GameLift and Amazon GameLift FlexMatch. The toolkit lets you visualise your GameLift infrastructure, launch virtual players, and iterate upon your FlexMatch rule sets with the FlexMatch simulator. Detailed docs show you how to deploy and use this project.\n\n\n\n\n\n## **Demos, Samples, Solutions and Workshops**\n### **aws-music-genre-classification**\n\n++[aws-music-genre-classification](https://aws-oss.beachgeek.co.uk/2cd)++ is a Jupyter Notebook that connects to the Registry of Open Data on AWS to show music genre classification. You can run this locally or use AWS SageMaker Studio Lab (this does not require an AWS account)\n\n### **realtime-toxicity-detection**\n\n++[realtime-toxicity-detection](https://aws-oss.beachgeek.co.uk/2ci)++ this repository contains a complete solution for detecting toxicity across voice and text chats, cost efficiently and at scale, in near real time. It makes use of a number of AWS services, including Amazon SageMaker, Amazon Cognito, AWS Lambda, AWS Amplify, and Amazon Transcribe.\n\n\n\n### **msk-powered-financial-data-feed**\n\n++[msk-powered-financial-data-feed](https://aws-oss.beachgeek.co.uk/2cb)++ this sample application demonstrates how to publish a real-time financial data feed as a service on AWS. It contains the code for a data provider to send streaming data to its clients via an Amazon MSK cluster. Clients can consume the data using a Kafka client SDK. Detailed instructions on how to get this setup are provided in the README, as well as plenty of examples in the EXAMPLES folder.\n\n### **aws-to-azure-bgp-vpn**\n\n++[aws-to-azure-bgp-vpn](https://aws-oss.beachgeek.co.uk/2bn)++ this Terraform module allows you to configure a BGP VPN Gateway between AWS and Microsoft Azure. Check the docs for requirements and constraints, but if you are looking to build networking across Clouds, this is going to be of interest.\n\n### **terraform-eksblueprints-tetrate-istio-addon**\n\n++[terraform-eksblueprints-tetrate-istio-addon](https://aws-oss.beachgeek.co.uk/2bj)++ provides sample code on how you can deploy Istio and Envoy into your Amazon EKS environments. To help you along the way, check out ++[Automate Istio-Enabled Amazon EKS Cluster Deployment with Tetrate’s EKS Blueprints Add-On](https://aws-oss.beachgeek.co.uk/2bk)++\n\n\n\n\n\n## **AWS and Community blog posts**\n### **Apache Spark**\n\nCloud Shuffle Storage Plugin for Apache Spark, is a new open source project under the Apache 2.0 license that allows you to independently scale storage in your Spark jobs without adding additional workers. With this plugin, you can expect jobs processing terabytes of data to run much more reliably. You can download the binaries and run them on any Spark environment. The new plugin is open-cloud, comes with out-of-the box support for Amazon S3, and can be easily configured to use other forms of cloud storage such as Google Cloud Storage and Microsoft Azure Blob Storage.\n\nTo find out more, check out this must read post, ++[Introducing the Cloud Shuffle Storage Plugin for Apache Spark](https://aws-oss.beachgeek.co.uk/2bt)++ where Noritaka Sekiyama, Gonzalo Herreros, and Mohit Saxena help get you started. [hands on]\n\n\n\n\n### **DeeQu**\n\nA hot topic over the past 12 months that I have been hearing in various data communities is that around data quality. ++[Deequ](https://aws-oss.beachgeek.co.uk/2bu)++ is an open source library built on top of Apache Spark for defining \"unit tests for data\". Built on top of the open-source DeeQu framework, ++[AWS Glue Data Quality](https://aws-oss.beachgeek.co.uk/2bv)++ provides a managed, serverless experience to help you evaluate and monitor the quality of your data when you use AWS Glue 3.0. To find out more on how to get started, check out Jeff Barr's excellent post on the topic, ++[Join the Preview – AWS Glue Data Quality](https://aws-oss.beachgeek.co.uk/2bw)++ [hands on]\n\n\n\n\n### **AWS Lambda Snapstart**\n\nOne of the biggest announcements during re:Invent was that of AWS Lambda SnapStart, a new performance optimisation developed by AWS that can significantly improve the startup time for applications. This feature delivers up to 10x faster function startup times for latency-sensitive Java applications. SnapStart is made possible by several pieces of open-source work, including Firecracker, Linux, CraC, OpenSSL and more. It is always interesting to see how these open source building blocks are combined to create great innovations like this. Dive deeper by reading the post, ++[Starting up faster with AWS Lambda SnapStart](https://aws-oss.beachgeek.co.uk/2by)++ on what those open source projects are and how they combine to make this all work. [deep dive]\n\n\n\n### **Amazon Security Lake**\n\nLaunched earlier this year, the ++[Open Cybersecurity Schema Framework](https://aws-oss.beachgeek.co.uk/2c1)++ is an open-source project, delivering an extensible framework for developing schemas, along with a vendor-agnostic core security schema. Amazon Security Lake is a purpose-built service that supports data in this format, and automatically centralises an organisation’s security data from cloud and on-premises sources into a purpose-built data lake stored in your account. To find out more, check out ++[Preview: Amazon Security Lake – A Purpose-Built Customer-Owned Data Lake Service](https://aws-oss.beachgeek.co.uk/2c2)++ where Channy Yun looks closer at OCSF and Amazon Security Lake. [hands on]\n\n\n\n\n### **AWS SDK for pandas**\n\nAWS SDK for pandas is an open-source library that extends the popular Python pandas library, enabling you to connect to AWS data and analytics services using pandas data frames. I love this project, and use it frequently in my demos. At re:Invent, it was announced that AWS SDK for pandas now supports Ray and Modin, enabling you to scale your pandas workflows from a single machine to a multi-node environment, with no code changes. Check out the blog post, ++[Scale AWS SDK for pandas workloads with AWS Glue for Ray](https://aws-oss.beachgeek.co.uk/2c4)++ where Abdel Jaidi, Anton Kukushkin, Lucas Hanson, and Leon Luttenberger walk you through this update [hands on]\n\n\n\n\n### **Ray**\n\nRay is an open-source unified compute framework that makes it simple to scale AI and Python workloads. In this post, ++[Introducing AWS Glue for Ray: Scaling your data integration workloads using Python](https://aws-oss.beachgeek.co.uk/2c5)++ Zach Mitchell, Ishan Gaur, Kinshuk Pahare, and Derek Liu provide an introduction to AWS Glue for Ray and shows you how to start using Ray to distribute your Python workloads. [hands on]\n\n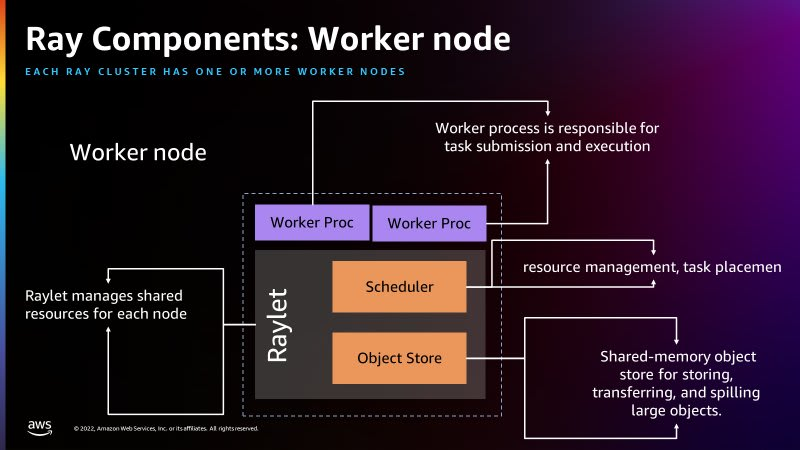\n\n### **Other posts and quick reads**\n\n- ++[Managing Docker container lifecycle with AWS IoT Greengrass](https://aws-oss.beachgeek.co.uk/2bf)++ an interesting way on how to use AWS IoT Greengrass to control a Docker container’s lifecycle, using the AWS IoT Core MQTT topic and uses the message contents to execute commands against the Docker daemon with the Docker SDK for Python [hands on]\n\n\n\n- [Gain visibility into your Amazon MSK cluster by deploying the Conduktor Platform](https://aws-oss.beachgeek.co.uk/2bg)++ looks at how you can use Conduktor to help you solve Apache Kafka issues end to end with solutions for testing, monitoring, data quality, governance, and security [hands on]\n- ++[Managing Pod Security on Amazon EKS with Kyverno](https://aws-oss.beachgeek.co.uk/2c8)++ shows you how you can augment the Kubernetes Pod Security Admission (PSA) and Pod Security Standards(PSS) configurations with Kyverno [hands on]\n- ++[Managing access to Amazon Elastic Kubernetes Service clusters with X.509 certificates](https://aws-oss.beachgeek.co.uk/2bp)++ is walk through on how to use X.509 certificates as the root of trust for obtaining temporary AWS credentials to access resources in the Amazon EKS Cluster [hands on]\n\n\n\n- ++[AWS Thinkbox Deadline adds support for Rez](https://aws-oss.beachgeek.co.uk/2bq)++ looks at Rez, an open source, cross-platform package manager, and how the deep integration into AWS Thinkbox Deadline allows customers to build dynamically resolved pipelines that can be executed in an identical way on their render farm, whether that be on-premises or in the cloud\n\n\n\n\n- ++[New for Amazon Redshift – General Availability of Streaming Ingestion for Kinesis Data Streams and Managed Streaming for Apache Kafka](https://aws-oss.beachgeek.co.uk/2bz)++ looks at how you can now natively ingest hundreds of megabytes of data per second from Apache Kafka (Amazon MSK) into an Amazon Redshift materialised view and query it in seconds [hands on]\n- ++[Simplify managing access to Amazon ElastiCache for Redis clusters with IAM shows you how to use your IAM](https://aws-oss.beachgeek.co.uk/2c0)++ identity to authenticate and access an ElastiCache for Redis cluster [hands on]\n\n\n\n\n- ++[Introducing the Amazon Braket Algorithm Library](https://aws-oss.beachgeek.co.uk/2c3)++ walks you through this open-source, GitHub repository providing researchers ready-to-use Python implementations for a set of quantum algorithms on Amazon Braket\n\n\n\n- ++[Introducing new MQTTv5 features for AWS IoT Core to help build flexible architecture patterns](https://aws-oss.beachgeek.co.uk/2c7)++ looks at how AWS IoT Core support of MQTTv5 features help enhance communications of large-scale device deployments and innovate device messaging patterns [hands on]\n\n\n\n- ++[Use AWS CDK v2 with the AWS Amplify CLI extensibility features (Preview)](https://aws-oss.beachgeek.co.uk/2c9)++ shows you how with v11.0.0-beta of the Amplify CLI, you can now use AWS CDK v2 to extend or modify your Amplify backend stack [hands on]\n\n## **Quick updates**\n### **terraform-provider-aws**\n\nThis popular Terraform module now enables you to configure and deploy AWS Neptune Global clusters. You can view the ++[release notes here.](https://aws-oss.beachgeek.co.uk/2bm)++\n\n### **Apache Hudi, Apache Iceberg, Delta Lake**\n\nAWS Glue for Apache Spark now supports three open source data lake storage frameworks: Apache Hudi, Apache Iceberg, and Linux Foundation Delta Lake. These frameworks allow you to read and write data in Amazon Simple Storage Service (Amazon S3) in a transactionally consistent manner. AWS Glue is a serverless, scalable data integration service that makes it easier to discover, prepare, move, and integrate data from multiple sources. This feature removes the need to install a separate connector and reduces the configuration steps required to use these frameworks in AWS Glue for Apache Spark jobs.\n\nThese open source data lake frameworks simplify incremental data processing in data lakes built on Amazon S3. They enable capabilities including time travel queries, ACID (Atomicity, Consistency, Isolation, Durability) transactions, streaming ingestion, change data capture (CDC), upserts, and deletes.\n\n\n### **Amazon EMR**\n\nWith Amazon EMR release 6.8, you can now use Amazon Elastic Compute Cloud (Amazon EC2) instances such as C6i, M6i, I4i, R6i, and R6id, which use the third-generation Intel Xeon scalable processors. Using these new instances with Amazon EMR improves cost-performance by an additional 5–33% over previous generation instances. To dive deeper into this, check out the blog post, ++[Amazon EMR launches support for Amazon EC2 C6i, M6i, I4i, R6i and R6id instances to improve cost performance for Spark workloads by 6–33%](https://aws-oss.beachgeek.co.uk/2bi)++\n\n### **Apache Iceberg**\n\nAmazon SageMaker Feature Store now supports the ability to create feature groups in the offline store in Apache Iceberg table format. The offline store contains historical ML features, organised into logical feature groups, and is used for model training and batch inference. Apache Iceberg is an open table format for very large analytic datasets such as the offline store. It manages large collections of files as tables and supports modern analytical data lake operations optimised for usage on Amazon S3.\n\nIngesting data, especially when streaming, can result in a large number of small files which can negatively impact query performance due the higher number of file operations required. With Iceberg you can compact the small data files into fewer large files in the partition, resulting in significantly faster queries. This compaction operation is concurrent and does not affect ongoing read and write operations on the feature group. If you chose the Iceberg option when creating new feature groups, SageMaker Feature Store will create the Iceberg tables using Parquet file format, and register the tables with the AWS Glue Data Catalog.\n\n\n### **Apache Spark**\n\nAmazon Athena now supports Apache Spark, a popular open-source distributed processing system that is optimised for fast analytics workloads against data of any size. Athena is an interactive query service that helps you query petabytes of data wherever it lives, such as in data lakes, databases, or other data stores. With Amazon Athena for Apache Spark, you get the streamlined, interactive, serverless experience of Athena with Spark, in addition to SQL. You can build interactive Apache PySpark applications using a simplified notebook experience in the Athena console or through Athena APIs. With Athena, interactive Spark applications start in under a second and run faster with our optimised Spark runtime, so you spend more time on insights, not waiting for results. As Athena takes care of managing the infrastructure and configuring Spark settings, you can focus on your business applications.\n\nDive deeper into this launch by reading the post, ++[Explore your data lake using Amazon Athena for Apache Spark](https://aws-oss.beachgeek.co.uk/2bs)++ where Pathik Shah and Raj Devnath show how you can use Athena for Apache Spark to explore and derive insights from your data lake hosted on Amazon Simple Storage Service (Amazon S3).\n\n\n\n\nMy fellow Developer Advocate Donnie Prakoso also put something together, so check out his post, ++[New — Amazon Athena for Apache Spark](https://aws-oss.beachgeek.co.uk/2bx)++ where he shows you how you can get started.\n\n\n\n\nAmazon EMR announces Amazon Redshift integration with Apache Spark. This integration helps data engineers build and run Spark applications that can consume and write data from an Amazon Redshift cluster. Starting with Amazon EMR 6.9, this integration is available across all three deployment models for EMR - EC2, EKS, and Serverless. You can use this integration to build applications that directly write to Redshift tables as a part of your ETL workflows or to combine data in Redshift with data in other source. Developers can load data from Redshift tables to Spark data frames or write data to Redshift tables. Developers don’t have to worry about downloading open source connectors to connect to Redshift.\n\n### **OpenZFS**\n\nAmazon FSx for OpenZFS now offers a new generation of file systems that doubles the maximum throughput and IOPS performance of the existing generation and includes a high-speed NVMe cache.\n\nAmazon FSx for OpenZFS provides fully managed, cost-effective, shared file storage powered by the popular OpenZFS file system. The new generation of FSx for OpenZFS file systems provides two performance improvements over the existing generation. First, new-generation file systems deliver up to 350,000 IOPS and 10 GB/s throughput for both reads and writes to persistent SSD storage. Second, they include up to 2.5 TB of high-speed NVMe storage that automatically caches your most recently-accessed data, making that data accessible at over a million of IOPS and with latencies of a few hundred microseconds. With these new-generation file systems, you can power an even broader range of high-performance workloads like media processing/rendering, financial analytics, and machine learning with simple, highly-performant NFS-accessible storage.\n\n\n### **Ray**\n\nAWS Glue for Ray is a new engine option on AWS Glue. Data engineers can use AWS Glue for Ray to process large datasets with Python and popular Python libraries. AWS Glue is a serverless, scalable data integration service used to discover, prepare, move, and integrate data from multiple sources. AWS Glue for Ray combines that serverless option for data integration with Ray (ray.io), a popular new open-source compute framework that helps you scale Python workloads.\n\n\nYou pay only for the resources that you use while running code, and you don’t need to configure or tune any resources. AWS Glue for Ray facilitates the distributed processing of your Python code over multi-node clusters. You can create and run Ray jobs anywhere that you run AWS Glue ETL (extract, transform, and load) jobs. This includes existing AWS Glue jobs, command line interfaces (CLIs), and APIs. You can select the Ray engine through notebooks on AWS Glue Studio, Amazon SageMaker Studio Notebook, or locally. When the Ray job is ready, you can run it on demand or on a schedule.\n\n### **MySQL**\n\nA couple of updates for MySQL users, that should make you happy. Improvements on both READ and WRITES of data.\n\nAmazon Relational Database Service (Amazon RDS) for MySQL now supports Amazon RDS Optimized Reads for up to 50% faster query processing compared to previous generation instances. Optimized Read-enabled instances achieve faster query processing by placing temporary tables generated by MySQL on the local NVMe-based SSD block-level storage that’s physically connected to the host server. Complex queries that utilize temporary tables, such as queries involving sorts, hash aggregations, high-load joins, and Common Table Expressions (CTEs) can now execute up to 50% faster with Optimized Reads on RDS for MySQL.\n\nAmazon RDS Optimized Reads is available by default on RDS for MySQL versions 8.0.28 and higher on Intel-based M5d and R5d instances and AWS Graviton2-based M6gd and R6gd database (DB) instances. R5d and M5d DB instances provide up to 3,600 GiB of NVMe SSD-based instance storage for low latency, high random I/O and sequential read throughput. M6gd and R6gd DB instances are built on the AWS Nitro System, and provide up to 3,800 GiB of NVMe-based SSD storage and up to 25 Gbps of network bandwidth. Amazon RDS Optimized Reads for Amazon RDS for MySQL is available today on M5d, R5d, M6gd, and R6gd instances in the same AWS Regions where these instances are available.\t\n\n\nAmazon Relational Database Service (Amazon RDS) for MySQL now supports Amazon RDS Optimized Writes. With Optimized Writes you can improve write throughput by up to 2x at no additional cost. This is especially useful for RDS for MySQL customers with write-intensive database workloads, commonly found in applications such as digital payments, financial trading, and online gaming.\n\nIn MySQL, you are protected from data loss due to unexpected events, such as a power failure, using a built-in feature called the “doublewrite buffer”. But this method of writing takes up to twice as long, consumes twice as much I/O bandwidth, and reduces the throughput and performance of your database. Starting today, Amazon RDS Optimized Writes provide you with up to 2x improvement in write transaction throughput on RDS for MySQL by writing only once while protecting you from data loss and at no additional cost. Optimized Writes uses the AWS Nitro System, to reliably and durably write to table storage in one step. Amazon RDS Optimized Writes is available as a default option from RDS for MySQL version 8.0.30 and above and on db.r6i and db.r5b database instances.\n\nYou can dive deeper by checking out Jeff Barr's post, ++[New – Amazon RDS Optimized Reads and Optimized Writes](https://aws-oss.beachgeek.co.uk/2c6)++\n\n\n### **Videos of the week**\n### **AWS Lambda Powertools**\n\nHeitor Lessa provided one of the best and most eagerly anticipated sessions at re:Invent, AWS Lambda Powertools: Lessons from the road to 10 million downloads. In this session, Heitor talked about the current state of Lambda Powertools, how this growth was supported, key lessons learned in the past two years, and what’s next on the horizon.\n\n\n<video src=\"https://dev-media.amazoncloud.cn/9ef009786879427dae22d8842fd86e8c_AWS%20re%EF%BC%9AInvent%202022%20-%20AWS%20Lambda%20Powertools%EF%BC%9A%20Lessons%20from%20the%20road%20to%2010%20million%20downloads%20%28OPN306%29.mp4\" class=\"manvaVedio\" controls=\"controls\" style=\"width:160px;height:160px\"></video>\n\n### **Log4Shell**\n\nThis was my top recommendation for re:Invent attendees, and I am super happy that the video is already available for everyone to watch. Abbey Fuller is your speaker, and you will learn about the response to Log4Shell, from initial notification to hot patch, fleet scanning, and customer communications.\n\n<video src=\"https://dev-media.amazoncloud.cn/6796e06b3b51412aa9db05ad2cb88af8_AWS%20re%EF%BC%9AInvent%202022%20-%20When%20security%2C%20safety%2C%20and%20urgency%20all%20matter%EF%BC%9A%20Handling%20Log4Shell%20%28BOA204%29.mp4\" class=\"manvaVedio\" controls=\"controls\" style=\"width:160px;height:160px\"></video>\n\n\n### **Open Source tools on AWS**\n\nDarko Mesaros and Curtis Evans have a look at open-source tools that can help make your AWS adventure easier. See something for security and permissions, something for cost management, and a few more things for building in the cloud—tools like Infracost, IAMLive, and more.\n\n\n<video src=\"https://dev-media.amazoncloud.cn/657feb155fd44d5b997e246be2652b9a_AWS%20re%EF%BC%9AInvent%202022%20-%20Take%20these%20open-source%20tools%20on%20your%20AWS%20adventure%20%28BOA202%29.mp4\" class=\"manvaVedio\" controls=\"controls\" style=\"width:160px;height:160px\"></video>\n\n### **Yocto**\n\nBitBake is a make-like build tool with the special focus of distributions and packages for embedded Linux cross compilation. Manually upgrading bitbake recipes often and testing them is time-consuming. Thomas Roos talks about our approach to automate the Yocto layer maintenance of meta-aws with cloud managed services technologies. Maintenance means upgrading software versions, testing, committing bitbake recipes and back porting of changes from master to release branches. You can also call it CI/CD for Yocto layers.\n\n<video src=\"https://dev-media.amazoncloud.cn/2e922c3dc49542a6aa481bdd2ff26be5_Automate%20Yocto%20layer%20maintenance%20with%20cloud%20managed%20services%2C%20Thomas%20Roos.mp4\" class=\"manvaVedio\" controls=\"controls\" style=\"width:160px;height:160px\"></video>\n\n### **Build on Open Source**\n\nFor those unfamiliar with this show, Build on Open Source is where we go over this newsletter and then invite special guests to dive deep into their open source project. Expect plenty of code, demos and hopefully laughs. We have put together a playlist so that you can easily access all (seven) of the other episodes of the Build on Open Source show. ++[Build on Open Source playlist](https://aws-oss.beachgeek.co.uk/24u)++\n\n## **Events for your diary**\n### **OpenSearch**\n### **Every other Tuesday, 3pm GMT**\n\nThis regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.\n\nSign up to the next session, ++[OpenSearch Community Meeting](https://aws-oss.beachgeek.co.uk/1az)++\n\n### **Stay in touch with open source at AWS**\nI hope this summary has been useful. Remember to check out the ++[Open Source homepage](https://aws.amazon.com/opensource/?opensource-all.sort-by=item.additionalFields.startDate&opensource-all.sort-order=asc)++ to keep up to date with all our activity in open source by following us on ++[@AWSOpen](https://twitter.com/AWSOpen)++\n\n\n\n","render":"<h3><a id=\"December_12th_2022__Instalment_138_0\"></a><strong>December 12th, 2022 - Instalment #138</strong></h3>\n<h3><a id=\"Welcome_1\"></a><strong>Welcome</strong></h3>\n<p>Welcome to the AWS open source newsletter, edition #138. After a week off due to re:Invent, this edition is packed with content on many of the open source related announcements. As always, we have a great line up of new projects for you to practice your four freedoms on. In no particular order, we have projects like “eks-node-viewer”, a nice visualisation tool for your Amazon EKS clusters, “pg_tle” a great new project to make your PostgreSQL environments safer, “dyna53” a fun project that finally turns Amazon Route 53 into a database, “dynamodb-mass-migrations” a tool to help you migrate to Amazon DynamoDB, “visual-asset-management-system” a very nice digital asset management tool, “fast-differential-privacy” implement differential privacy in your PyTorch models, “migration-hadoop-to-emr-tco-simulator” a handy total cost of ownership calculator for Amazon EMR, “realtime-toxicity-detection” a tool to help you stay on top of your online communities, “functionclarity” a very cool tool to check the integrity of your serverless functions before executing, and many more.</p>\n<p>We also feature this week content on a broad array of open source technologies, such as Rez, Terraform, PostgreSQL, Apache Hudi, Delta Lake, Amazon EMR, Apache Iceberg, Apache Spark, OpenZFS, Ray, MySQL, Kubernetes, Apache Kafka, Open Invention Network, AWS IoT Greengrass, Ray, Modin, Amazon Corretto, Firecracker, DeeQu, AWS SDK for pandas, Amazon Braket, Yocto, Log4shell, MQTT, Redis, and many more. Finally, make sure you check out the Video section, where I share what i think are the best videos from re:Invent on open source.</p>\n<h3><a id=\"Amazon_Joins_the_Open_Invention_Network_7\"></a><strong>Amazon Joins the Open Invention Network</strong></h3>\n<p><ins><a href=\"https://aws-oss.beachgeek.co.uk/2bl\" target=\"_blank\">Open Invention Network (OIN)</a></ins> is a company that acquires patents and licenses them royalty-free to its community members who, in turn, agree not to assert their own patents against Linux and Linux-related systems and applications. Announced last week, David Nalley wrote about Amazon joining OIN, and what this means to us. Nithya Ruff also added:</p>\n<p>“By joining OIN, we are continuing to strengthen open source communities and helping to ensure technologies like Linux remain thriving and accessible to everyone.”</p>\n<h3><a id=\"Feedback_14\"></a><strong>Feedback</strong></h3>\n<p>Please let me know how we can improve this newsletter as well as how AWS can better work with open source projects and technologies by completing <ins><a href=\"https://eventbox.dev/survey/NUSZ91Z\" target=\"_blank\">this very short survey</a></ins> that will take you probably less than 30 seconds to complete. Thank you so much!</p>\n<h3><a id=\"Celebrating_open_source_contributors_18\"></a><strong>Celebrating open source contributors</strong></h3>\n<p>The articles and projects shared in this newsletter are only possible thanks to the many contributors in open source. I would like to shout out and thank those folks who really do power open source and enable us all to learn and build on top of what they have created.</p>\n<p>So thank you to the following open source heroes: Donnie Prakoso, Todd Neal, Tyler Lynch, Thomas Roos, Darko Mesaros, Curtis Evans, Ariel Shuper, Channy Yun, Jeff Barr, Álvaro Hernández, Heitor Lessa, Abbey Fuller, Noritaka Sekiyama, Gonzalo Herreros, Mohit Saxena, Abdel Jaidi, Anton Kukushkin, Lucas Hanson, Leon Luttenberger, Zach Mitchell, Ishan Gaur, Kinshuk Pahare, Derek Liu, Pathik Shah and Raj Devnath</p>\n<h3><a id=\"Latest_open_source_projects_24\"></a><strong>Latest open source projects</strong></h3>\n<p>The great thing about open source projects is that you can review the source code. If you like the look of these projects, make sure you that take a look at the code, and if it is useful to you, get in touch with the maintainer to provide feedback, suggestions or even submit a contribution.</p>\n<p><strong>Tools</strong><br />\n<strong>pg_tle</strong></p>\n<p><ins><a href=\"https://aws-oss.beachgeek.co.uk/2cf\" target=\"_blank\">pg_tle</a></ins> Trusted Language Extensions (TLE) for PostgreSQL (pg_tle) is an open source project that lets developers extend and deploy new PostgreSQL functionality with lower administrative and technical overhead. Developers can use Trusted Language Extensions for PostgreSQL to create and install extensions on restricted filesystems and work with PostgreSQL internals through a SQL API. You can learn more about Trusted Language Extensions in the AWS News blog post, <ins><a href=\"https://aws-oss.beachgeek.co.uk/2bh\" target=\"_blank\">New – Trusted Language Extensions for PostgreSQL on Amazon Aurora and Amazon RDS</a></ins> where Channy Yun provides a hands on guide to getting started with this project.</p>\n<h3><a id=\"eksnodeviewer_32\"></a><strong>eks-node-viewer</strong></h3>\n<p><ins><a href=\"https://aws-oss.beachgeek.co.uk/2cq\" target=\"_blank\">eks-node-viewer</a></ins> is a tool developed by Todd Neal for visualising dynamic node usage within a cluster. It was originally developed as an internal tool at AWS for demonstrating consolidation with Karpenter. Check out <ins><a href=\"https://aws-oss.beachgeek.co.uk/2cr\" target=\"_blank\">this short video</a></ins> from Justin Garrison that looks at this tool running. Hat tip to Tyler Lynch for sharing this with me.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/900dfb99a50f434498b6e80270322de0_image.png\" alt=\"image.png\" /></p>\n<h3><a id=\"functionclarity_39\"></a><strong>functionclarity</strong></h3>\n<p><ins><a href=\"https://aws-oss.beachgeek.co.uk/2co\" target=\"_blank\">functionclarity</a></ins> is a code integrity solution for serverless functions. It allows users to sign their serverless functions and verify their integrity prior to their execution in their cloud environments. FunctionClarity includes a CLI tool, complemented by a “verification” function deployed in the target cloud account. The solution is designed for CI/CD insertion, where the serverless function code/images can be signed and uploaded before the function is created in the cloud repository.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/65b9a89ac69c40e6aaf3bec1b4ec1560_image.png\" alt=\"image.png\" /></p>\n<p>Check out this blog post <ins><a href=\"https://aws-oss.beachgeek.co.uk/2cp\" target=\"_blank\">A New Open-Source Tool that Fills a Critical Serverless Security Gap</a></ins>, where Ariel Shuper looks at this in more detail including how you can get started.</p>\n<h3><a id=\"dyna53_48\"></a><strong>dyna53</strong></h3>\n<p><ins><a href=\"https://aws-oss.beachgeek.co.uk/2br\" target=\"_blank\">dyna53</a></ins> a fun project from AWS Hero, Álvaro Hernández, dyna53 is a database (with limited functionality). It is in reality a frontend to another database. The frontend is DynamoDB API compatible. That is, it implements (a limited subset of) the same API that DynamoDB exposes. Therefore it is (should be) compatible with DynamoDB clients and tools. The main goal is to support very basic operations (create table, put item, basic querying capabilities). The backend is AWS Route 53, a DNS service. This is where data is stored and queried from. As Alvaro notes in the README</p>\n<p>Using DNS “as a database” is not a novel idea, but the concept of running a database on top of Route 53 has not been explored deep enough.</p>\n<p>What do you think? Get in touch with Alvaro if you try this out, and let him know what you think.</p>\n<h3><a id=\"dynamodbmassmigrations_57\"></a><strong>dynamodb-mass-migrations</strong></h3>\n<p><ins><a href=\"https://aws-oss.beachgeek.co.uk/2cl\" target=\"_blank\">dynamodb-mass-migrations</a></ins> this repo provides a tool using AWS Step Functions Distributed Map to run massively parallel DynamoDB migrations in AWS CDK. Thanks to recent accouncement of Step Functions Distributed Map, we can now run 10,000 of parallel executions in Step Functions. This is especially useful for transforming/migrating big datasets in DynamoDB.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/5654153901aa4b6b805514816b3a9725_image.png\" alt=\"image.png\" /></p>\n<h3><a id=\"awskmsxksproxyapispec_63\"></a><strong>aws-kms-xksproxy-api-spec</strong></h3>\n<p><ins><a href=\"https://aws-oss.beachgeek.co.uk/2cg\" target=\"_blank\">aws-kms-xksproxy-api-spec</a></ins> if you missed the <ins><a href=\"https://aws-oss.beachgeek.co.uk/2ch\" target=\"_blank\">announcement</a></ins> at re:Invent, AWS Key Management Service (AWS KMS) introduces the External Key Store (XKS), a new feature for customers who want to protect their data with encryption keys stored in an external key management system under their control. This capability brings new flexibility for customers to encrypt or decrypt data with cryptographic keys, independent authorisation, and audit in an external key management system outside of AWS. This repo contains the specification, an example XKS client and some test clients. There is also a link to the launch blog post to help get you started.</p>\n<h3><a id=\"visualassetmanagementsystem_67\"></a><strong>visual-asset-management-system</strong></h3>\n<p><ins><a href=\"https://aws-oss.beachgeek.co.uk/2bo\" target=\"_blank\">visual-asset-management-system</a></ins> VAMS for short, is a purpose-built, AWS native solution for the management and distribution of specialised visual assets used in spatial computing. VAMS offers a simplified solution for organisations to ingest, store, and manage visual assets in the cloud, which empowers any user with a web browser to upload, manage, visualise, transform, and retrieve visual assets. Existing workflows that leverage both custom code and pre-built or third-party applications can also be migrated to VAMS and ran in the AWS cloud, as opposed to being limited by the on-premise capacity available. VAMS is customisable and expandable with option of being further tailored to specific use-cases by development teams.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/925153413dc94e01aa4e2df81f33c677_image.png\" alt=\"image.png\" /></p>\n<h3><a id=\"awscloud9autorootvolumeresize_74\"></a><strong>aws-cloud9-auto-root-volume-resize</strong></h3>\n<p><ins><a href=\"https://aws-oss.beachgeek.co.uk/2ca\" target=\"_blank\">aws-cloud9-auto-root-volume-resize</a></ins> this is a project that I think a lot of folk (including myself, who comes up against this every time I provision a new environment) will find useful. Cloud9 provides a consistent environment for development teams that allows for ease of development by easily integrating with AWS. However, when launching a Cloud9 instance environment, no options are provided that will allow for adjusting the size of the root volume and the environment will launch using the default size of 10 GiB. This limited size can prove cumbersome if teams start development work in the Cloud9 instance environment without realising this storage space is limited without intervention. This solution allows for a near-seamless integration with the existing Cloud9 instance environment launch process but utilising an optional tag (“cloud9:root_volume_size”) to indicate the desired root volume size in GiB.</p>\n<h3><a id=\"fastdifferentialprivacy_78\"></a><strong>fast-differential-privacy</strong></h3>\n<p><ins><a href=\"https://aws-oss.beachgeek.co.uk/2cc\" target=\"_blank\">fast-differential-privacy</a></ins> is a library that allows differentially private optimisation of PyTorch models, with a few additional lines of code. It supports all PyTorch optimisers, popular models in TIMM, torchvision, HuggingFace (up to supported modules), multiple privacy accountants, and multiple clipping functions. The library has provably little overhead in terms of training time and memory cost, compared with the standard non-private optimisation.</p>\n<h3><a id=\"awsorganizationsalternatecontactsmanagementviacsv_82\"></a><strong>aws-organizations-alternate-contacts-management-via-csv</strong></h3>\n<p><ins><a href=\"https://aws-oss.beachgeek.co.uk/2ce\" target=\"_blank\">aws-organizations-alternate-contacts-management-via-csv</a></ins> Nowadays, customers have several linked accounts in their AWS Organizations. These linked accounts might require different alternate contacts for many reasons and keeping such contacts updated is fundamental. Unfortunately, populating such contacts might be a complex and time-consuming activity. Customers would like to fill in their AWS linked accounts alternate contacts in a simple and quick way, closer to their daily way of working, like exporting to a CSV file, modifying it keeping the original formatting, and importing the updated contacts from the management account. This is what the script does. The script leverages on AWS CLI 2.0 and AWS CloudShell to enable the AWS Organizations management account to easily export all the linked accounts alternate contacts to a regular CSV file. Then, the file can be integrated or updated, and uploaded again.</p>\n<h3><a id=\"migrationhadooptoemrtcosimulator_86\"></a><strong>migration-hadoop-to-emr-tco-simulator</strong></h3>\n<p><ins><a href=\"https://aws-oss.beachgeek.co.uk/2cj\" target=\"_blank\">migration-hadoop-to-emr-tco-simulator</a></ins> this repo provides you with help if you are looking to move off self managed Hadoop, and migrate onto a managed service like Amazon EMR. This tool may be useful when examining and estimating the cost of migration, so well worth checking out.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/53fda28210b84e9ebac5307bdc8331cc_image.png\" alt=\"image.png\" /></p>\n<h3><a id=\"awsmedialivechannelorchestrator_93\"></a><strong>aws-medialive-channel-orchestrator</strong></h3>\n<p><ins><a href=\"https://aws-oss.beachgeek.co.uk/2cm\" target=\"_blank\">aws-medialive-channel-orchestrator</a></ins> this repository contains sample code to deploy a web app that can be used to simplify the management of AWS MediaLive Channels. Supported functionality includes starting/stopping channels, input switching, motion graphic overlays, and much more. If you use AWS MediaLive Channels, then this repo is something you should check out.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/3eb2d78bfade454e927edd2b695aeef2_image.png\" alt=\"image.png\" /></p>\n<h3><a id=\"amazongamelifttestingtoolkit_101\"></a><strong>amazon-gamelift-testing-toolkit</strong></h3>\n<p><ins><a href=\"https://aws-oss.beachgeek.co.uk/2cn\" target=\"_blank\">amazon-gamelift-testing-toolkit</a></ins> this repo provides a test harness and visualisation tool for Amazon GameLift and Amazon GameLift FlexMatch. The toolkit lets you visualise your GameLift infrastructure, launch virtual players, and iterate upon your FlexMatch rule sets with the FlexMatch simulator. Detailed docs show you how to deploy and use this project.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/07d99adf953544d3bfd6bcf0494d3740_image.png\" alt=\"image.png\" /></p>\n<h2><a id=\"Demos_Samples_Solutions_and_Workshops_109\"></a><strong>Demos, Samples, Solutions and Workshops</strong></h2>\n<h3><a id=\"awsmusicgenreclassification_110\"></a><strong>aws-music-genre-classification</strong></h3>\n<p><ins><a href=\"https://aws-oss.beachgeek.co.uk/2cd\" target=\"_blank\">aws-music-genre-classification</a></ins> is a Jupyter Notebook that connects to the Registry of Open Data on AWS to show music genre classification. You can run this locally or use AWS SageMaker Studio Lab (this does not require an AWS account)</p>\n<h3><a id=\"realtimetoxicitydetection_114\"></a><strong>realtime-toxicity-detection</strong></h3>\n<p><ins><a href=\"https://aws-oss.beachgeek.co.uk/2ci\" target=\"_blank\">realtime-toxicity-detection</a></ins> this repository contains a complete solution for detecting toxicity across voice and text chats, cost efficiently and at scale, in near real time. It makes use of a number of AWS services, including Amazon SageMaker, Amazon Cognito, AWS Lambda, AWS Amplify, and Amazon Transcribe.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/6b5436ba6858424daf153e4f3e9593dd_image.png\" alt=\"image.png\" /></p>\n<h3><a id=\"mskpoweredfinancialdatafeed_120\"></a><strong>msk-powered-financial-data-feed</strong></h3>\n<p><ins><a href=\"https://aws-oss.beachgeek.co.uk/2cb\" target=\"_blank\">msk-powered-financial-data-feed</a></ins> this sample application demonstrates how to publish a real-time financial data feed as a service on AWS. It contains the code for a data provider to send streaming data to its clients via an Amazon MSK cluster. Clients can consume the data using a Kafka client SDK. Detailed instructions on how to get this setup are provided in the README, as well as plenty of examples in the EXAMPLES folder.</p>\n<h3><a id=\"awstoazurebgpvpn_124\"></a><strong>aws-to-azure-bgp-vpn</strong></h3>\n<p><ins><a href=\"https://aws-oss.beachgeek.co.uk/2bn\" target=\"_blank\">aws-to-azure-bgp-vpn</a></ins> this Terraform module allows you to configure a BGP VPN Gateway between AWS and Microsoft Azure. Check the docs for requirements and constraints, but if you are looking to build networking across Clouds, this is going to be of interest.</p>\n<h3><a id=\"terraformeksblueprintstetrateistioaddon_128\"></a><strong>terraform-eksblueprints-tetrate-istio-addon</strong></h3>\n<p><ins><a href=\"https://aws-oss.beachgeek.co.uk/2bj\" target=\"_blank\">terraform-eksblueprints-tetrate-istio-addon</a></ins> provides sample code on how you can deploy Istio and Envoy into your Amazon EKS environments. To help you along the way, check out <ins><a href=\"https://aws-oss.beachgeek.co.uk/2bk\" target=\"_blank\">Automate Istio-Enabled Amazon EKS Cluster Deployment with Tetrate’s EKS Blueprints Add-On</a></ins></p>\n<p><img src=\"https://dev-media.amazoncloud.cn/1c5bfe6e0bce43849809b2bc75e36ec1_image.png\" alt=\"image.png\" /></p>\n<h2><a id=\"AWS_and_Community_blog_posts_136\"></a><strong>AWS and Community blog posts</strong></h2>\n<h3><a id=\"Apache_Spark_137\"></a><strong>Apache Spark</strong></h3>\n<p>Cloud Shuffle Storage Plugin for Apache Spark, is a new open source project under the Apache 2.0 license that allows you to independently scale storage in your Spark jobs without adding additional workers. With this plugin, you can expect jobs processing terabytes of data to run much more reliably. You can download the binaries and run them on any Spark environment. The new plugin is open-cloud, comes with out-of-the box support for Amazon S3, and can be easily configured to use other forms of cloud storage such as Google Cloud Storage and Microsoft Azure Blob Storage.</p>\n<p>To find out more, check out this must read post, <ins><a href=\"https://aws-oss.beachgeek.co.uk/2bt\" target=\"_blank\">Introducing the Cloud Shuffle Storage Plugin for Apache Spark</a></ins> where Noritaka Sekiyama, Gonzalo Herreros, and Mohit Saxena help get you started. [hands on]</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/34cf768647224596a557fd52e9f28406_image.png\" alt=\"image.png\" /></p>\n<h3><a id=\"DeeQu_146\"></a><strong>DeeQu</strong></h3>\n<p>A hot topic over the past 12 months that I have been hearing in various data communities is that around data quality. <ins><a href=\"https://aws-oss.beachgeek.co.uk/2bu\" target=\"_blank\">Deequ</a></ins> is an open source library built on top of Apache Spark for defining “unit tests for data”. Built on top of the open-source DeeQu framework, <ins><a href=\"https://aws-oss.beachgeek.co.uk/2bv\" target=\"_blank\">AWS Glue Data Quality</a></ins> provides a managed, serverless experience to help you evaluate and monitor the quality of your data when you use AWS Glue 3.0. To find out more on how to get started, check out Jeff Barr’s excellent post on the topic, <ins><a href=\"https://aws-oss.beachgeek.co.uk/2bw\" target=\"_blank\">Join the Preview – AWS Glue Data Quality</a></ins> [hands on]</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/8800d94b8fc44194bbbf39b7347f3c12_image.png\" alt=\"image.png\" /></p>\n<h3><a id=\"AWS_Lambda_Snapstart_153\"></a><strong>AWS Lambda Snapstart</strong></h3>\n<p>One of the biggest announcements during re:Invent was that of AWS Lambda SnapStart, a new performance optimisation developed by AWS that can significantly improve the startup time for applications. This feature delivers up to 10x faster function startup times for latency-sensitive Java applications. SnapStart is made possible by several pieces of open-source work, including Firecracker, Linux, CraC, OpenSSL and more. It is always interesting to see how these open source building blocks are combined to create great innovations like this. Dive deeper by reading the post, <ins><a href=\"https://aws-oss.beachgeek.co.uk/2by\" target=\"_blank\">Starting up faster with AWS Lambda SnapStart</a></ins> on what those open source projects are and how they combine to make this all work. [deep dive]</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/cd8c9a3db4e749ea81c1326d19a63028_image.png\" alt=\"image.png\" /></p>\n<h3><a id=\"Amazon_Security_Lake_159\"></a><strong>Amazon Security Lake</strong></h3>\n<p>Launched earlier this year, the <ins><a href=\"https://aws-oss.beachgeek.co.uk/2c1\" target=\"_blank\">Open Cybersecurity Schema Framework</a></ins> is an open-source project, delivering an extensible framework for developing schemas, along with a vendor-agnostic core security schema. Amazon Security Lake is a purpose-built service that supports data in this format, and automatically centralises an organisation’s security data from cloud and on-premises sources into a purpose-built data lake stored in your account. To find out more, check out <ins><a href=\"https://aws-oss.beachgeek.co.uk/2c2\" target=\"_blank\">Preview: Amazon Security Lake – A Purpose-Built Customer-Owned Data Lake Service</a></ins> where Channy Yun looks closer at OCSF and Amazon Security Lake. [hands on]</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/9253ae60e75840deab34724c938551a0_image.png\" alt=\"image.png\" /></p>\n<h3><a id=\"AWS_SDK_for_pandas_166\"></a><strong>AWS SDK for pandas</strong></h3>\n<p>AWS SDK for pandas is an open-source library that extends the popular Python pandas library, enabling you to connect to AWS data and analytics services using pandas data frames. I love this project, and use it frequently in my demos. At re:Invent, it was announced that AWS SDK for pandas now supports Ray and Modin, enabling you to scale your pandas workflows from a single machine to a multi-node environment, with no code changes. Check out the blog post, <ins><a href=\"https://aws-oss.beachgeek.co.uk/2c4\" target=\"_blank\">Scale AWS SDK for pandas workloads with AWS Glue for Ray</a></ins> where Abdel Jaidi, Anton Kukushkin, Lucas Hanson, and Leon Luttenberger walk you through this update [hands on]</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/bd0eddc173b740a8aa28d6ed46e119ee_image.png\" alt=\"image.png\" /></p>\n<h3><a id=\"Ray_173\"></a><strong>Ray</strong></h3>\n<p>Ray is an open-source unified compute framework that makes it simple to scale AI and Python workloads. In this post, <ins><a href=\"https://aws-oss.beachgeek.co.uk/2c5\" target=\"_blank\">Introducing AWS Glue for Ray: Scaling your data integration workloads using Python</a></ins> Zach Mitchell, Ishan Gaur, Kinshuk Pahare, and Derek Liu provide an introduction to AWS Glue for Ray and shows you how to start using Ray to distribute your Python workloads. [hands on]</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/1c0601df755344f6949dd44e2ebfbb84_image.png\" alt=\"image.png\" /></p>\n<h3><a id=\"Other_posts_and_quick_reads_179\"></a><strong>Other posts and quick reads</strong></h3>\n<ul>\n<li><ins><a href=\"https://aws-oss.beachgeek.co.uk/2bf\" target=\"_blank\">Managing Docker container lifecycle with AWS IoT Greengrass</a></ins> an interesting way on how to use AWS IoT Greengrass to control a Docker container’s lifecycle, using the AWS IoT Core MQTT topic and uses the message contents to execute commands against the Docker daemon with the Docker SDK for Python [hands on]</li>\n</ul>\n<p><img src=\"https://dev-media.amazoncloud.cn/2cbdbdd881cc4959b6562edfc4cbd6ef_image.png\" alt=\"image.png\" /></p>\n<ul>\n<li><a href=\"https://aws-oss.beachgeek.co.uk/2bg\" target=\"_blank\">Gain visibility into your Amazon MSK cluster by deploying the Conduktor Platform</a>++ looks at how you can use Conduktor to help you solve Apache Kafka issues end to end with solutions for testing, monitoring, data quality, governance, and security [hands on]</li>\n<li><ins><a href=\"https://aws-oss.beachgeek.co.uk/2c8\" target=\"_blank\">Managing Pod Security on Amazon EKS with Kyverno</a></ins> shows you how you can augment the Kubernetes Pod Security Admission (PSA) and Pod Security Standards(PSS) configurations with Kyverno [hands on]</li>\n<li><ins><a href=\"https://aws-oss.beachgeek.co.uk/2bp\" target=\"_blank\">Managing access to Amazon Elastic Kubernetes Service clusters with X.509 certificates</a></ins> is walk through on how to use X.509 certificates as the root of trust for obtaining temporary AWS credentials to access resources in the Amazon EKS Cluster [hands on]</li>\n</ul>\n<p><img src=\"https://dev-media.amazoncloud.cn/df4f4f0be3ce447fa1c29907216712de_image.png\" alt=\"image.png\" /></p>\n<ul>\n<li><ins><a href=\"https://aws-oss.beachgeek.co.uk/2bq\" target=\"_blank\">AWS Thinkbox Deadline adds support for Rez</a></ins> looks at Rez, an open source, cross-platform package manager, and how the deep integration into AWS Thinkbox Deadline allows customers to build dynamically resolved pipelines that can be executed in an identical way on their render farm, whether that be on-premises or in the cloud</li>\n</ul>\n<p><img src=\"https://dev-media.amazoncloud.cn/db23199641ad47bf9673d2bf2c80ffb0_image.png\" alt=\"image.png\" /></p>\n<ul>\n<li><ins><a href=\"https://aws-oss.beachgeek.co.uk/2bz\" target=\"_blank\">New for Amazon Redshift – General Availability of Streaming Ingestion for Kinesis Data Streams and Managed Streaming for Apache Kafka</a></ins> looks at how you can now natively ingest hundreds of megabytes of data per second from Apache Kafka (Amazon MSK) into an Amazon Redshift materialised view and query it in seconds [hands on]</li>\n<li><ins><a href=\"https://aws-oss.beachgeek.co.uk/2c0\" target=\"_blank\">Simplify managing access to Amazon ElastiCache for Redis clusters with IAM shows you how to use your IAM</a></ins> identity to authenticate and access an ElastiCache for Redis cluster [hands on]</li>\n</ul>\n<p><img src=\"https://dev-media.amazoncloud.cn/967f158647144b0ab844ddfa62422c11_image.png\" alt=\"image.png\" /></p>\n<ul>\n<li><ins><a href=\"https://aws-oss.beachgeek.co.uk/2c3\" target=\"_blank\">Introducing the Amazon Braket Algorithm Library</a></ins> walks you through this open-source, GitHub repository providing researchers ready-to-use Python implementations for a set of quantum algorithms on Amazon Braket</li>\n</ul>\n<p><img src=\"https://dev-media.amazoncloud.cn/7b56657e79584daa994ebbb3726daeaf_image.png\" alt=\"image.png\" /></p>\n<ul>\n<li><ins><a href=\"https://aws-oss.beachgeek.co.uk/2c7\" target=\"_blank\">Introducing new MQTTv5 features for AWS IoT Core to help build flexible architecture patterns</a></ins> looks at how AWS IoT Core support of MQTTv5 features help enhance communications of large-scale device deployments and innovate device messaging patterns [hands on]</li>\n</ul>\n<p><img src=\"https://dev-media.amazoncloud.cn/5736b4598ff943b7a3f3d84b85fcab37_image.png\" alt=\"image.png\" /></p>\n<ul>\n<li><ins><a href=\"https://aws-oss.beachgeek.co.uk/2c9\" target=\"_blank\">Use AWS CDK v2 with the AWS Amplify CLI extensibility features (Preview)</a></ins> shows you how with v11.0.0-beta of the Amplify CLI, you can now use AWS CDK v2 to extend or modify your Amplify backend stack [hands on]</li>\n</ul>\n<h2><a id=\"Quick_updates_212\"></a><strong>Quick updates</strong></h2>\n<h3><a id=\"terraformprovideraws_213\"></a><strong>terraform-provider-aws</strong></h3>\n<p>This popular Terraform module now enables you to configure and deploy AWS Neptune Global clusters. You can view the <ins><a href=\"https://aws-oss.beachgeek.co.uk/2bm\" target=\"_blank\">release notes here.</a></ins></p>\n<h3><a id=\"Apache_Hudi_Apache_Iceberg_Delta_Lake_217\"></a><strong>Apache Hudi, Apache Iceberg, Delta Lake</strong></h3>\n<p>AWS Glue for Apache Spark now supports three open source data lake storage frameworks: Apache Hudi, Apache Iceberg, and Linux Foundation Delta Lake. These frameworks allow you to read and write data in Amazon Simple Storage Service (Amazon S3) in a transactionally consistent manner. AWS Glue is a serverless, scalable data integration service that makes it easier to discover, prepare, move, and integrate data from multiple sources. This feature removes the need to install a separate connector and reduces the configuration steps required to use these frameworks in AWS Glue for Apache Spark jobs.</p>\n<p>These open source data lake frameworks simplify incremental data processing in data lakes built on Amazon S3. They enable capabilities including time travel queries, ACID (Atomicity, Consistency, Isolation, Durability) transactions, streaming ingestion, change data capture (CDC), upserts, and deletes.</p>\n<h3><a id=\"Amazon_EMR_224\"></a><strong>Amazon EMR</strong></h3>\n<p>With Amazon EMR release 6.8, you can now use Amazon Elastic Compute Cloud (Amazon EC2) instances such as C6i, M6i, I4i, R6i, and R6id, which use the third-generation Intel Xeon scalable processors. Using these new instances with Amazon EMR improves cost-performance by an additional 5–33% over previous generation instances. To dive deeper into this, check out the blog post, <ins><a href=\"https://aws-oss.beachgeek.co.uk/2bi\" target=\"_blank\">Amazon EMR launches support for Amazon EC2 C6i, M6i, I4i, R6i and R6id instances to improve cost performance for Spark workloads by 6–33%</a></ins></p>\n<h3><a id=\"Apache_Iceberg_228\"></a><strong>Apache Iceberg</strong></h3>\n<p>Amazon SageMaker Feature Store now supports the ability to create feature groups in the offline store in Apache Iceberg table format. The offline store contains historical ML features, organised into logical feature groups, and is used for model training and batch inference. Apache Iceberg is an open table format for very large analytic datasets such as the offline store. It manages large collections of files as tables and supports modern analytical data lake operations optimised for usage on Amazon S3.</p>\n<p>Ingesting data, especially when streaming, can result in a large number of small files which can negatively impact query performance due the higher number of file operations required. With Iceberg you can compact the small data files into fewer large files in the partition, resulting in significantly faster queries. This compaction operation is concurrent and does not affect ongoing read and write operations on the feature group. If you chose the Iceberg option when creating new feature groups, SageMaker Feature Store will create the Iceberg tables using Parquet file format, and register the tables with the AWS Glue Data Catalog.</p>\n<h3><a id=\"Apache_Spark_235\"></a><strong>Apache Spark</strong></h3>\n<p>Amazon Athena now supports Apache Spark, a popular open-source distributed processing system that is optimised for fast analytics workloads against data of any size. Athena is an interactive query service that helps you query petabytes of data wherever it lives, such as in data lakes, databases, or other data stores. With Amazon Athena for Apache Spark, you get the streamlined, interactive, serverless experience of Athena with Spark, in addition to SQL. You can build interactive Apache PySpark applications using a simplified notebook experience in the Athena console or through Athena APIs. With Athena, interactive Spark applications start in under a second and run faster with our optimised Spark runtime, so you spend more time on insights, not waiting for results. As Athena takes care of managing the infrastructure and configuring Spark settings, you can focus on your business applications.</p>\n<p>Dive deeper into this launch by reading the post, <ins><a href=\"https://aws-oss.beachgeek.co.uk/2bs\" target=\"_blank\">Explore your data lake using Amazon Athena for Apache Spark</a></ins> where Pathik Shah and Raj Devnath show how you can use Athena for Apache Spark to explore and derive insights from your data lake hosted on Amazon Simple Storage Service (Amazon S3).</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/1847c451799247f995e75380680f975d_image.png\" alt=\"image.png\" /></p>\n<p>My fellow Developer Advocate Donnie Prakoso also put something together, so check out his post, <ins><a href=\"https://aws-oss.beachgeek.co.uk/2bx\" target=\"_blank\">New — Amazon Athena for Apache Spark</a></ins> where he shows you how you can get started.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/4bda70516ff54c129997194304e49fe8_Kepler-0.gif\" alt=\"Kepler0.gif\" /></p>\n<p>Amazon EMR announces Amazon Redshift integration with Apache Spark. This integration helps data engineers build and run Spark applications that can consume and write data from an Amazon Redshift cluster. Starting with Amazon EMR 6.9, this integration is available across all three deployment models for EMR - EC2, EKS, and Serverless. You can use this integration to build applications that directly write to Redshift tables as a part of your ETL workflows or to combine data in Redshift with data in other source. Developers can load data from Redshift tables to Spark data frames or write data to Redshift tables. Developers don’t have to worry about downloading open source connectors to connect to Redshift.</p>\n<h3><a id=\"OpenZFS_251\"></a><strong>OpenZFS</strong></h3>\n<p>Amazon FSx for OpenZFS now offers a new generation of file systems that doubles the maximum throughput and IOPS performance of the existing generation and includes a high-speed NVMe cache.</p>\n<p>Amazon FSx for OpenZFS provides fully managed, cost-effective, shared file storage powered by the popular OpenZFS file system. The new generation of FSx for OpenZFS file systems provides two performance improvements over the existing generation. First, new-generation file systems deliver up to 350,000 IOPS and 10 GB/s throughput for both reads and writes to persistent SSD storage. Second, they include up to 2.5 TB of high-speed NVMe storage that automatically caches your most recently-accessed data, making that data accessible at over a million of IOPS and with latencies of a few hundred microseconds. With these new-generation file systems, you can power an even broader range of high-performance workloads like media processing/rendering, financial analytics, and machine learning with simple, highly-performant NFS-accessible storage.</p>\n<h3><a id=\"Ray_258\"></a><strong>Ray</strong></h3>\n<p>AWS Glue for Ray is a new engine option on AWS Glue. Data engineers can use AWS Glue for Ray to process large datasets with Python and popular Python libraries. AWS Glue is a serverless, scalable data integration service used to discover, prepare, move, and integrate data from multiple sources. AWS Glue for Ray combines that serverless option for data integration with Ray (ray.io), a popular new open-source compute framework that helps you scale Python workloads.</p>\n<p>You pay only for the resources that you use while running code, and you don’t need to configure or tune any resources. AWS Glue for Ray facilitates the distributed processing of your Python code over multi-node clusters. You can create and run Ray jobs anywhere that you run AWS Glue ETL (extract, transform, and load) jobs. This includes existing AWS Glue jobs, command line interfaces (CLIs), and APIs. You can select the Ray engine through notebooks on AWS Glue Studio, Amazon SageMaker Studio Notebook, or locally. When the Ray job is ready, you can run it on demand or on a schedule.</p>\n<h3><a id=\"MySQL_265\"></a><strong>MySQL</strong></h3>\n<p>A couple of updates for MySQL users, that should make you happy. Improvements on both READ and WRITES of data.</p>\n<p>Amazon Relational Database Service (Amazon RDS) for MySQL now supports Amazon RDS Optimized Reads for up to 50% faster query processing compared to previous generation instances. Optimized Read-enabled instances achieve faster query processing by placing temporary tables generated by MySQL on the local NVMe-based SSD block-level storage that’s physically connected to the host server. Complex queries that utilize temporary tables, such as queries involving sorts, hash aggregations, high-load joins, and Common Table Expressions (CTEs) can now execute up to 50% faster with Optimized Reads on RDS for MySQL.</p>\n<p>Amazon RDS Optimized Reads is available by default on RDS for MySQL versions 8.0.28 and higher on Intel-based M5d and R5d instances and AWS Graviton2-based M6gd and R6gd database (DB) instances. R5d and M5d DB instances provide up to 3,600 GiB of NVMe SSD-based instance storage for low latency, high random I/O and sequential read throughput. M6gd and R6gd DB instances are built on the AWS Nitro System, and provide up to 3,800 GiB of NVMe-based SSD storage and up to 25 Gbps of network bandwidth. Amazon RDS Optimized Reads for Amazon RDS for MySQL is available today on M5d, R5d, M6gd, and R6gd instances in the same AWS Regions where these instances are available.</p>\n<p>Amazon Relational Database Service (Amazon RDS) for MySQL now supports Amazon RDS Optimized Writes. With Optimized Writes you can improve write throughput by up to 2x at no additional cost. This is especially useful for RDS for MySQL customers with write-intensive database workloads, commonly found in applications such as digital payments, financial trading, and online gaming.</p>\n<p>In MySQL, you are protected from data loss due to unexpected events, such as a power failure, using a built-in feature called the “doublewrite buffer”. But this method of writing takes up to twice as long, consumes twice as much I/O bandwidth, and reduces the throughput and performance of your database. Starting today, Amazon RDS Optimized Writes provide you with up to 2x improvement in write transaction throughput on RDS for MySQL by writing only once while protecting you from data loss and at no additional cost. Optimized Writes uses the AWS Nitro System, to reliably and durably write to table storage in one step. Amazon RDS Optimized Writes is available as a default option from RDS for MySQL version 8.0.30 and above and on db.r6i and db.r5b database instances.</p>\n<p>You can dive deeper by checking out Jeff Barr’s post, <ins><a href=\"https://aws-oss.beachgeek.co.uk/2c6\" target=\"_blank\">New – Amazon RDS Optimized Reads and Optimized Writes</a></ins></p>\n<h3><a id=\"Videos_of_the_week_281\"></a><strong>Videos of the week</strong></h3>\n<h3><a id=\"AWS_Lambda_Powertools_282\"></a><strong>AWS Lambda Powertools</strong></h3>\n<p>Heitor Lessa provided one of the best and most eagerly anticipated sessions at re:Invent, AWS Lambda Powertools: Lessons from the road to 10 million downloads. In this session, Heitor talked about the current state of Lambda Powertools, how this growth was supported, key lessons learned in the past two years, and what’s next on the horizon.</p>\n<p><video src=\"https://dev-media.amazoncloud.cn/9ef009786879427dae22d8842fd86e8c_AWS%20re%EF%BC%9AInvent%202022%20-%20AWS%20Lambda%20Powertools%EF%BC%9A%20Lessons%20from%20the%20road%20to%2010%20million%20downloads%20%28OPN306%29.mp4\" controls=\"controls\"></video></p>\n<h3><a id=\"Log4Shell_289\"></a><strong>Log4Shell</strong></h3>\n<p>This was my top recommendation for re:Invent attendees, and I am super happy that the video is already available for everyone to watch. Abbey Fuller is your speaker, and you will learn about the response to Log4Shell, from initial notification to hot patch, fleet scanning, and customer communications.</p>\n<p><video src=\"https://dev-media.amazoncloud.cn/6796e06b3b51412aa9db05ad2cb88af8_AWS%20re%EF%BC%9AInvent%202022%20-%20When%20security%2C%20safety%2C%20and%20urgency%20all%20matter%EF%BC%9A%20Handling%20Log4Shell%20%28BOA204%29.mp4\" controls=\"controls\"></video></p>\n<h3><a id=\"Open_Source_tools_on_AWS_296\"></a><strong>Open Source tools on AWS</strong></h3>\n<p>Darko Mesaros and Curtis Evans have a look at open-source tools that can help make your AWS adventure easier. See something for security and permissions, something for cost management, and a few more things for building in the cloud—tools like Infracost, IAMLive, and more.</p>\n<p><video src=\"https://dev-media.amazoncloud.cn/657feb155fd44d5b997e246be2652b9a_AWS%20re%EF%BC%9AInvent%202022%20-%20Take%20these%20open-source%20tools%20on%20your%20AWS%20adventure%20%28BOA202%29.mp4\" controls=\"controls\"></video></p>\n<h3><a id=\"Yocto_303\"></a><strong>Yocto</strong></h3>\n<p>BitBake is a make-like build tool with the special focus of distributions and packages for embedded Linux cross compilation. Manually upgrading bitbake recipes often and testing them is time-consuming. Thomas Roos talks about our approach to automate the Yocto layer maintenance of meta-aws with cloud managed services technologies. Maintenance means upgrading software versions, testing, committing bitbake recipes and back porting of changes from master to release branches. You can also call it CI/CD for Yocto layers.</p>\n<p><video src=\"https://dev-media.amazoncloud.cn/2e922c3dc49542a6aa481bdd2ff26be5_Automate%20Yocto%20layer%20maintenance%20with%20cloud%20managed%20services%2C%20Thomas%20Roos.mp4\" controls=\"controls\"></video></p>\n<h3><a id=\"Build_on_Open_Source_309\"></a><strong>Build on Open Source</strong></h3>\n<p>For those unfamiliar with this show, Build on Open Source is where we go over this newsletter and then invite special guests to dive deep into their open source project. Expect plenty of code, demos and hopefully laughs. We have put together a playlist so that you can easily access all (seven) of the other episodes of the Build on Open Source show. <ins><a href=\"https://aws-oss.beachgeek.co.uk/24u\" target=\"_blank\">Build on Open Source playlist</a></ins></p>\n<h2><a id=\"Events_for_your_diary_313\"></a><strong>Events for your diary</strong></h2>\n<h3><a id=\"OpenSearch_314\"></a><strong>OpenSearch</strong></h3>\n<h3><a id=\"Every_other_Tuesday_3pm_GMT_315\"></a><strong>Every other Tuesday, 3pm GMT</strong></h3>\n<p>This regular meet-up is for anyone interested in OpenSearch & Open Distro. All skill levels are welcome and they cover and welcome talks on topics including: search, logging, log analytics, and data visualisation.</p>\n<p>Sign up to the next session, <ins><a href=\"https://aws-oss.beachgeek.co.uk/1az\" target=\"_blank\">OpenSearch Community Meeting</a></ins></p>\n<h3><a id=\"Stay_in_touch_with_open_source_at_AWS_321\"></a><strong>Stay in touch with open source at AWS</strong></h3>\n<p>I hope this summary has been useful. Remember to check out the <ins><a href=\"https://aws.amazon.com/opensource/?opensource-all.sort-by=item.additionalFields.startDate&opensource-all.sort-order=asc\" target=\"_blank\">Open Source homepage</a></ins> to keep up to date with all our activity in open source by following us on <ins><a href=\"https://twitter.com/AWSOpen\" target=\"_blank\">@AWSOpen</a></ins></p>\n"}
Open source news and updates #138
海外精选
开源
Amazon DynamoDB

海外精选的内容汇集了全球优质的亚马逊云科技相关技术内容。同时,内容中提到的“AWS”
是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。

 0
0 2
2

亚马逊云科技解决方案 基于行业客户应用场景及技术领域的解决方案
联系亚马逊云科技专家
亚马逊云科技解决方案
基于行业客户应用场景及技术领域的解决方案
联系专家

2
目录

 分享
分享 点赞
点赞 收藏
收藏 目录
目录立即注册,开启您的免费套餐
立即关注

亚马逊云开发者
公众号

User Group
公众号

亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
关于我们 
更多资源
开发者工具
更多支持
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
