{"value":"\n\n### **前言**\n\n随着数据价值的突显,越来越多的客户期望建立准实时数据分析系统来为业务提供数据支撑,因此亟需建立一个数据仓库并将业务数据近乎实时地同步到数据仓库中进行查询和统计。\n\n\n\n本文以 Amazon Redshift 作为数仓,使用 **Amazon Database Migration Service (Aamzon DMS)** 及其更改数据捕获 (Change Data Capture, CDC) 功能将 Amazon Aurora 数据库的数据同步到 Redshift 的方案来阐述系统实施过程中遇到痛点及解决办法。\n\nAamzon DMS:\n\n[https://aws.amazon.com/cn/dms/]()\n\n### **业务描述**\n\nRedshift 主要承担下述负载:\n\n1. 上游数据写入及供内部下游业务系统查询;\n2. 承担 ETL 任务,1分钟短时任务占15%,5分钟任务占19%,15分钟任务占66%;\n3. 为 webportal 提供查询数据支撑;\n4. 为 BI 工具查询分析提供数据支撑。\n\n\n### **痛点及解决方案**\n\n1. 当遇到 Redshift 维护窗口时 Aurora 通过 DMS 同步数据至 Redshift 任务异常;\n\n2. 当遇到大批量 ETL 触发时预置 Redshift 资源紧张影响查询统计性能;\n\n3. 基于列级别权限访问控制。\n\n\n**1. 同步数据**\n\n**从 Aurora 到 Redshift**\n\n\n\n**痛点:**\n\n使用 DMS 从 Aurora 同步数据到 Redshift 任务异常。\n\n\n#### 名词解释:\n\nCDC:CDC 的全称是 Change Data Capture(变更数据获取),其核心思想是监测并捕获数据库的变动(包括数据表的插入、更新和删除),将变动数据按照发生顺序完整记录并输送到目标数据库中。\n\nDMS:Amazon Database Migration Service (Amazon DMS) 是一项云服务,可轻松迁移关系数据库、数据仓库、NoSQL 数据库及其他类型的数据存储。\n\n**挑战:**\n\n\n\nDMS 复制任务进行 CDC 追加写入数据到 Redshift 时,不可避免地会遇到因 Redshift 维护窗口期服务不可用的问题,此外 Redshift 维护时段每周发生一次且不可关闭。在 Redshift 维护窗口期间,DMS 的 CDC 任务持续进行就会潜在导致 DMS 任务异常及数据丢失。\n\n**解决方案:**\n\n1. 将 Redshift 维护事件发送到 SNS ,步骤见:\n\n[https://docs.aws.amazon.com/redshift/latest/mgmt/manage-event-notifications-console.html]()\n\n2. 通过 Lambda 监听 SNS 事件停止/启动 DMS 任务。\n\n```\nimport json\nimport json\nimport boto3\nimport time\nfrom datetime import datetime\n## Main body of the code\ndms_client = boto3.client('dms')\n##源端ARN\nendpoint_arn = 'arn:aws:dms:<region>:<account_no>:endpoint:<endpoint_id>'\n\n\ndef stop_all_dms_task():\n response = dms_client.describe_replication_tasks(\n Filters=[\n {\n 'Name': 'endpoint-arn',\n 'Values': [endpoint_arn]\n },\n ],\n MaxRecords=100,\n Marker='string',\n WithoutSettings=True\n )\n response = [dms_client.stop_replication_task(ReplicationTaskArn=item['ReplicationTaskArn']) \\\n for item in response['ReplicationTasks'] if item['Status'] in ['starting','running']]\n print('停止{}个任务完成.'.format(len(response)))\n return response\ndef start_dms_task(task_arn):\n try:\n dms_client.start_replication_task(ReplicationTaskArn=task_arn,StartReplicationTaskType='resume-processing')\n except Exception as e:\n print('任务:{},启动异常:{}'.format(task_arn,str(e)))\ndef start_all_dms_task():\n print('开始启动任务...')\n response = dms_client.describe_replication_tasks(\n Filters=[\n {\n 'Name': 'endpoint-arn',\n 'Values': [endpoint_arn]\n },\n ],\n MaxRecords=100,\n Marker='string',\n WithoutSettings=True\n )\n # print(response)\n res = [start_dms_task(item['ReplicationTaskArn']) \\\n for item in response['ReplicationTasks'] if item['Status'] in ['stopped']]\n # print('启动结果:{}'.format(res))\n stopping_task = [item['ReplicationTaskArn'] \\\n for item in response['ReplicationTasks'] if item['Status'] in ['stopping']]\n # print(stopping_task)\n if stopping_task:\n print('启动{}个任务完成,等待1min拉起正在停止的{}个任务.'.format(len(res), len(stopping_task)))\n time.sleep(60)\n start_all_dms_task()\n else:\n print('所有任务全部启动完成.')\n# Add the event id's you want to alert on from this link to the list below\n# https://docs.aws.amazon.com/redshift/latest/mgmt/working-with-event-notifications.html\n# check_list = ['2003','2004','3519','3520']\nredshift_event_trigger = {\n '2003': stop_all_dms_task,\n '2004': start_all_dms_task,\n '3519': None,\n '3520': None\n}\n\ndef lambda_handler(event, context):\n message = event['Records'][0]['Sns']['Message']\n print(message)\n message = json.loads(message)\n event_ts = message['Event Time']\n event_msg = message['Event Message']\n print('Event Time : {}, Event Message : {}'.format(event_ts, event_msg))\n eventid = message['About this Event'].split('-')[-1].strip()\n print('eventid : {}'.format(eventid))\n # 事件处理\n handler = redshift_event_trigger.get(eventid)\n if handler:\n handler()\n```\n\n**2. 数据共享 Serverless**\n\n**以提升性能**\n\n**痛点:**\n\n当遇到大批量 ETL 触发时预置 Redshift 资源紧张影响查询统计性能。\n\n\n\n**名词解释:**\n\nRedshift 预置集群:细粒度控制与定制化集群,需预先根据资源量评估实例类型及集群容量,按实例使用时长固定收费。\n\nRedshift Serverless:自动扩展资源,而无需管理数据仓库集群,具备高并发性能特性,根据标准化计算单元 – Redshift Processing Unit (RPU) 按需付费。\n\n\n\n**挑战:**\n\n当前 Redshift 预置集群主要进行报表分析、查询统计、ETL 等任务。当大批量 ETL 任务触发时会有排队等待现象,CPU 会有短时突增接近100%的峰值,查询响应非常缓慢,一次大的查询接近15分钟,业务体验非常不好。如何在不大幅增加成本的情况下提升查询分析响应速度成为急需解决的问题。\n\n\n\n**解决方案:**\n\n经过分析,我们发现原有的 Redshift 预置集群在处理 DMS CDC 任务以及少量 ETL 任务的时候,系统负载在恰当的水平(CPU 利用率在50%左右),系统负载压力来自于与此同时的查询统计请求及高峰期大量 ETL 任务。基于此考虑如下几种方案:\n\n**方案一、** 对预置集群进行按需扩缩容来解决资源问题,但面临着成本压力及扩缩容会有短时读写服务中断影响;\n\n**方案二、** 配置预置集群进行读写分离,但非高峰期存在资源浪费的情况;\n\n**方案三、** 保留原有的预置集群,新增 Redshift serverless 共享预置集群数据来实现分担查询分析任务。\n\n经论证,方案三采用新推出的 Redshift Serverless 无服务器与预置 Redshift 通过数据共享的方式来分担读查询分析工作可在不大幅增加成本的情况下实现无中断平滑分担负载,充分利用 Redshift-Serverless 完美动态扩缩容能力来承担查询分析任务,避免空闲期资源浪费。\n\n\n\n在新的架构下,Redshift 预置集群负责 DMS CDC 数据摄入任务和 Airflow ETL 的任务,Redshift 无服务器集群负责来自于客户端的查询统计分析工作负载。新的架构维持原有的 Redshift 预置集群配置不变,在最小变动的情况下将数据查询的负载压力转移到一种更具弹性的无服务器集群。\n\n\n\n\n该解决方案实施包括以下步骤:\n\n1. 建立预置 Redshift 集群,且开启数据加密,并记录命令空间 ID:类似:“xxxxxx-xxxx-xxxx-xxxx-xxxxxxxx”。\n\n\n\n记录如下图命名空间 ID:\n\n\n\n2. 对于共享数据给 Serverless,必须对预置 Redshift 集群和 Serverless 集群进行加密,默认 Serverless 启用加密且不可关闭。确保预置集群已开启数据加密,如在创建时未启用加密可在后续进行启用。\n\n\n\n3. 建立 Redshift Serverless 工作组和命名空间,并记录命名空间 ID:“aaaaa-aaaa-aaaa-aaaa-aaaaaa”\n\n\n\n4. 建立数据共享,预置集群端操作。\n\na. 建立 datashare:CREATE DATASHARE “DataShare-name”。\n\n```\nCREATE DATASHARE DataShareToServerless;\n```\nb. 添加对象到新建的 DataShare:ALTER DATASHARE “DataShare-name” ADD SCHEMA “Schema-Name”。\n\n```\nALTER DATASHARE DataShareToServerless ADD SCHEMA PUBLIC;\n```\nc. 添加 Schema 下面表到 DataShare,可指定表或添加全部:ALTER DATASHARE “DataShare-name” ADD ALL TABLES IN SCHEMA “Schema-Name”。\n\n```\nALTER DATASHARE DataShareToServerless ADD ALL TABLES IN SCHEMA PUBLIC;\n```\n\nd. 授权给对应 DB 用户。\n```\nGRANT ALTER, SHARE ON DATASHARE DataShareToServerless TO dbuser;\n```\n如需采用 IAM 用户进行 federated user 授权,则可在 Redshift 通过 select 语句查询 IAM 用户在 DB 里面映射以 IAM 开头用户进行授权即可。\n\n\n\ne. 授权新建 DataSahre给Severless:GRANT USAGE ON DATASHARE “DataShare-name” TO NAMESPACE“消费端集群命名空间-ID”。\n\n```\nGRANT USAGE ON DATASHARE DataShareToServerless TO NAMESPACE '8fab2610-f5ac-4416-9dfb-d5c78d5ca8a3';\n```\n\nf. 检查 Datashare 状态。\n\n```\nDESC DATASHARE DataShareToServerless\n```\n\n如共享成本则可看到如下共享信息,至此预置集群端操作完成。\n\n\n\n5. Serverless 端配置以验证预置集群共享是否成功及访问读取数据。\n\n\n\na. 检查 Datashare 状态和信息,执行 SHOW DATASHARES;应看到预置集群所共享 Datashare 信息如下:\n\n\n\n查看对应 Datashare 详细信息:\n\n```\nDESC DATASHARE DataShareToServerless OF NAMESPACE '524ee257-3dfc-4936-9da4-8ed1fa467830';\n```\n\n\n\nb. 在 Serverless 集群端通过 Datashare 建立 DB。\n\n```\nCREATE DATABASE reader_db FROM DATASHARE DataShareToServerless OF NAMESPACE '524ee257-3dfc-4936-9da4-8ed1fa467830';\n```\n\n\n\n\nc. 建立外部 Schema 实现跨数据库查询,schema 名字可按业务命名规范进行设计以避免业务迁移过程中改动过多代码。\n\n```\nCREATE EXTERNAL SCHEMA reader_schema FROM REDSHIFT DATABASE 'reader_db' SCHEMA 'public';\n```\n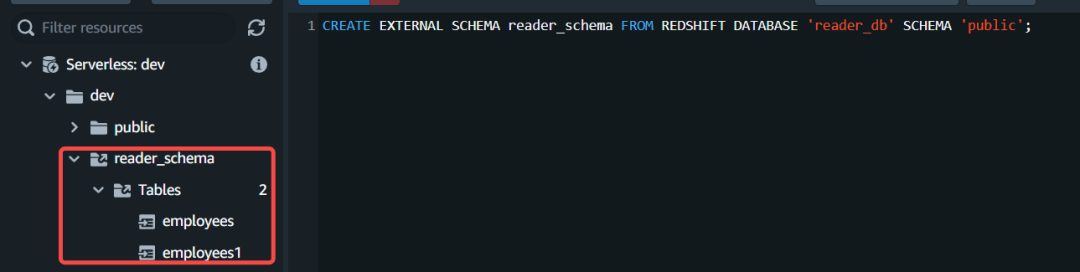\n\nd. 验证访问数据,从 Serverless 端可以看到预置 Redshift 集群所共享数据,且能进行数据访问。\n\n\n\n至此,预置 Redshift 集群共享数据给 Serverless 配置完成,后续查询分析类任务可以在 Serverless 侧进行,无需担心扩缩容及空闲期资源浪费的情况。\n\n\n**3.列级别细粒度访问控制**\n\n**痛点:**\n\n基于列级别实现细粒度权限访问控制。\n\n\n\n**名词解释:**\n\n角色:角色是可以分配给用户或其他角色的权限集合。\n\nRBAC:借助基于角色的访问控制 (RBAC, Role-Based Access Control) 在 Amazon Redshift 中管理数据库权限,可以简化 Amazon Redshift 中的安全权限管理。\n\n\n\n**挑战:**\n\n安全部门要求对共享的数据做到列级别的细粒度访问控制。由于用户众多且其权限存在变化的可能,因此安全部分希望以一种最小的维护方式对用户进行列级别访问控制。\n\n\n\n**解决方案:**\n\n通过 RBAC 将列权限分配给角色,安全部门可以将角色分配给用户。为了保证每个表都是列级权限控制的,我们使用 ALTER DEFAULT PRIVILEGES 来定义默认访问权限集,这些默认访问权限集可以应用于未来创建的表。在创建完表之后,我们可以通过 REVOKE 语句回收所有列的访问权限,再为每个角色创建列的权限,达到列级别权限访问控制的目的。\n\n**例子:**\n\n1. 创建角色。\n\n```\ncreate role analyzer_full_previleges;\ncreate role analyzer_limit_previleges;\n```\n2. 默认回收所有角色的权限。\n\n```\nalter default privileges in schema public revoke all on tables from role analyzer_full_previleges;\nalter default privileges in schema public revoke all on tables from role analyzer_limit_previleges;\n```\n3. 创建用户,将角色赋予用户。\n\n```\ncreate user analyzer_full_select with password '@AbC4321!';\ngrant role analyzer_full_previleges to analyzer_full_select;\n\ncreate user analyzer_limit_select with password '@AbC4321!';\ngrant role analyzer_limit_previleges to analyzer_limit_select;\n```\n4. 创建表。\n\n```\ncreate table public.table_1 (\ncol1 varchar(20),\ncol2 varchar(20),\ncol3 varchar(20),\ncol4 varchar(20),\ncol5 varchar(20)\n);\n\ninsert into public.table_1 values ('col1_value', 'col2_value', 'col3_value', 'col4_value', 'col5_value');\n```\n\n**5. 给角色赋予列权限。**\n\n\n\n为角色赋予表的 SELECT 权限:\n\n```\ngrant SELECT (col1, col2, col3, col4, col5) ON TABLE public.table_1 to ROLE analyzer_full_previleges;\ngrant SELECT (col1, col2) ON TABLE public.table_1 to ROLE analyzer_limit_previleges;\n```\n\n6. 测试列级别权限访问控制的效果。\n\na. 用户 analyzer_full_select 可以查询所有的列。\n\n```\nset session authorization 'analyzer_full_select';\nselect * from public.table_1;\n```\n\n\n\nb. 用户 analyzer_limit_select 只能查询 col1, col2。\n\n```\nset session authorization 'analyzer_limit_select';\nselect col1, col2 from public.table_1;\n```\n\n\n否则,系统提示权限相关错误。\n\n```\nset session authorization 'analyzer_limit_select';\nselect col1, col2, col3 from public.table_1;\n```\n\n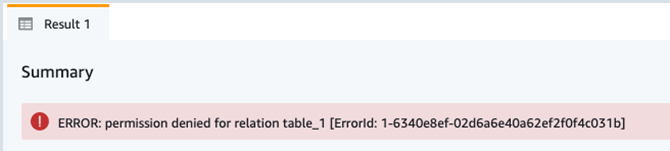\n\n**参考文档:**\n\n[https://docs.aws.amazon.com/zh_cn/redshift/latest/dg/within-account.html]()\n\n[https://docs.aws.amazon.com/zh_cn/dms/latest/userguide/Welcome.html]()\n[https://docs.aws.amazon.com/redshift/latest/dg/t_Roles.html]()\n\n[https://docs.aws.amazon.com/redshift/latest/dg/r_roles-alter-default-privileges.html]()\n\n**结束语**\n\n随着数据价值的突显,未来数据分析将会更加重要,Redshift 已具备预置集群与 Severless 无缝集成、自动升级、无宕机运维、安全加密、自动扩展、计算资源按需分配等能力,相信未来围绕 Redshift 的工具生态链会更加丰富,Redshift 自身产品功能也会更加完善,成为数据分析的旗舰产品。\n\n### **本篇作者**\n\n\n\n张雪斌\n\n亚马逊云科技技术客户经理,曾就职于 IBM、金蝶、腾讯专有云等高科技公司,拥有15年以上从业经验,在云计算,数据库,容器及微服务等技术方向有一定研究,擅长解决方案设计及技术选型和落地。\n\n\n\n陈明栋\n\n亚马逊云科技解决方案架构师,主要负责亚马逊云科技技术和解决方案的推广工作。拥有18年软件开发经验,擅长软件架构设计和项目交付及管理。加入亚马逊云科技前曾先后在 IBM、金蝶、Oracle 从事软件工程师、软件架构师等方面的工作。\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n","render":"<p><img src=\"https://dev-media.amazoncloud.cn/4cf55c11587e440a88c583ea7d475d38_5c19cf1b4be7de3b5ba3884a2caf711.png\" alt=\"5c19cf1b4be7de3b5ba3884a2caf711.png\" /></p>\n<h3><a id=\"_2\"></a><strong>前言</strong></h3>\n<p>随着数据价值的突显,越来越多的客户期望建立准实时数据分析系统来为业务提供数据支撑,因此亟需建立一个数据仓库并将业务数据近乎实时地同步到数据仓库中进行查询和统计。</p>\n<p>本文以 Amazon Redshift 作为数仓,使用 <strong>Amazon Database Migration Service (Aamzon DMS)</strong> 及其更改数据捕获 (Change Data Capture, CDC) 功能将 Amazon Aurora 数据库的数据同步到 Redshift 的方案来阐述系统实施过程中遇到痛点及解决办法。</p>\n<p>Aamzon DMS:</p>\n<p><a href=\"\" target=\"_blank\">https://aws.amazon.com/cn/dms/</a></p>\n<h3><a id=\"_14\"></a><strong>业务描述</strong></h3>\n<p>Redshift 主要承担下述负载:</p>\n<ol>\n<li>上游数据写入及供内部下游业务系统查询;</li>\n<li>承担 ETL 任务,1分钟短时任务占15%,5分钟任务占19%,15分钟任务占66%;</li>\n<li>为 webportal 提供查询数据支撑;</li>\n<li>为 BI 工具查询分析提供数据支撑。</li>\n</ol>\n<h3><a id=\"_24\"></a><strong>痛点及解决方案</strong></h3>\n<ol>\n<li>\n<p>当遇到 Redshift 维护窗口时 Aurora 通过 DMS 同步数据至 Redshift 任务异常;</p>\n</li>\n<li>\n<p>当遇到大批量 ETL 触发时预置 Redshift 资源紧张影响查询统计性能;</p>\n</li>\n<li>\n<p>基于列级别权限访问控制。</p>\n</li>\n</ol>\n<p><strong>1. 同步数据</strong></p>\n<p><strong>从 Aurora 到 Redshift</strong></p>\n<p><strong>痛点:</strong></p>\n<p>使用 DMS 从 Aurora 同步数据到 Redshift 任务异常。</p>\n<h4><a id=\"_44\"></a>名词解释:</h4>\n<p>CDC:CDC 的全称是 Change Data Capture(变更数据获取),其核心思想是监测并捕获数据库的变动(包括数据表的插入、更新和删除),将变动数据按照发生顺序完整记录并输送到目标数据库中。</p>\n<p>DMS:Amazon Database Migration Service (Amazon DMS) 是一项云服务,可轻松迁移关系数据库、数据仓库、NoSQL 数据库及其他类型的数据存储。</p>\n<p><strong>挑战:</strong></p>\n<p><img src=\"https://dev-media.amazoncloud.cn/403fcebc1ac64c3a8c7643476782d983_image.png\" alt=\"image.png\" /></p>\n<p>DMS 复制任务进行 CDC 追加写入数据到 Redshift 时,不可避免地会遇到因 Redshift 维护窗口期服务不可用的问题,此外 Redshift 维护时段每周发生一次且不可关闭。在 Redshift 维护窗口期间,DMS 的 CDC 任务持续进行就会潜在导致 DMS 任务异常及数据丢失。</p>\n<p><strong>解决方案:</strong></p>\n<ol>\n<li>将 Redshift 维护事件发送到 SNS ,步骤见:</li>\n</ol>\n<p><a href=\"\" target=\"_blank\">https://docs.aws.amazon.com/redshift/latest/mgmt/manage-event-notifications-console.html</a></p>\n<ol start=\"2\">\n<li>通过 Lambda 监听 SNS 事件停止/启动 DMS 任务。</li>\n</ol>\n<pre><code class=\"lang-\">import json\nimport json\nimport boto3\nimport time\nfrom datetime import datetime\n## Main body of the code\ndms_client = boto3.client('dms')\n##源端ARN\nendpoint_arn = 'arn:aws:dms:<region>:<account_no>:endpoint:<endpoint_id>'\n\n\ndef stop_all_dms_task():\n response = dms_client.describe_replication_tasks(\n Filters=[\n {\n 'Name': 'endpoint-arn',\n 'Values': [endpoint_arn]\n },\n ],\n MaxRecords=100,\n Marker='string',\n WithoutSettings=True\n )\n response = [dms_client.stop_replication_task(ReplicationTaskArn=item['ReplicationTaskArn']) \\\n for item in response['ReplicationTasks'] if item['Status'] in ['starting','running']]\n print('停止{}个任务完成.'.format(len(response)))\n return response\ndef start_dms_task(task_arn):\n try:\n dms_client.start_replication_task(ReplicationTaskArn=task_arn,StartReplicationTaskType='resume-processing')\n except Exception as e:\n print('任务:{},启动异常:{}'.format(task_arn,str(e)))\ndef start_all_dms_task():\n print('开始启动任务...')\n response = dms_client.describe_replication_tasks(\n Filters=[\n {\n 'Name': 'endpoint-arn',\n 'Values': [endpoint_arn]\n },\n ],\n MaxRecords=100,\n Marker='string',\n WithoutSettings=True\n )\n # print(response)\n res = [start_dms_task(item['ReplicationTaskArn']) \\\n for item in response['ReplicationTasks'] if item['Status'] in ['stopped']]\n # print('启动结果:{}'.format(res))\n stopping_task = [item['ReplicationTaskArn'] \\\n for item in response['ReplicationTasks'] if item['Status'] in ['stopping']]\n # print(stopping_task)\n if stopping_task:\n print('启动{}个任务完成,等待1min拉起正在停止的{}个任务.'.format(len(res), len(stopping_task)))\n time.sleep(60)\n start_all_dms_task()\n else:\n print('所有任务全部启动完成.')\n# Add the event id's you want to alert on from this link to the list below\n# https://docs.aws.amazon.com/redshift/latest/mgmt/working-with-event-notifications.html\n# check_list = ['2003','2004','3519','3520']\nredshift_event_trigger = {\n '2003': stop_all_dms_task,\n '2004': start_all_dms_task,\n '3519': None,\n '3520': None\n}\n\ndef lambda_handler(event, context):\n message = event['Records'][0]['Sns']['Message']\n print(message)\n message = json.loads(message)\n event_ts = message['Event Time']\n event_msg = message['Event Message']\n print('Event Time : {}, Event Message : {}'.format(event_ts, event_msg))\n eventid = message['About this Event'].split('-')[-1].strip()\n print('eventid : {}'.format(eventid))\n # 事件处理\n handler = redshift_event_trigger.get(eventid)\n if handler:\n handler()\n</code></pre>\n<p><strong>2. 数据共享 Serverless</strong></p>\n<p><strong>以提升性能</strong></p>\n<p><strong>痛点:</strong></p>\n<p>当遇到大批量 ETL 触发时预置 Redshift 资源紧张影响查询统计性能。</p>\n<p><strong>名词解释:</strong></p>\n<p>Redshift 预置集群:细粒度控制与定制化集群,需预先根据资源量评估实例类型及集群容量,按实例使用时长固定收费。</p>\n<p>Redshift Serverless:自动扩展资源,而无需管理数据仓库集群,具备高并发性能特性,根据标准化计算单元 – Redshift Processing Unit (RPU) 按需付费。</p>\n<p><strong>挑战:</strong></p>\n<p>当前 Redshift 预置集群主要进行报表分析、查询统计、ETL 等任务。当大批量 ETL 任务触发时会有排队等待现象,CPU 会有短时突增接近100%的峰值,查询响应非常缓慢,一次大的查询接近15分钟,业务体验非常不好。如何在不大幅增加成本的情况下提升查询分析响应速度成为急需解决的问题。</p>\n<p><strong>解决方案:</strong></p>\n<p>经过分析,我们发现原有的 Redshift 预置集群在处理 DMS CDC 任务以及少量 ETL 任务的时候,系统负载在恰当的水平(CPU 利用率在50%左右),系统负载压力来自于与此同时的查询统计请求及高峰期大量 ETL 任务。基于此考虑如下几种方案:</p>\n<p><strong>方案一、</strong> 对预置集群进行按需扩缩容来解决资源问题,但面临着成本压力及扩缩容会有短时读写服务中断影响;</p>\n<p><strong>方案二、</strong> 配置预置集群进行读写分离,但非高峰期存在资源浪费的情况;</p>\n<p><strong>方案三、</strong> 保留原有的预置集群,新增 Redshift serverless 共享预置集群数据来实现分担查询分析任务。</p>\n<p>经论证,方案三采用新推出的 Redshift Serverless 无服务器与预置 Redshift 通过数据共享的方式来分担读查询分析工作可在不大幅增加成本的情况下实现无中断平滑分担负载,充分利用 Redshift-Serverless 完美动态扩缩容能力来承担查询分析任务,避免空闲期资源浪费。</p>\n<p>在新的架构下,Redshift 预置集群负责 DMS CDC 数据摄入任务和 Airflow ETL 的任务,Redshift 无服务器集群负责来自于客户端的查询统计分析工作负载。新的架构维持原有的 Redshift 预置集群配置不变,在最小变动的情况下将数据查询的负载压力转移到一种更具弹性的无服务器集群。</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/8112a056ae0744738c1c61390ef01a90_image.png\" alt=\"image.png\" /></p>\n<p>该解决方案实施包括以下步骤:</p>\n<ol>\n<li>建立预置 Redshift 集群,且开启数据加密,并记录命令空间 ID:类似:“xxxxxx-xxxx-xxxx-xxxx-xxxxxxxx”。</li>\n</ol>\n<p>记录如下图命名空间 ID:</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/bf13d7eaa2554d27abd5448e47fb05ce_image.png\" alt=\"image.png\" /></p>\n<ol start=\"2\">\n<li>对于共享数据给 Serverless,必须对预置 Redshift 集群和 Serverless 集群进行加密,默认 Serverless 启用加密且不可关闭。确保预置集群已开启数据加密,如在创建时未启用加密可在后续进行启用。</li>\n</ol>\n<p><img src=\"https://dev-media.amazoncloud.cn/6088619cfadb49718d9fcc5beb8a555e_image.png\" alt=\"image.png\" /></p>\n<ol start=\"3\">\n<li>建立 Redshift Serverless 工作组和命名空间,并记录命名空间 ID:“aaaaa-aaaa-aaaa-aaaa-aaaaaa”</li>\n</ol>\n<p><img src=\"https://dev-media.amazoncloud.cn/f5ab2949d9e345ee86cf387855643b5b_image.png\" alt=\"image.png\" /></p>\n<ol start=\"4\">\n<li>建立数据共享,预置集群端操作。</li>\n</ol>\n<p>a. 建立 datashare:CREATE DATASHARE “DataShare-name”。</p>\n<pre><code class=\"lang-\">CREATE DATASHARE DataShareToServerless;\n</code></pre>\n<p>b. 添加对象到新建的 DataShare:ALTER DATASHARE “DataShare-name” ADD SCHEMA “Schema-Name”。</p>\n<pre><code class=\"lang-\">ALTER DATASHARE DataShareToServerless ADD SCHEMA PUBLIC;\n</code></pre>\n<p>c. 添加 Schema 下面表到 DataShare,可指定表或添加全部:ALTER DATASHARE “DataShare-name” ADD ALL TABLES IN SCHEMA “Schema-Name”。</p>\n<pre><code class=\"lang-\">ALTER DATASHARE DataShareToServerless ADD ALL TABLES IN SCHEMA PUBLIC;\n</code></pre>\n<p>d. 授权给对应 DB 用户。</p>\n<pre><code class=\"lang-\">GRANT ALTER, SHARE ON DATASHARE DataShareToServerless TO dbuser;\n</code></pre>\n<p>如需采用 IAM 用户进行 federated user 授权,则可在 Redshift 通过 select 语句查询 IAM 用户在 DB 里面映射以 IAM 开头用户进行授权即可。</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/62152bd5060245ee8e296e647334b1f8_image.png\" alt=\"image.png\" /></p>\n<p>e. 授权新建 DataSahre给Severless:GRANT USAGE ON DATASHARE “DataShare-name” TO NAMESPACE“消费端集群命名空间-ID”。</p>\n<pre><code class=\"lang-\">GRANT USAGE ON DATASHARE DataShareToServerless TO NAMESPACE '8fab2610-f5ac-4416-9dfb-d5c78d5ca8a3';\n</code></pre>\n<p>f. 检查 Datashare 状态。</p>\n<pre><code class=\"lang-\">DESC DATASHARE DataShareToServerless\n</code></pre>\n<p>如共享成本则可看到如下共享信息,至此预置集群端操作完成。</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/a10cbe467c884e25a9baf4f1b4ca142e_image.png\" alt=\"image.png\" /></p>\n<ol start=\"5\">\n<li>Serverless 端配置以验证预置集群共享是否成功及访问读取数据。</li>\n</ol>\n<p>a. 检查 Datashare 状态和信息,执行 SHOW DATASHARES;应看到预置集群所共享 Datashare 信息如下:</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/7d37068cbf7a49d4812c4af8f5affd8e_image.png\" alt=\"image.png\" /></p>\n<p>查看对应 Datashare 详细信息:</p>\n<pre><code class=\"lang-\">DESC DATASHARE DataShareToServerless OF NAMESPACE '524ee257-3dfc-4936-9da4-8ed1fa467830';\n</code></pre>\n<p><img src=\"https://dev-media.amazoncloud.cn/84c1166118874da0a2a4d7d11cf62908_image.png\" alt=\"image.png\" /></p>\n<p>b. 在 Serverless 集群端通过 Datashare 建立 DB。</p>\n<pre><code class=\"lang-\">CREATE DATABASE reader_db FROM DATASHARE DataShareToServerless OF NAMESPACE '524ee257-3dfc-4936-9da4-8ed1fa467830';\n</code></pre>\n<p><img src=\"https://dev-media.amazoncloud.cn/3bd9ee88046446fc9560c5c34488bc9b_image.png\" alt=\"image.png\" /></p>\n<p>c. 建立外部 Schema 实现跨数据库查询,schema 名字可按业务命名规范进行设计以避免业务迁移过程中改动过多代码。</p>\n<pre><code class=\"lang-\">CREATE EXTERNAL SCHEMA reader_schema FROM REDSHIFT DATABASE 'reader_db' SCHEMA 'public';\n</code></pre>\n<p><img src=\"https://dev-media.amazoncloud.cn/df4de647494149a58317e77dc0ca1c65_image.png\" alt=\"image.png\" /></p>\n<p>d. 验证访问数据,从 Serverless 端可以看到预置 Redshift 集群所共享数据,且能进行数据访问。</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/3aa75de95c77492ca3a23156e3eb19d8_image.png\" alt=\"image.png\" /></p>\n<p>至此,预置 Redshift 集群共享数据给 Serverless 配置完成,后续查询分析类任务可以在 Serverless 侧进行,无需担心扩缩容及空闲期资源浪费的情况。</p>\n<p><strong>3.列级别细粒度访问控制</strong></p>\n<p><strong>痛点:</strong></p>\n<p>基于列级别实现细粒度权限访问控制。</p>\n<p><strong>名词解释:</strong></p>\n<p>角色:角色是可以分配给用户或其他角色的权限集合。</p>\n<p>RBAC:借助基于角色的访问控制 (RBAC, Role-Based Access Control) 在 Amazon Redshift 中管理数据库权限,可以简化 Amazon Redshift 中的安全权限管理。</p>\n<p><strong>挑战:</strong></p>\n<p>安全部门要求对共享的数据做到列级别的细粒度访问控制。由于用户众多且其权限存在变化的可能,因此安全部分希望以一种最小的维护方式对用户进行列级别访问控制。</p>\n<p><strong>解决方案:</strong></p>\n<p>通过 RBAC 将列权限分配给角色,安全部门可以将角色分配给用户。为了保证每个表都是列级权限控制的,我们使用 ALTER DEFAULT PRIVILEGES 来定义默认访问权限集,这些默认访问权限集可以应用于未来创建的表。在创建完表之后,我们可以通过 REVOKE 语句回收所有列的访问权限,再为每个角色创建列的权限,达到列级别权限访问控制的目的。</p>\n<p><strong>例子:</strong></p>\n<ol>\n<li>创建角色。</li>\n</ol>\n<pre><code class=\"lang-\">create role analyzer_full_previleges;\ncreate role analyzer_limit_previleges;\n</code></pre>\n<ol start=\"2\">\n<li>默认回收所有角色的权限。</li>\n</ol>\n<pre><code class=\"lang-\">alter default privileges in schema public revoke all on tables from role analyzer_full_previleges;\nalter default privileges in schema public revoke all on tables from role analyzer_limit_previleges;\n</code></pre>\n<ol start=\"3\">\n<li>创建用户,将角色赋予用户。</li>\n</ol>\n<pre><code class=\"lang-\">create user analyzer_full_select with password '@AbC4321!';\ngrant role analyzer_full_previleges to analyzer_full_select;\n\ncreate user analyzer_limit_select with password '@AbC4321!';\ngrant role analyzer_limit_previleges to analyzer_limit_select;\n</code></pre>\n<ol start=\"4\">\n<li>创建表。</li>\n</ol>\n<pre><code class=\"lang-\">create table public.table_1 (\ncol1 varchar(20),\ncol2 varchar(20),\ncol3 varchar(20),\ncol4 varchar(20),\ncol5 varchar(20)\n);\n\ninsert into public.table_1 values ('col1_value', 'col2_value', 'col3_value', 'col4_value', 'col5_value');\n</code></pre>\n<p><strong>5. 给角色赋予列权限。</strong></p>\n<p>为角色赋予表的 SELECT 权限:</p>\n<pre><code class=\"lang-\">grant SELECT (col1, col2, col3, col4, col5) ON TABLE public.table_1 to ROLE analyzer_full_previleges;\ngrant SELECT (col1, col2) ON TABLE public.table_1 to ROLE analyzer_limit_previleges;\n</code></pre>\n<ol start=\"6\">\n<li>测试列级别权限访问控制的效果。</li>\n</ol>\n<p>a. 用户 analyzer_full_select 可以查询所有的列。</p>\n<pre><code class=\"lang-\">set session authorization 'analyzer_full_select';\nselect * from public.table_1;\n</code></pre>\n<p><img src=\"https://dev-media.amazoncloud.cn/abbfd70e98004d6b97a07c89ed54911e_image.png\" alt=\"image.png\" /></p>\n<p>b. 用户 analyzer_limit_select 只能查询 col1, col2。</p>\n<pre><code class=\"lang-\">set session authorization 'analyzer_limit_select';\nselect col1, col2 from public.table_1;\n</code></pre>\n<p><img src=\"https://dev-media.amazoncloud.cn/9375a38393794940aa8e80001a5d11d0_image.png\" alt=\"image.png\" /></p>\n<p>否则,系统提示权限相关错误。</p>\n<pre><code class=\"lang-\">set session authorization 'analyzer_limit_select';\nselect col1, col2, col3 from public.table_1;\n</code></pre>\n<p><img src=\"https://dev-media.amazoncloud.cn/1a58a6900d7b4a9c92e2314f1f53fbe7_image.png\" alt=\"image.png\" /></p>\n<p><strong>参考文档:</strong></p>\n<p><a href=\"\" target=\"_blank\">https://docs.aws.amazon.com/zh_cn/redshift/latest/dg/within-account.html</a></p>\n<p><a href=\"\" target=\"_blank\">https://docs.aws.amazon.com/zh_cn/dms/latest/userguide/Welcome.html</a><br />\n<a href=\"\" target=\"_blank\">https://docs.aws.amazon.com/redshift/latest/dg/t_Roles.html</a></p>\n<p><a href=\"\" target=\"_blank\">https://docs.aws.amazon.com/redshift/latest/dg/r_roles-alter-default-privileges.html</a></p>\n<p><strong>结束语</strong></p>\n<p>随着数据价值的突显,未来数据分析将会更加重要,Redshift 已具备预置集群与 Severless 无缝集成、自动升级、无宕机运维、安全加密、自动扩展、计算资源按需分配等能力,相信未来围绕 Redshift 的工具生态链会更加丰富,Redshift 自身产品功能也会更加完善,成为数据分析的旗舰产品。</p>\n<h3><a id=\"_405\"></a><strong>本篇作者</strong></h3>\n<p><img src=\"https://dev-media.amazoncloud.cn/d9ec9f6944f24451aa6503c249e685f8_image.png\" alt=\"image.png\" /></p>\n<p>张雪斌</p>\n<p>亚马逊云科技技术客户经理,曾就职于 IBM、金蝶、腾讯专有云等高科技公司,拥有15年以上从业经验,在云计算,数据库,容器及微服务等技术方向有一定研究,擅长解决方案设计及技术选型和落地。</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/bd2b4386522d4705843ea01f5cac54f9_image.png\" alt=\"image.png\" /></p>\n<p>陈明栋</p>\n<p>亚马逊云科技解决方案架构师,主要负责亚马逊云科技技术和解决方案的推广工作。拥有18年软件开发经验,擅长软件架构设计和项目交付及管理。加入亚马逊云科技前曾先后在 IBM、金蝶、Oracle 从事软件工程师、软件架构师等方面的工作。</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/701d99a42a68487581faf696024d9cd0_640%20%285%29.gif\" alt=\"640 5.gif\" /></p>\n"}
智能湖仓2.0实践系列:云原生数仓 Amazon Redshift Serverless 与 CDC 同步实践
Amazon Redshift

 0
0 0
0 相关产品
相关产品 相关产品
相关产品亚马逊云科技解决方案 基于行业客户应用场景及技术领域的解决方案
联系亚马逊云科技专家
亚马逊云科技解决方案
基于行业客户应用场景及技术领域的解决方案
联系专家

0
目录

 分享
分享 点赞
点赞 收藏
收藏 目录
目录立即注册,开启您的免费套餐
立即关注

亚马逊云开发者
公众号

User Group
公众号

亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
关于我们 
更多资源
开发者工具
更多支持
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
