{"value":"#### **为什么在 EMR 部署 Kylin 需要支持 Amazon Glue**\n\n#### **什么是 Amazon Glue?**\nAmazon Glue 是一项完全托管的 ETL(提取、转换和加载)服务,使 Amazon用户能够轻松而经济高效地对数据进行分类、清理和扩充,并在各种数据存储之间可靠地移动数据。Amazon Glue 由一个称为 Amazon Glue 数据目录的中央元数据存储库、一个自动生成代码的 ETL 引擎以及一个处理依赖项解析、作业监控和重试的灵活计划程序组成。Amazon Glue 是无服务器服务,因此无需设置或管理基础设施。\n\n#### **Kylin 为什么需要支持 Amazon Glue Catalog?**\n目前社区有很多 Kylin 用户在使用 Amazon EMR,组件主要包括 Hadoop、Spark、Hive、Presto 等,如果没有配置使用 Amazon Glue data Catalog,那么在各个数据仓库组件如 Hive、Spark、Presto 建的数据表,在其它组件上是找不到的,也就不能使用,公司底层的数据仓库是提供给各个业务部门来进行使用,为了解决这个问题,在创建 Amazon EMR 集群时就可以使用 Amazon Glue data Catalog 来存储元数据,对各个组件共享数据源,对各个业务部门进行共享数据源,将各个业务部门的数据构建成一个大的数据立方体,能够快速响应公司高速发展的业务需求。\n\n现代公司的数据都是基于云平台搭建,大数据团队使用的 Amazon EMR 来进行数据加工、数据分析、以及模型训练,随着数据增长,用户等待数据分析结果的时间也随之线性增长,于是一些用户选择了 Apache Kylin 作为开源 OLAP 解决方案,来实现海量数据下的秒级数据查询体验。\n\n但是最近社区用户联系到我们,告知 Kylin 4 还不支持从 Glue 读取表元数据,所以我们和社区用户合作一起检查这里遇到的问题并最终解决了问题,从而使得 Kylin 4 支持了 Amazon Glue Catalog,这样带来的好处在于 Hive、Presto、Spark、Kylin 中可以共享表和数据,使得每个主题都串联起来形成一个大的数据分析平台,打破元数据障碍。\n\n#### **Apache Kylin 支持 Amazon Glue 吗?**\n\n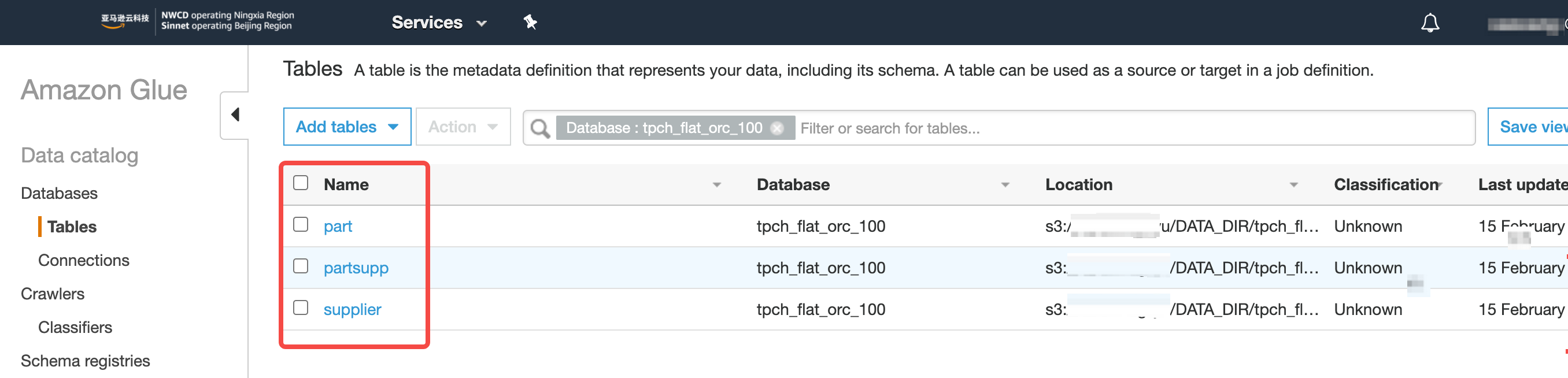\n\n#### **部署前准备**\n\n##### 软件信息一览\n\n\n##### **准备 Glue 数据库和表**\n\n\n\n\n\n##### **创建 Amazon EMR 集群**\n\n```\nShell\naws emr create-cluster --applications Name=Hadoop Name=Hive Name=Spark Name=ZooKeeper Name=Tez Name=Ganglia \\\n --ec2-attributes ${} \\\n --release-label emr-6.5.0 \\\n --log-uri ${} \\\n --instance-groups ${} \\\n --configurations '[{\"Classification\":\"hive-site\",\"Properties\":{\"hive.metastore.client.factory.class\":\"com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory\"}}]' \\\n --auto-scaling-role EMR_AutoScaling_DefaultRole \\\n --ebs-root-volume-size 100 \\\n --service-role EMR_DefaultRole \\\n --enable-debugging \\\n --name 'Kylin4_on_EMR65_with_Glue' \\\n --region cn-northwest-1\n```\n\n登录 Master 节点,并且检查 Hadoop 版本 和 Hadoop 集群是否启动成功。\n\n\n\n\n\n##### **获取环境信息(Optional)**\n\n如果你使用 RDS 或者其他元数据存储,请酌情跳过此步。\n\n由于 Kylin 4.X 推荐使用 RDBMS 作为元数据存储,处于测试目的,这里使用 Master 节点自带的 MariaDB 作为元数据存储;关于 MariaDB 的主机名称、账号、密码等信息,可以从/etc/hive/conf/hive-site.xml获取。\n\n```\nJava\nkylin.metadata.url=kylin4_on_cloud@jdbc,url=jdbc:mysql://${HOSTNAME}:3306/hue,username=hive,password=${PASSWORD},maxActive=10,maxIdle=10,driverClassName=org.mariadb.jdbc.Driver \nkylin.env.zookeeper-connect-string=${HOSTNAME}\n```\n\n通过 spark-sql 来测试 Amazon的 Spark SQL 是否能够通过 Glue 获取数据库和表的元数据,首次会发现启动报错失败。\n\n##### **测试 Spark SQL 和 Amazon Glue 的连通性**\n\n获取这些信息后,并且替换以上 Kylin 配置项里面的变量,如${PASSWORD},保存到本地,供下一步启动 Kylin 进程使用。\n\n\n\n其通过以下命令替换 Spark 使用的 hive-site.xml\n\n```\nShell\ncd /etc/spark/conf\nsudo mv hive-site.xml hive-site.xml.bak\n```\n\n并且修改/etc/spark/conf/hive-site.xml文件中hive.execution.engine的值为mr,再次尝试启动 Spark-SQL CLI,验证对 Glue 的表数据执行查询成功。\n\n\n\n\n\n##### **准备 kylin-spark-engine.jar(Optional)**\n\n如果 Apache Kylin 4.0.2 已经发布,那么应该已经修改该问题,可以跳过此步。否则请参考以下步骤,替换 kylin-spark-engine.jar:\n\n参考下面的命令,克隆 kylin 仓库,执行 mvn clean package -DskipTests,获取kylin-spark-project/kylin-spark-engine/target/kylin-spark-engine-4.0.0-SNAPSHOT.jar 。\n\n```\nShell\ngit clone https://github.com/hit-lacus/kylin.git\ncd kylin\ngit checkout KYLIN-5160\nmvn clean package -DskipTests\n\n# find -name kylin-spark-engine-4.0.0-SNAPSHOT.jar kylin-spark-project/kylin-spark-engine/target\n```\n\nPatch link : https://github.com/apache/kylin/pull/1819\n\n#### **部署 Kylin 并连接 Glue**\n\n##### **下载 Kylin**\n\n1. 下载并解压 Kylin ,请根据 EMR 的版本选择对应的 Kylin package,具体来说,EMR 5.X 使用 spark2 的 package,EMR 6.X 使用 spark3 的 package。\n\n```\nShell\n# aws s3 cp s3://${BUCKET}/apache-kylin-4.0.1-bin-spark3.tar.gz .\n# wget apache-kylin-4.0.1-bin-spark3.tar.gz\ntar zxvf apache-kylin-4.0.1-bin-spark3.tar.gz .\ncd apache-kylin-4.0.1-bin-spark3\nexport KYLIN_HOME=/home/hadoop/apache-kylin-4.0.1-bin-spark3\n```\n\n2. 获取 RDBMS 的 驱动 jar(Optional)\n如果你是用别的 RDBMS 作为元数据存储,请跳过此步骤。\n\n```\nShell\ncd $KYLIN_HOME\nmkdir ext\ncp /usr/lib/hive/lib/mariadb-connector-java.jar $KYLIN_HOME/ext\n```\n\n##### **准备 Spark**\n\n由于 Amazon Spark 内置对 Amazon Glue 的支持,所以**加载表元数据和执行构建需要使用 Amazon Spark**;但是考虑到 Kylin 4.0.1 是支持 Apache Spark,并且 Amazon Spark 相对 Apache Spark 有比较大的代码修改,两者兼容性较差,所以**查询 Cube 需要使用 Apache Spark**。综上所述,需要根据 Kylin 需要执行查询任务还是构建任务,来切换所使用的的 Spark。\n\n- 准备 Amazon Spark\n\n```\nShell\ncd $KYLIN_HOME\ncp -r /usr/lib/spark spark-aws\n```\n- 准备 Apache Spark\n- 请根据 EMR 的版本选择对应的 Spark 版本安装包,具体来说,EMR 5.X 使用 Spark 2.4.7 的 Spark 安装包,EMR 6.X 使用 Spark 3.1.2 的 Spark 安装包。\n\n```\nShell\ncd $KYLIN_HOME\naws s3 cp s3://${BUCKET}/spark-2.4.7-bin-hadoop2.7.tgz $KYLIN_HOME # Or downloads spark-2.4.7-bin-hadoop2.7.tgz from offical website\ntar zxvf spark-2.4.7-bin-hadoop2.7.tgz\nmv spark-2.4.7-bin-hadoop2.7 spark-apache\n```\n\n- 因为要先加载 Glue 表,所以这里通过软链接将$KYLIN_HOME/spark指向 Amazon Spark;请注意无需设置 SPARK_HOME,因为在 $KYLIN_HOME/spark 存在并且SPARK_HOME 未设置的情况下,Kylin 会默认使用$KYLIN_HOME/spark 。\n\n```\nShell\nln -s spark-aws spark\n```\n\n#### **修改 Kylin 启动脚本**\n\n3. 启动 Spark SQL CLI,不退出\n4. 通过 jps -ml ${PID} 获取 SparkSQLCLIDriver 的 PID,然后获取 Driver 的driver.extraClasspath。或者也可以从/etc/spark/conf/spark-defaults.conf 获取。\n\n```\nShell\njps -ml | grep SparkSubmit\njinfo ${PID} | grep \"spark.driver.extraClassPath\"\n```\n\n\n\n5. 编辑 bin/kylin.sh,修改KYLIN_TOMCAT_CLASSPATH 变量,追加 kylin_driver_classpath ;保存好 bin/kylin.sh 后退出 Spark SQL CLI\n\n- 修改前的kylin.sh\n\n\n\n- 针对 EMR 6.5.0,修改后的sh:kylin_driver_classpath 放到最后\n\n\n\n- 针对 EMR 5.33.1,修改后的sh:kylin_driver_classpath 放到 $SPARK_HOME/jars 之前\n\n\n\n\n\n##### **配置 Kylin**\n\n```\nShell\ncd $KYLIN_HOME\nvim conf/kylin.properties \n```\n\n\n\n#### **启动 Kylin 并验证构建**\n\n##### **启动 Kylin**\n\n```\nShell\ncd $KYLIN_HOME\nln -s spark spark_aws # skip this step if soft link 'spark' exists \nbin/kylin.sh restart\n```\n\n\n\n\n\n##### 替换 kylin-spark-engine.jar (Optional)\n\n仅对于 4.0.1 需要操作该步骤。\n\n```\nApache\ncd $KYLIN_HOME/tomcat/webapps/kylin/WEB-INF/lib/\nmv kylin-spark-engine-4.0.1.jar kylin-spark-engine-4.0.1.jar.bak # remove old one \ncp kylin-spark-engine-4.0.0-SNAPSHOT.jar .\n\nbin/kylin.sh restart # restart kylin to make new jar be loaded\n```\n\n##### **加载 Glue 表、构建**\n\n- 加载 Glue 表元数据\n\n\n\n\n\n- 创建 Model 和 Cube,然后触发构建\n\n\n\n\n##### **验证查询**\n\n切换 Kylin 使用的 Spark,重启 Kylin。\n\n```\nShell\ncd $KYLIN_HOME\nrm spark # 'spark' is a soft link, it is point to aws spark\nln -s spark_apache spark # switch from aws spark to apache spark\nbin/kylin.sh restart\n```\n\n执行测试查询,查询成功\n\n\n\n#### **讨论和问答**\n\n##### 为什么必须使用两个 Spark(Amazon Spark & Apache Spark)?\n\n由于 Amazon Spark 内置对 Amazon Glue Catalog 的支持,并且加载表和构建引擎需要获取表,所以**加载表元数据和执行构建需要使用 Amazon Spark**;但是考虑到 Kylin 4.0.1 是支持 Apache **Spark**,并且 Amazon Spark 相对 Apache Spark 有比较大的代码修改,造成两者兼容性较差,所以查询 Cube 需要使用 Apache Spark。综上所述,需要根据 Kylin 需要执行**查询任务还是构建任务,来切换所使用的的 Spark**。\n\n在实际使用过程中,可以考虑 Job Node(构建任务)使用 Amazon Spark,Query Node(查询任务)使用 Apache Spark。\n\n##### 为什么需要修改 kylin.sh?\n\nKylin 进程作为 Spark Driver 需要通过Amazon -glue-datacatalog-spark-client.jar加载表元数据,所以这块需要修改 kylin.sh,将相关 jar 加载到 Kylin 进程的 classpath。\n\n#### **本篇作者**\n\n\n\n#### **任耀洲**\n\nAmazon 解决方案架构师,负责企业客户应用在Amazon 的架构咨询和 设计。在微服务架构设计、数据库等领域有丰富的经验\n","render":"<h4><a id=\"_EMR__Kylin__Amazon_Glue_0\"></a><strong>为什么在 EMR 部署 Kylin 需要支持 Amazon Glue</strong></h4>\n<h4><a id=\"_Amazon_Glue_2\"></a><strong>什么是 Amazon Glue?</strong></h4>\n<p>Amazon Glue 是一项完全托管的 ETL(提取、转换和加载)服务,使 Amazon用户能够轻松而经济高效地对数据进行分类、清理和扩充,并在各种数据存储之间可靠地移动数据。Amazon Glue 由一个称为 Amazon Glue 数据目录的中央元数据存储库、一个自动生成代码的 ETL 引擎以及一个处理依赖项解析、作业监控和重试的灵活计划程序组成。Amazon Glue 是无服务器服务,因此无需设置或管理基础设施。</p>\n<h4><a id=\"Kylin__Amazon_Glue_Catalog_5\"></a><strong>Kylin 为什么需要支持 Amazon Glue Catalog?</strong></h4>\n<p>目前社区有很多 Kylin 用户在使用 Amazon EMR,组件主要包括 Hadoop、Spark、Hive、Presto 等,如果没有配置使用 Amazon Glue data Catalog,那么在各个数据仓库组件如 Hive、Spark、Presto 建的数据表,在其它组件上是找不到的,也就不能使用,公司底层的数据仓库是提供给各个业务部门来进行使用,为了解决这个问题,在创建 Amazon EMR 集群时就可以使用 Amazon Glue data Catalog 来存储元数据,对各个组件共享数据源,对各个业务部门进行共享数据源,将各个业务部门的数据构建成一个大的数据立方体,能够快速响应公司高速发展的业务需求。</p>\n<p>现代公司的数据都是基于云平台搭建,大数据团队使用的 Amazon EMR 来进行数据加工、数据分析、以及模型训练,随着数据增长,用户等待数据分析结果的时间也随之线性增长,于是一些用户选择了 Apache Kylin 作为开源 OLAP 解决方案,来实现海量数据下的秒级数据查询体验。</p>\n<p>但是最近社区用户联系到我们,告知 Kylin 4 还不支持从 Glue 读取表元数据,所以我们和社区用户合作一起检查这里遇到的问题并最终解决了问题,从而使得 Kylin 4 支持了 Amazon Glue Catalog,这样带来的好处在于 Hive、Presto、Spark、Kylin 中可以共享表和数据,使得每个主题都串联起来形成一个大的数据分析平台,打破元数据障碍。</p>\n<h4><a id=\"Apache_Kylin__Amazon_Glue__12\"></a><strong>Apache Kylin 支持 Amazon Glue 吗?</strong></h4>\n<p><img src=\"https://dev-media.amazoncloud.cn/a0afeb0a50094132b7868131a10c558b_image.png\" alt=\"image.png\" /></p>\n<h4><a id=\"_16\"></a><strong>部署前准备</strong></h4>\n<h5><a id=\"_18\"></a>软件信息一览</h5>\n<p><img src=\"https://dev-media.amazoncloud.cn/c2eeca976a42494e871dee39eeec8845_image.png\" alt=\"image.png\" /></p>\n<h5><a id=\"_Glue__21\"></a><strong>准备 Glue 数据库和表</strong></h5>\n<p><img src=\"https://dev-media.amazoncloud.cn/a0afeb0a50094132b7868131a10c558b_image.png\" alt=\"image.png\" /></p>\n<p><img src=\"https://dev-media.amazoncloud.cn/c2eeca976a42494e871dee39eeec8845_image.png\" alt=\"image.png\" /></p>\n<h5><a id=\"_Amazon_EMR__27\"></a><strong>创建 Amazon EMR 集群</strong></h5>\n<pre><code class=\"lang-\">Shell\naws emr create-cluster --applications Name=Hadoop Name=Hive Name=Spark Name=ZooKeeper Name=Tez Name=Ganglia \\\n --ec2-attributes ${} \\\n --release-label emr-6.5.0 \\\n --log-uri ${} \\\n --instance-groups ${} \\\n --configurations '[{"Classification":"hive-site","Properties":{"hive.metastore.client.factory.class":"com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"}}]' \\\n --auto-scaling-role EMR_AutoScaling_DefaultRole \\\n --ebs-root-volume-size 100 \\\n --service-role EMR_DefaultRole \\\n --enable-debugging \\\n --name 'Kylin4_on_EMR65_with_Glue' \\\n --region cn-northwest-1\n</code></pre>\n<p>登录 Master 节点,并且检查 Hadoop 版本 和 Hadoop 集群是否启动成功。</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/5fff5e38e8864a83bd3c5e0bf1f52208_image.png\" alt=\"image.png\" /></p>\n<p><img src=\"https://dev-media.amazoncloud.cn/6b8e31f523d145f899b0775bbc9f2e08_image.png\" alt=\"image.png\" /></p>\n<h5><a id=\"Optional_51\"></a><strong>获取环境信息(Optional)</strong></h5>\n<p>如果你使用 RDS 或者其他元数据存储,请酌情跳过此步。</p>\n<p>由于 Kylin 4.X 推荐使用 RDBMS 作为元数据存储,处于测试目的,这里使用 Master 节点自带的 MariaDB 作为元数据存储;关于 MariaDB 的主机名称、账号、密码等信息,可以从/etc/hive/conf/hive-site.xml获取。</p>\n<pre><code class=\"lang-\">Java\nkylin.metadata.url=kylin4_on_cloud@jdbc,url=jdbc:mysql://${HOSTNAME}:3306/hue,username=hive,password=${PASSWORD},maxActive=10,maxIdle=10,driverClassName=org.mariadb.jdbc.Driver \nkylin.env.zookeeper-connect-string=${HOSTNAME}\n</code></pre>\n<p>通过 spark-sql 来测试 Amazon的 Spark SQL 是否能够通过 Glue 获取数据库和表的元数据,首次会发现启动报错失败。</p>\n<h5><a id=\"_Spark_SQL__Amazon_Glue__65\"></a><strong>测试 Spark SQL 和 Amazon Glue 的连通性</strong></h5>\n<p>获取这些信息后,并且替换以上 Kylin 配置项里面的变量,如${PASSWORD},保存到本地,供下一步启动 Kylin 进程使用。</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/52068fbde23c477db35dfeba33336691_image.png\" alt=\"image.png\" /></p>\n<p>其通过以下命令替换 Spark 使用的 hive-site.xml</p>\n<pre><code class=\"lang-\">Shell\ncd /etc/spark/conf\nsudo mv hive-site.xml hive-site.xml.bak\n</code></pre>\n<p>并且修改/etc/spark/conf/hive-site.xml文件中hive.execution.engine的值为mr,再次尝试启动 Spark-SQL CLI,验证对 Glue 的表数据执行查询成功。</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/3efba32d0e83478dafd57b72e3104217_image.png\" alt=\"image.png\" /></p>\n<p><img src=\"https://dev-media.amazoncloud.cn/bc9d8208e48d4a9da51706262e4bca3a_image.png\" alt=\"image.png\" /></p>\n<h5><a id=\"_kylinsparkenginejarOptional_85\"></a><strong>准备 kylin-spark-engine.jar(Optional)</strong></h5>\n<p>如果 Apache Kylin 4.0.2 已经发布,那么应该已经修改该问题,可以跳过此步。否则请参考以下步骤,替换 kylin-spark-engine.jar:</p>\n<p>参考下面的命令,克隆 kylin 仓库,执行 mvn clean package -DskipTests,获取kylin-spark-project/kylin-spark-engine/target/kylin-spark-engine-4.0.0-SNAPSHOT.jar 。</p>\n<pre><code class=\"lang-\">Shell\ngit clone https://github.com/hit-lacus/kylin.git\ncd kylin\ngit checkout KYLIN-5160\nmvn clean package -DskipTests\n\n# find -name kylin-spark-engine-4.0.0-SNAPSHOT.jar kylin-spark-project/kylin-spark-engine/target\n</code></pre>\n<p>Patch link : https://github.com/apache/kylin/pull/1819</p>\n<h4><a id=\"_Kylin__Glue_103\"></a><strong>部署 Kylin 并连接 Glue</strong></h4>\n<h5><a id=\"_Kylin_105\"></a><strong>下载 Kylin</strong></h5>\n<ol>\n<li>下载并解压 Kylin ,请根据 EMR 的版本选择对应的 Kylin package,具体来说,EMR 5.X 使用 spark2 的 package,EMR 6.X 使用 spark3 的 package。</li>\n</ol>\n<pre><code class=\"lang-\">Shell\n# aws s3 cp s3://${BUCKET}/apache-kylin-4.0.1-bin-spark3.tar.gz .\n# wget apache-kylin-4.0.1-bin-spark3.tar.gz\ntar zxvf apache-kylin-4.0.1-bin-spark3.tar.gz .\ncd apache-kylin-4.0.1-bin-spark3\nexport KYLIN_HOME=/home/hadoop/apache-kylin-4.0.1-bin-spark3\n</code></pre>\n<ol start=\"2\">\n<li>获取 RDBMS 的 驱动 jar(Optional)<br />\n如果你是用别的 RDBMS 作为元数据存储,请跳过此步骤。</li>\n</ol>\n<pre><code class=\"lang-\">Shell\ncd $KYLIN_HOME\nmkdir ext\ncp /usr/lib/hive/lib/mariadb-connector-java.jar $KYLIN_HOME/ext\n</code></pre>\n<h5><a id=\"_Spark_128\"></a><strong>准备 Spark</strong></h5>\n<p>由于 Amazon Spark 内置对 Amazon Glue 的支持,所以<strong>加载表元数据和执行构建需要使用 Amazon Spark</strong>;但是考虑到 Kylin 4.0.1 是支持 Apache Spark,并且 Amazon Spark 相对 Apache Spark 有比较大的代码修改,两者兼容性较差,所以<strong>查询 Cube 需要使用 Apache Spark</strong>。综上所述,需要根据 Kylin 需要执行查询任务还是构建任务,来切换所使用的的 Spark。</p>\n<ul>\n<li>准备 Amazon Spark</li>\n</ul>\n<pre><code class=\"lang-\">Shell\ncd $KYLIN_HOME\ncp -r /usr/lib/spark spark-aws\n</code></pre>\n<ul>\n<li>准备 Apache Spark</li>\n<li>请根据 EMR 的版本选择对应的 Spark 版本安装包,具体来说,EMR 5.X 使用 Spark 2.4.7 的 Spark 安装包,EMR 6.X 使用 Spark 3.1.2 的 Spark 安装包。</li>\n</ul>\n<pre><code class=\"lang-\">Shell\ncd $KYLIN_HOME\naws s3 cp s3://${BUCKET}/spark-2.4.7-bin-hadoop2.7.tgz $KYLIN_HOME # Or downloads spark-2.4.7-bin-hadoop2.7.tgz from offical website\ntar zxvf spark-2.4.7-bin-hadoop2.7.tgz\nmv spark-2.4.7-bin-hadoop2.7 spark-apache\n</code></pre>\n<ul>\n<li>因为要先加载 Glue 表,所以这里通过软链接将$KYLIN_HOME/spark指向 Amazon Spark;请注意无需设置 SPARK_HOME,因为在 KYLIN_HOME/spark 存在并且SPARK_HOME 未设置的情况下,Kylin 会默认使用KYLIN_HOME/spark 。</li>\n</ul>\n<pre><code class=\"lang-\">Shell\nln -s spark-aws spark\n</code></pre>\n<h4><a id=\"_Kylin__157\"></a><strong>修改 Kylin 启动脚本</strong></h4>\n<ol start=\"3\">\n<li>启动 Spark SQL CLI,不退出</li>\n<li>通过 jps -ml ${PID} 获取 SparkSQLCLIDriver 的 PID,然后获取 Driver 的driver.extraClasspath。或者也可以从/etc/spark/conf/spark-defaults.conf 获取。</li>\n</ol>\n<pre><code class=\"lang-\">Shell\njps -ml | grep SparkSubmit\njinfo ${PID} | grep "spark.driver.extraClassPath"\n</code></pre>\n<p><img src=\"https://dev-media.amazoncloud.cn/1503cea79fe64dce991a23f18471ae4b_image.png\" alt=\"image.png\" /></p>\n<ol start=\"5\">\n<li>编辑 bin/kylin.sh,修改KYLIN_TOMCAT_CLASSPATH 变量,追加 kylin_driver_classpath ;保存好 bin/kylin.sh 后退出 Spark SQL CLI</li>\n</ol>\n<ul>\n<li>修改前的kylin.sh</li>\n</ul>\n<p><img src=\"https://dev-media.amazoncloud.cn/aab6dd33652843bb9b7d0bd75d41a78a_image.png\" alt=\"image.png\" /></p>\n<ul>\n<li>针对 EMR 6.5.0,修改后的sh:kylin_driver_classpath 放到最后</li>\n</ul>\n<p><img src=\"https://dev-media.amazoncloud.cn/5446567ebccd44a5aeaa31ee42edb112_image.png\" alt=\"image.png\" /></p>\n<ul>\n<li>针对 EMR 5.33.1,修改后的sh:kylin_driver_classpath 放到 $SPARK_HOME/jars 之前</li>\n</ul>\n<p><img src=\"https://dev-media.amazoncloud.cn/b87568cfc55045af88e65e7b234b6509_image.png\" alt=\"image.png\" /></p>\n<h5><a id=\"_Kylin_186\"></a><strong>配置 Kylin</strong></h5>\n<pre><code class=\"lang-\">Shell\ncd $KYLIN_HOME\nvim conf/kylin.properties \n</code></pre>\n<p><img src=\"https://dev-media.amazoncloud.cn/4dd86966c21f46b8b14e8146b17bdde5_image.png\" alt=\"image.png\" /></p>\n<h4><a id=\"_Kylin__196\"></a><strong>启动 Kylin 并验证构建</strong></h4>\n<h5><a id=\"_Kylin_198\"></a><strong>启动 Kylin</strong></h5>\n<pre><code class=\"lang-\">Shell\ncd $KYLIN_HOME\nln -s spark spark_aws # skip this step if soft link 'spark' exists \nbin/kylin.sh restart\n</code></pre>\n<p><img src=\"https://dev-media.amazoncloud.cn/4dd86966c21f46b8b14e8146b17bdde5_image.png\" alt=\"image.png\" /></p>\n<p><img src=\"https://dev-media.amazoncloud.cn/2d64ecd590814216b8c050230f8e65a9_image.png\" alt=\"image.png\" /></p>\n<h5><a id=\"_kylinsparkenginejar_Optional_211\"></a>替换 kylin-spark-engine.jar (Optional)</h5>\n<p>仅对于 4.0.1 需要操作该步骤。</p>\n<pre><code class=\"lang-\">Apache\ncd $KYLIN_HOME/tomcat/webapps/kylin/WEB-INF/lib/\nmv kylin-spark-engine-4.0.1.jar kylin-spark-engine-4.0.1.jar.bak # remove old one \ncp kylin-spark-engine-4.0.0-SNAPSHOT.jar .\n\nbin/kylin.sh restart # restart kylin to make new jar be loaded\n</code></pre>\n<h5><a id=\"_Glue__224\"></a><strong>加载 Glue 表、构建</strong></h5>\n<ul>\n<li>加载 Glue 表元数据</li>\n</ul>\n<p><img src=\"https://dev-media.amazoncloud.cn/2959c3413107490599754321ffd3a51f_image.png\" alt=\"image.png\" /></p>\n<p><img src=\"https://dev-media.amazoncloud.cn/68b1742d027f479aa82e2041a4ee9043_image.png\" alt=\"image.png\" /></p>\n<ul>\n<li>创建 Model 和 Cube,然后触发构建</li>\n</ul>\n<p><img src=\"https://dev-media.amazoncloud.cn/5190c87c02bf44bcbbe586735b951c08_image.png\" alt=\"image.png\" /></p>\n<h5><a id=\"_237\"></a><strong>验证查询</strong></h5>\n<p>切换 Kylin 使用的 Spark,重启 Kylin。</p>\n<pre><code class=\"lang-\">Shell\ncd $KYLIN_HOME\nrm spark # 'spark' is a soft link, it is point to aws spark\nln -s spark_apache spark # switch from aws spark to apache spark\nbin/kylin.sh restart\n</code></pre>\n<p>执行测试查询,查询成功</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/d8dcae4a766f412590403f8f3b092201_image.png\" alt=\"image.png\" /></p>\n<h4><a id=\"_253\"></a><strong>讨论和问答</strong></h4>\n<h5><a id=\"_SparkAmazon_Spark__Apache_Spark_255\"></a>为什么必须使用两个 Spark(Amazon Spark & Apache Spark)?</h5>\n<p>由于 Amazon Spark 内置对 Amazon Glue Catalog 的支持,并且加载表和构建引擎需要获取表,所以<strong>加载表元数据和执行构建需要使用 Amazon Spark</strong>;但是考虑到 Kylin 4.0.1 是支持 Apache <strong>Spark</strong>,并且 Amazon Spark 相对 Apache Spark 有比较大的代码修改,造成两者兼容性较差,所以查询 Cube 需要使用 Apache Spark。综上所述,需要根据 Kylin 需要执行<strong>查询任务还是构建任务,来切换所使用的的 Spark</strong>。</p>\n<p>在实际使用过程中,可以考虑 Job Node(构建任务)使用 Amazon Spark,Query Node(查询任务)使用 Apache Spark。</p>\n<h5><a id=\"_kylinsh_261\"></a>为什么需要修改 kylin.sh?</h5>\n<p>Kylin 进程作为 Spark Driver 需要通过Amazon -glue-datacatalog-spark-client.jar加载表元数据,所以这块需要修改 kylin.sh,将相关 jar 加载到 Kylin 进程的 classpath。</p>\n<h4><a id=\"_265\"></a><strong>本篇作者</strong></h4>\n<p><img src=\"https://dev-media.amazoncloud.cn/b51a831fe2da441c8690e13dc882c1f4_image.png\" alt=\"image.png\" /></p>\n<h4><a id=\"_269\"></a><strong>任耀洲</strong></h4>\n<p>Amazon 解决方案架构师,负责企业客户应用在Amazon 的架构咨询和 设计。在微服务架构设计、数据库等领域有丰富的经验</p>\n"}
Kylin 4 集成 Amazon Glue Catalog!

 0
0 0
0亚马逊云科技解决方案 基于行业客户应用场景及技术领域的解决方案
联系亚马逊云科技专家
亚马逊云科技解决方案
基于行业客户应用场景及技术领域的解决方案
联系专家

0
目录

 分享
分享 点赞
点赞 收藏
收藏 目录
目录立即注册,开启您的免费套餐
立即关注

亚马逊云开发者
公众号

User Group
公众号

亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
关于我们 
更多资源
开发者工具
更多支持
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
