{"value":"Organizations moving towards a data-driven culture embrace the use of data and machine learning (ML) in decision-making. To make ML-based decisions from data, you need your data available, accessible, clean, and in the right format to train ML models. Organizations with a multi-account architecture want to avoid situations where they must extract data from one account and load it into another for data preparation activities. Manually building and maintaining the different extract, transform, and load (ETL) jobs in different accounts adds complexity and cost, and makes it more difficult to maintain the governance, compliance, and security best practices to keep your data safe.\n\n[Amazon Redshift](https://aws.amazon.com/redshift/) is a fast, fully managed cloud data warehouse. The Amazon Redshift cross-account data sharing feature provides a simple and secure way to share fresh, complete, and consistent data in your Amazon Redshift data warehouse with any number of stakeholders in different AWS accounts. [Amazon SageMaker Data Wrangler](https://docs.aws.amazon.com/sagemaker/latest/dg/data-wrangler.html) is a capability of [Amazon SageMaker](https://aws.amazon.com/sagemaker/) that makes it faster for data scientists and engineers to prepare data for ML applications by using a visual interface. Data Wrangler allows you to explore and transform data for ML by connecting to Amazon Redshift datashares.\n\nIn this post, we walk through setting up a cross-account integration using an Amazon Redshift datashare and preparing data using Data Wrangler.\n\n### **Solution overview**\n\nWe start with two AWS accounts: a producer account with the Amazon Redshift data warehouse, and a consumer account for SageMaker ML use cases. For this post, we use the [banking dataset](https://sagemaker-sample-data-us-west-2.s3-us-west-2.amazonaws.com/autopilot/direct_marketing/bank-additional.zip). To follow along, download the dataset to your local machine. The following is a high-level overview of the workflow:\n\n1. Instantiate an Amazon Redshift RA3 cluster in the producer account and load the dataset.\n2. Create an Amazon Redshift datashare in the producer account and allow the consumer account to access the data.\n3. Access the Amazon Redshift datashare in the consumer account.\n4. Analyze and process data with Data Wrangler in the consumer account and build your data preparation workflows.\n\n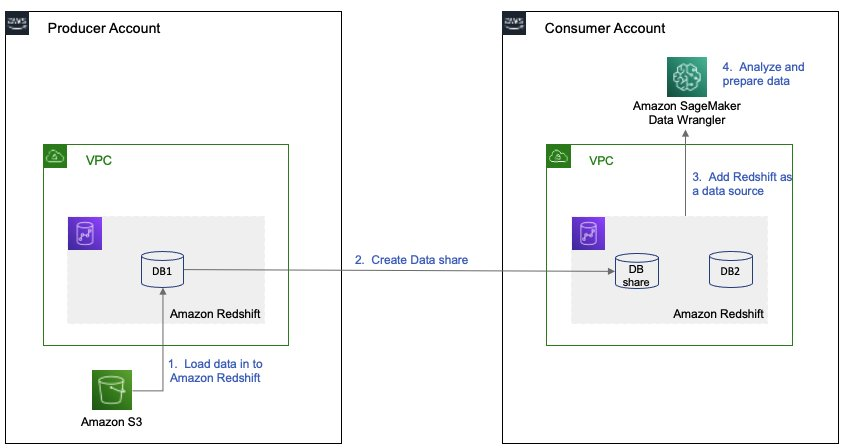\n\nBe aware of the [considerations ](https://docs.aws.amazon.com/redshift/latest/dg/considerations.html)for working with Amazon Redshift data sharing:\n\n- **Multiple AWS accounts** – You need at least two AWS accounts: a producer account and a consumer account.\n- **Cluster type** – Data sharing is supported in the RA3 cluster type. When instantiating an Amazon Redshift cluster, make sure to choose the RA3 cluster type.\n- **Encryption**– For data sharing to work, both the producer and consumer clusters must be encrypted and should be in the same AWS Region.\n- **Regions**– Cross-account data sharing is available for all Amazon Redshift [RA3 node types](https://aws.amazon.com/redshift/pricing/) in US East (N. Virginia), US East (Ohio), US West (N. California), US West (Oregon), Asia Pacific (Mumbai), Asia Pacific (Seoul), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Canada (Central), Europe (Frankfurt), Europe (Ireland), Europe (London), Europe (Paris), Europe (Stockholm), and South America (São Paulo).\n- **Pricing**– Cross-account data sharing is available across clusters that are in the same Region. There is no cost to share data. You just pay for the Amazon Redshift clusters that participate in sharing.\n\nCross-account data sharing is a two-step process. First, a producer cluster administrator creates a datashare, adds objects, and gives access to the consumer account. Then the producer account administrator authorizes sharing data for the specified consumer. You can do this from the Amazon Redshift console.\n\n### **Create an Amazon Redshift datashare in the producer account**\n\nTo create your datashare, complete the following steps:\n\n1. On the Amazon Redshift console, create an Amazon Redshift cluster.\n2. Specify **Production** and choose the RA3 node type.\n3. Under **Additional configurations**, deselect **Use defaults**.\n4. Under **Database configurations**, set up encryption for your cluster.\n\n\n\n5. After you create the cluster, import the direct marketing bank dataset. You can download from the following URL: [https://sagemaker-sample-data-us-west-2.s3-us-west-2.amazonaws.com/autopilot/direct_marketing/bank-additional.zip](https://sagemaker-sample-data-us-west-2.s3-us-west-2.amazonaws.com/autopilot/direct_marketing/bank-additional.zip).\n6. Upload ```bank-additional-full.csv``` to an [Amazon Simple Storage Service](http://aws.amazon.com/s3) (Amazon S3) bucket your cluster has access to.\n\n7. Use the Amazon Redshift query editor and run the following SQL query to copy the data into Amazon Redshift:\n\n```\ncreate table bank_additional_full (\n age char(40),\n job char(40),\n marital char(40),\n education char(40),\n default_history varchar(40),\n housing char(40),\n loan char(40),\n contact char(40),\n month char(40),\n day_of_week char(40),\n duration char(40),\n campaign char(40),\n pdays char(40),\n previous char(40),\n poutcome char(40),\n emp_var_rate char(40),\n cons_price_idx char(40),\n cons_conf_idx char(40),\n euribor3m char(40),\n nr_employed char(40),\n y char(40));\ncopy bank_additional_full\nfrom <S3 LOCATION OF THE CSV FILE>\ncredentials <CLUSTER ROLE ARN>\nregion 'us-east-1'\nformat csv\nIGNOREBLANKLINES\nIGNOREHEADER 1\n```\n\n8. Navigate to the cluster details page and on the **Datashares** tab, choose **Create datashare**.\n\n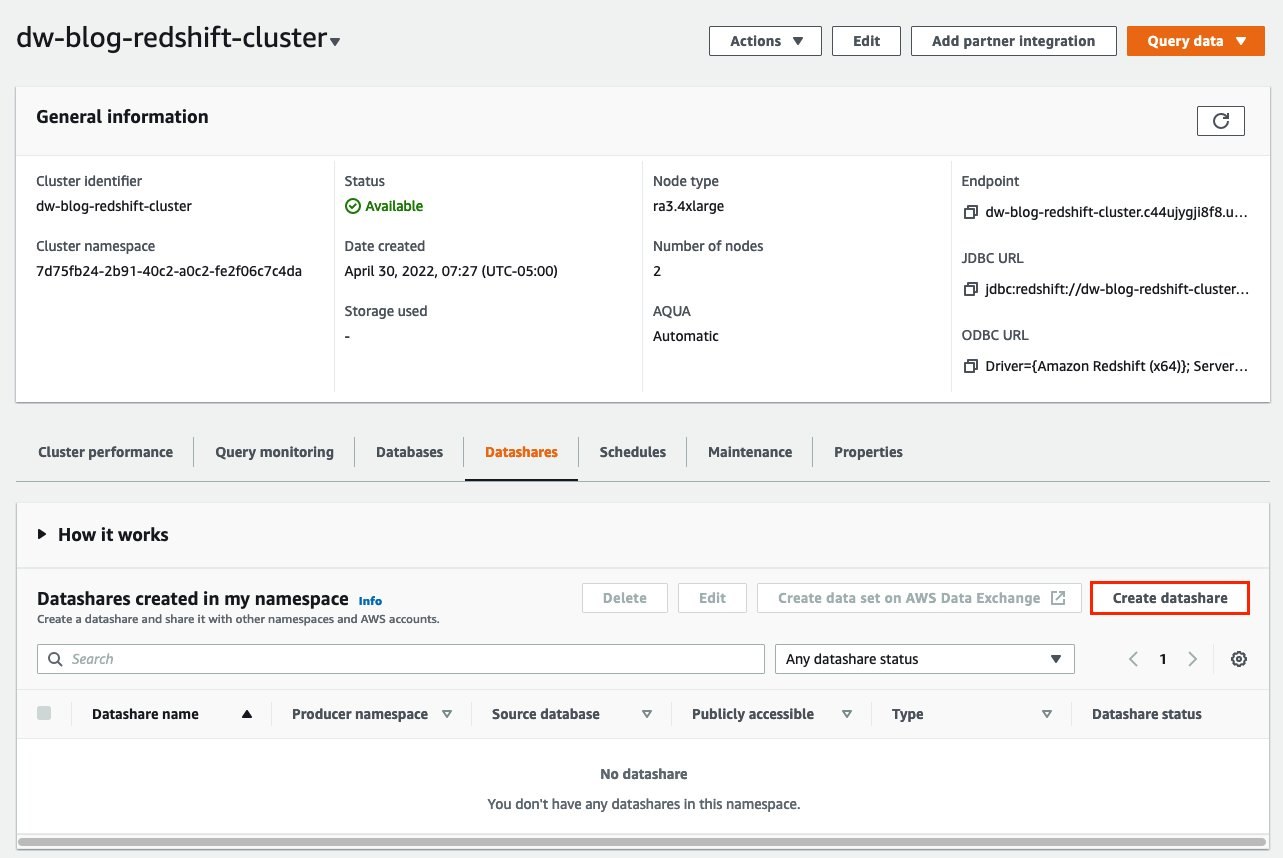\n\n9. For **Datashare name**, enter a name.\n10. For **Database name**, choose a database.\n\n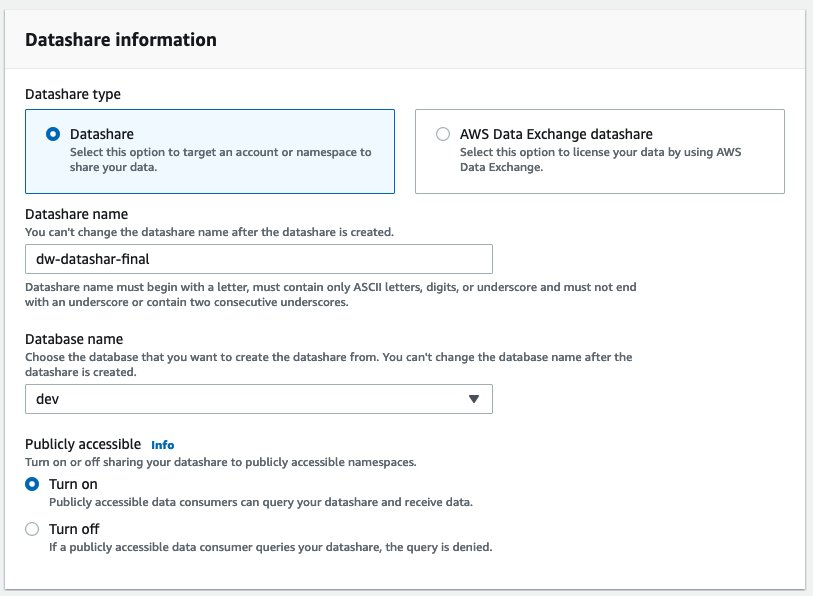\n\n11. In the **Add datashare objects** section, choose the objects from the database you want to include in the datashare.\nYou have granular control of what you choose to share with others. For simplicity, we share all the tables. In practice, you might choose one or more tables, views, or user-defined functions.\n12. Choose **Add**.\n\n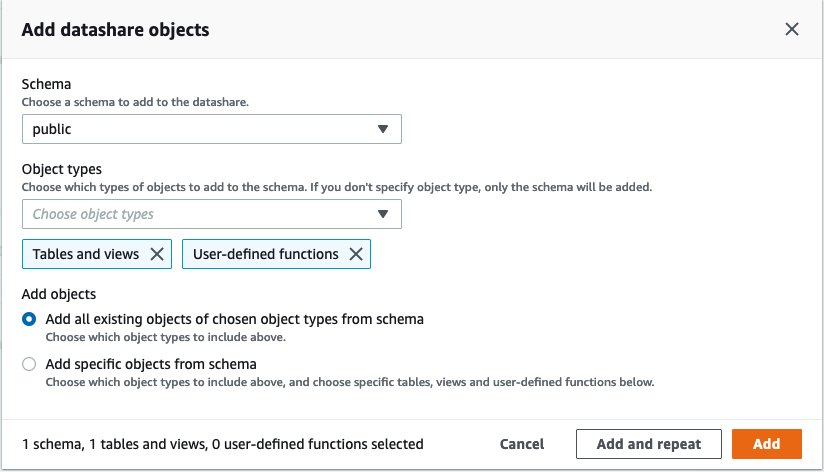\n\n13. To add data consumers, select Add AWS accounts to the datashare and add your secondary AWS account ID.\n14. Choose Create datashare.\n\n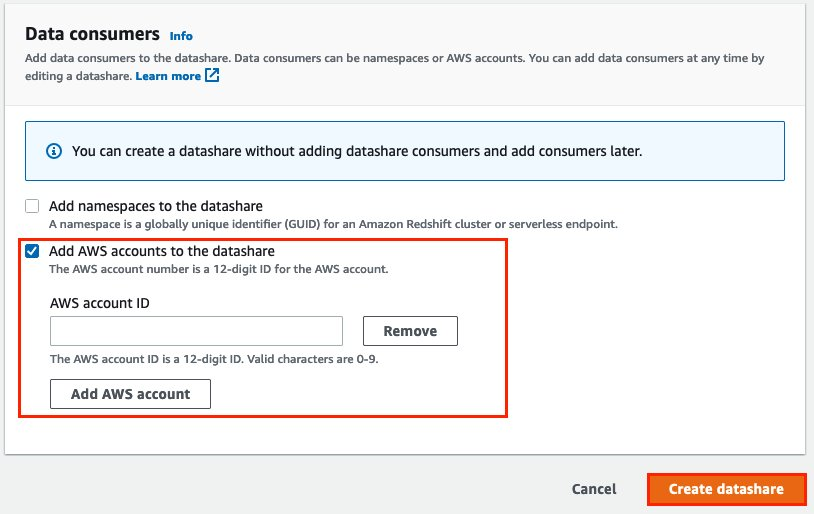\n\n15. To authorize the data consumer you just created, go to the **Datashares** page on the Amazon Redshift console and choose the new datashare.\n\n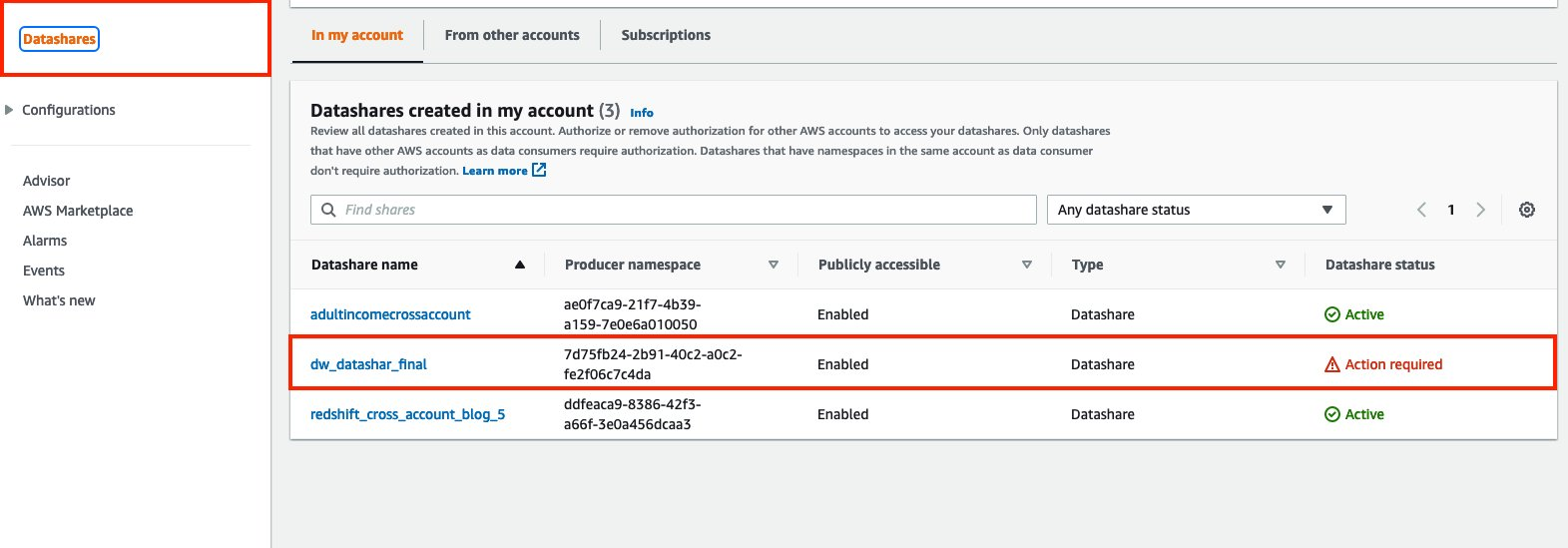\n\n16. Select the data consumer and choose Authorize.\n\nThe consumer status changes from ```Pending authorization``` to ```Authorized```.\n\n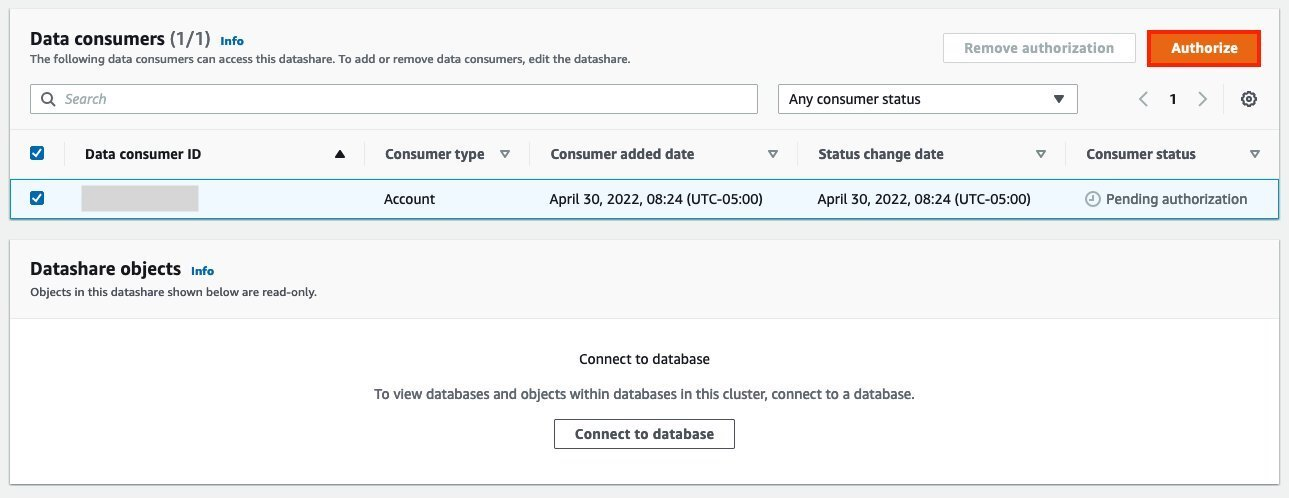\n\n### **Access the Amazon Redshift cross-account datashare in the consumer AWS account**\n\nNow that the datashare is set up, switch to your consumer AWS account to consume the datashare. Make sure you have at least one Amazon Redshift cluster created in your consumer account. The cluster has to be encrypted and in the same Region as the source.\n\n1. On the Amazon Redshift console, choose **Datashares **in the navigation pane.\n2. On the **From other accounts** tab, select the datashare you created and choose **Associate**.\n\n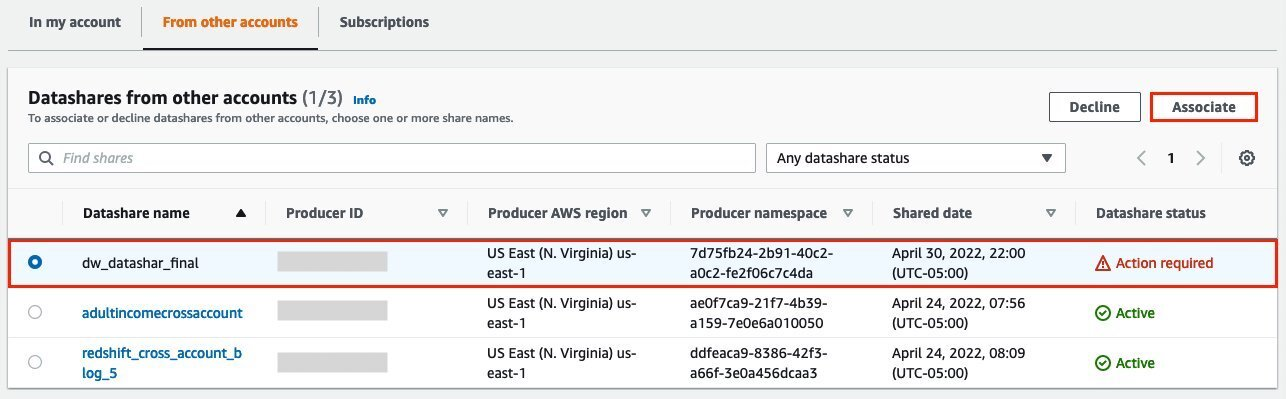\n\n3. You can associate the datashare with one or more clusters in this account or associate the datashare to the entire account so that the current and future clusters in the consumer account get access to this share.\n\n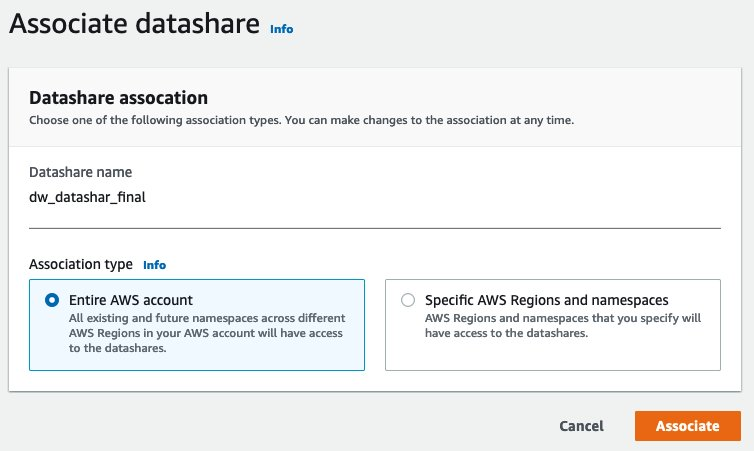\n\n4. Specify your connection details and choose **Connect**.\n\n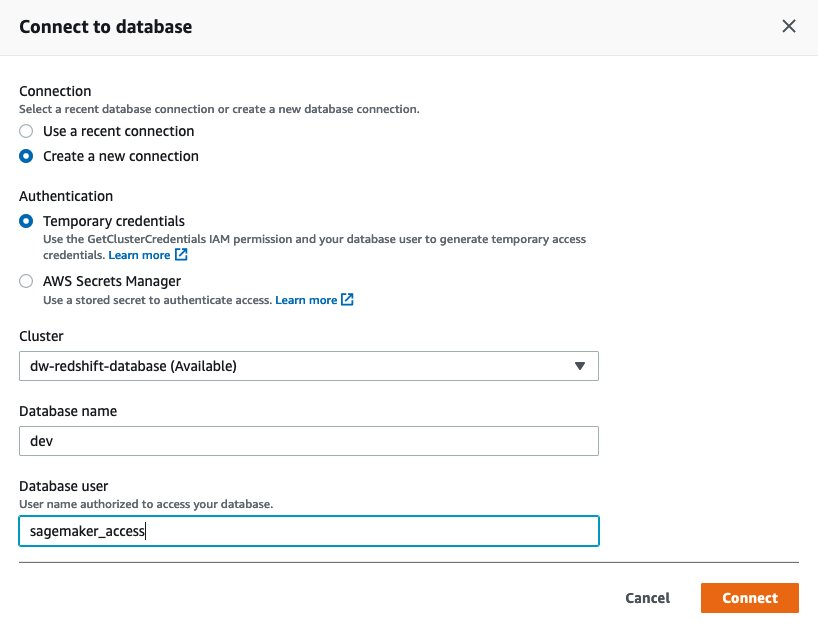\n\n5. Choose **Create database from datashare** and enter a name for your new database.\n\n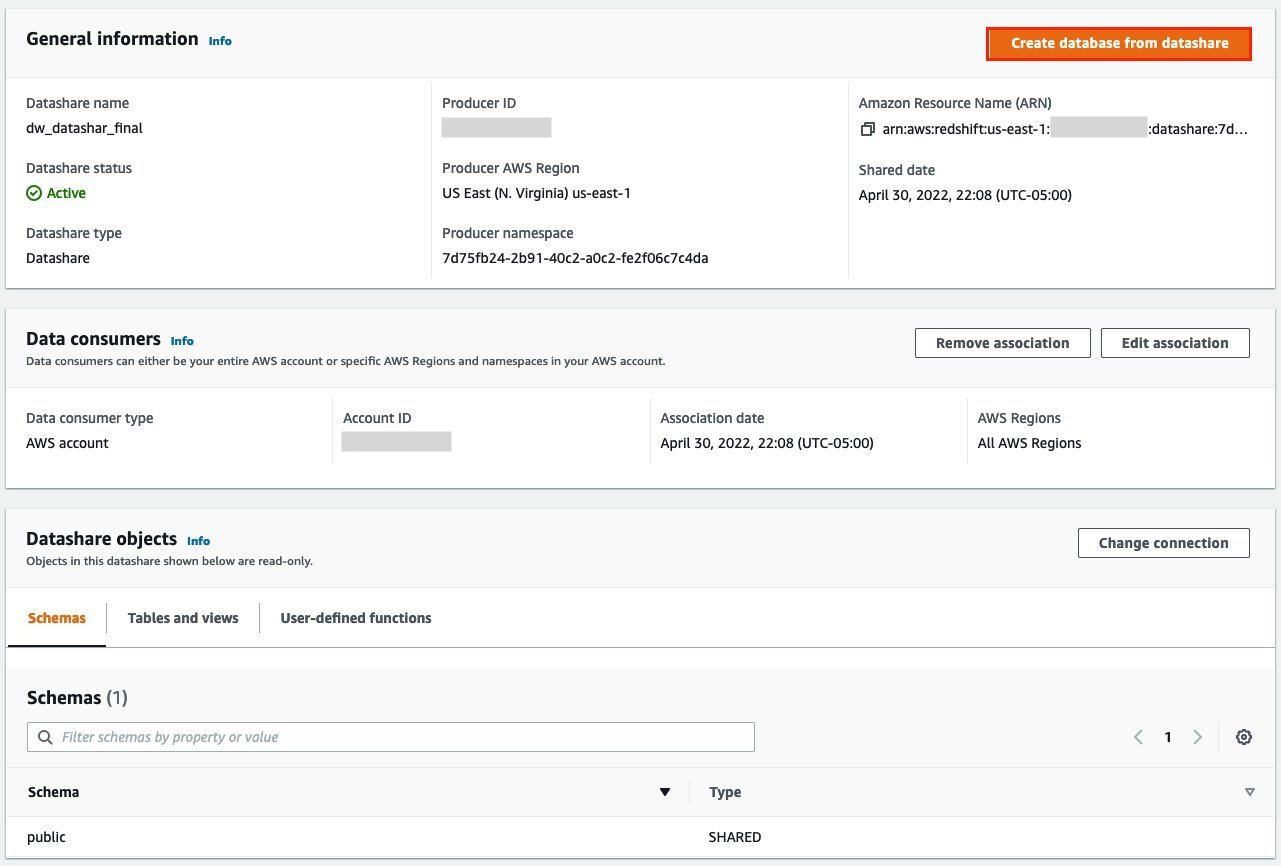\n\n6. To test the datashare, go to query editor and run queries against the new database to make sure all the objects are available as part of the datashare.\n\n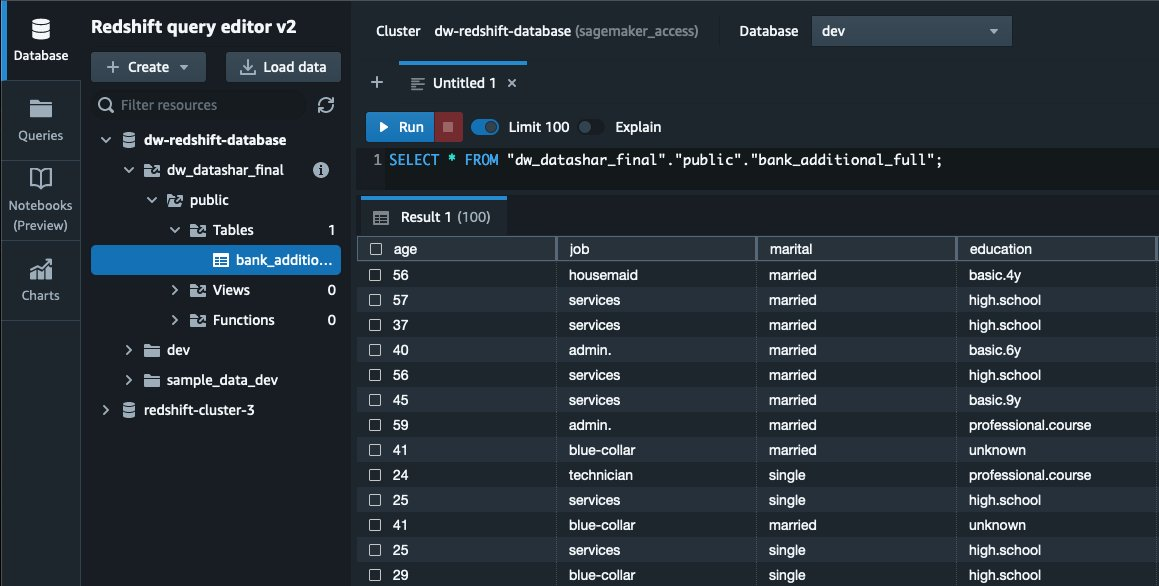\n\n### **Analyze and process data with Data Wrangler**\n\nYou can now use Data Wrangler to access the cross-account data created as a datashare in Amazon Redshift.\n\n1. Open [Amazon SageMaker Studio](https://docs.aws.amazon.com/sagemaker/latest/dg/studio.html).\n2. On the File menu, choose **New **and **Data Wrangler Flow**.\n\n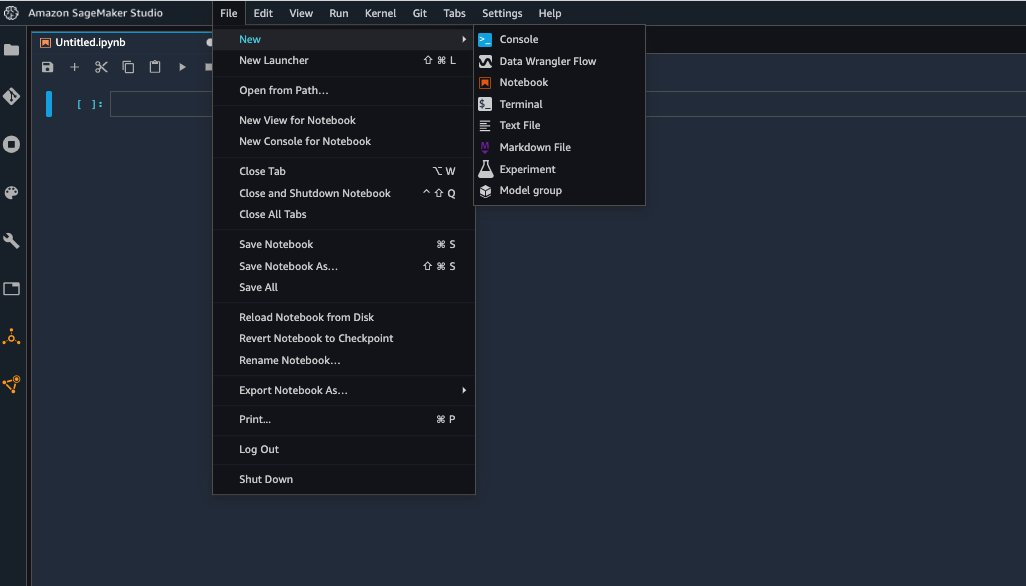\n\n3. On the **Import** tab, choose **Add data source** and **Amazon Redshift**.\n\n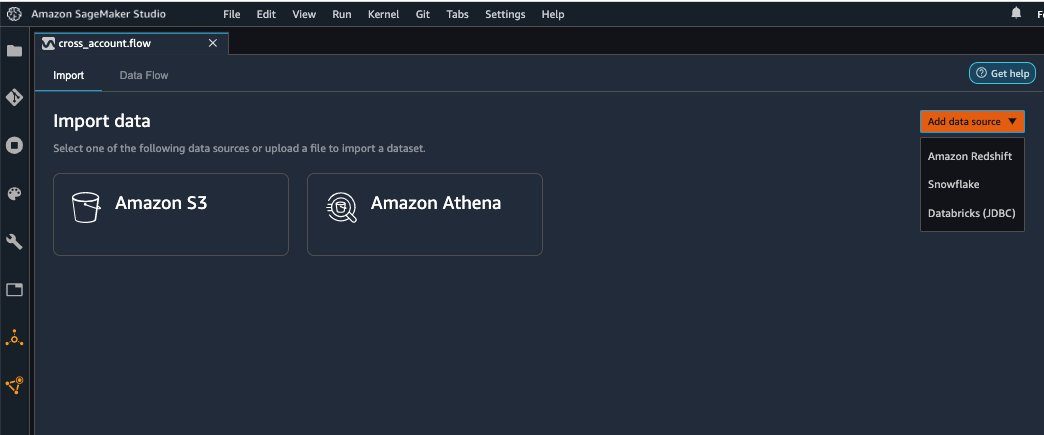\n\n4. Enter the connection details of the Amazon Redshift cluster you just created in the consumer account for the datashare.\n5. Choose **Connect**.\n6. Use the [AWS Identity and Access Management](http://aws.amazon.com/iam) (IAM) role you used for your Amazon Redshift cluster.\nNote that even though the datashare is a new database in the Amazon Redshift cluster, you can’t connect to it directly from Data Wrangler.\n\n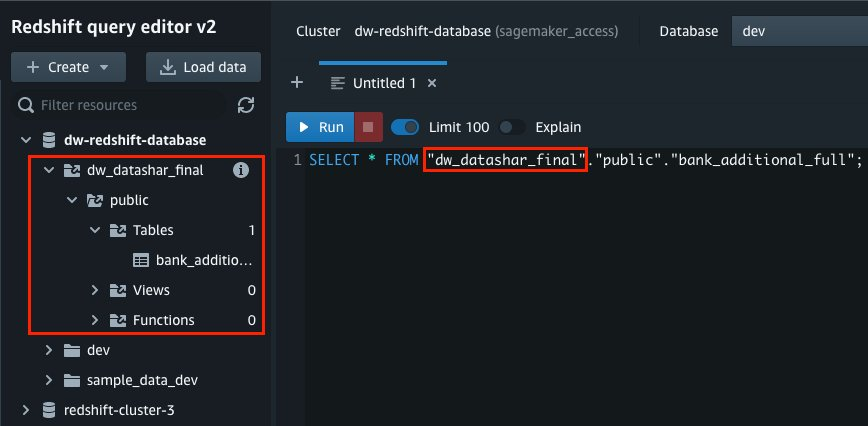\n\n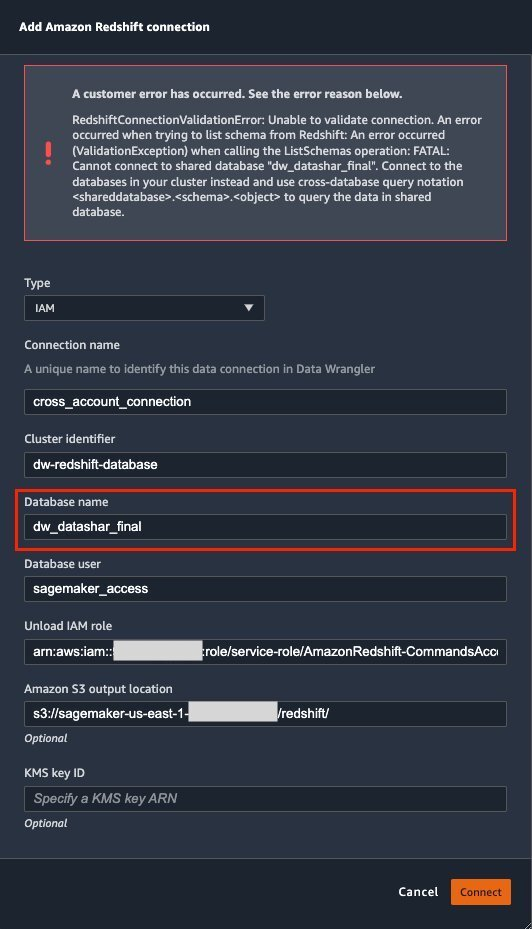\n\nThe correct way is to connect to the default cluster database first, and then use SQL to query the datashare database. Provide the required information for connecting to the default cluster database. Note that an [AWS Key Management Service](http://aws.amazon.com/kms) (AWS KMS) key ID is not required in order to connect.\n\n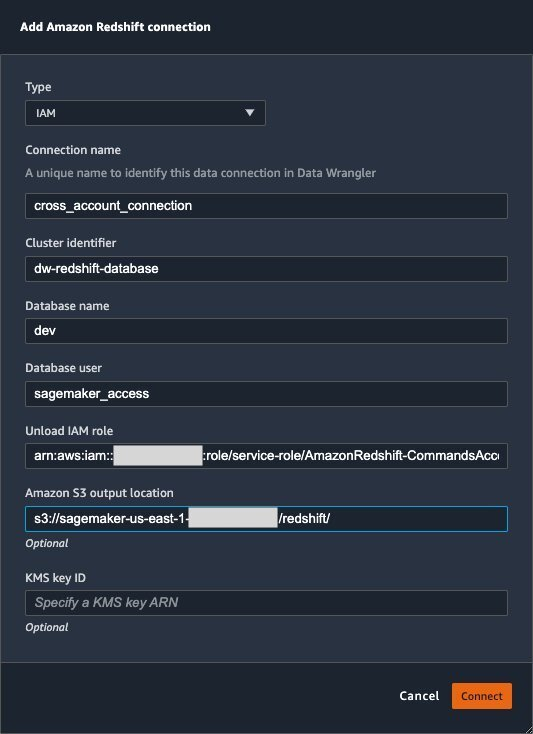\n\nData Wrangler is now connected to the Amazon Redshift instance.\n\n7. Query the data in the Amazon Redshift datashare database using a SQL editor.\n\n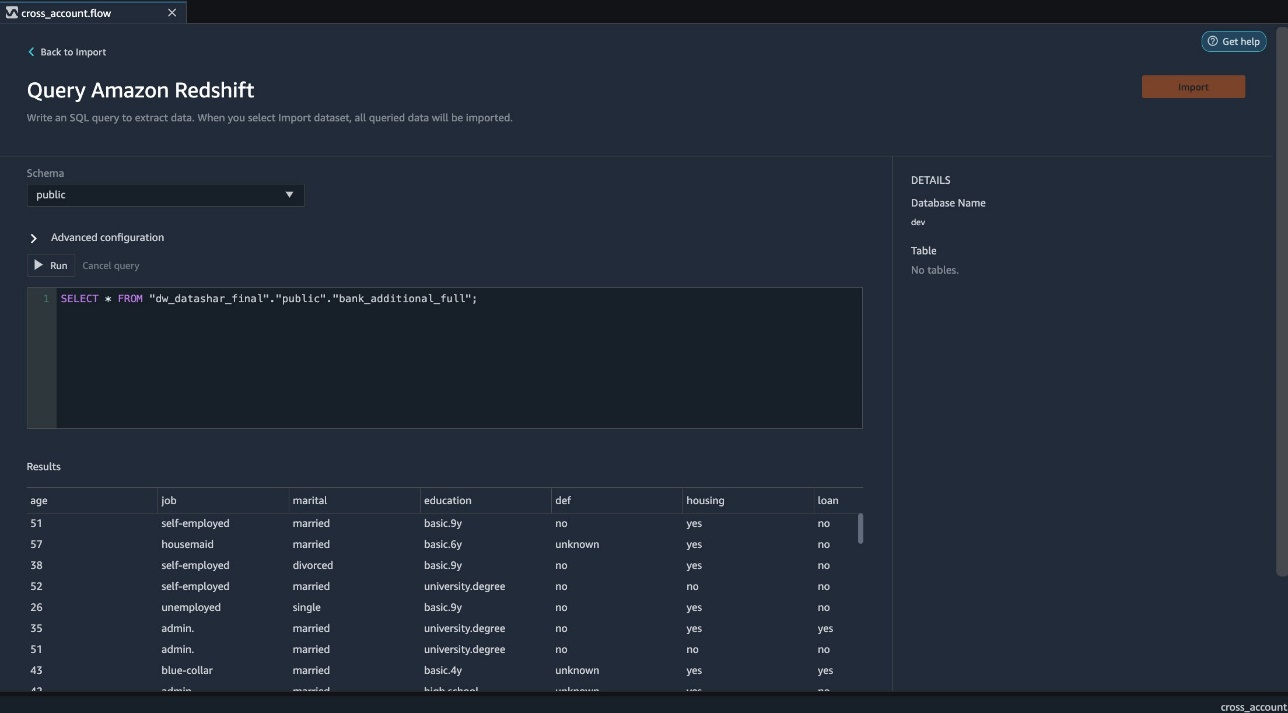\n\n8. Choose Import to **import** the dataset to Data Wrangler.\n9. Enter a name for the dataset and choose **Add**.\n\n\nYou can now see the flow on the Data Flow tab of Data Wrangler.\n\n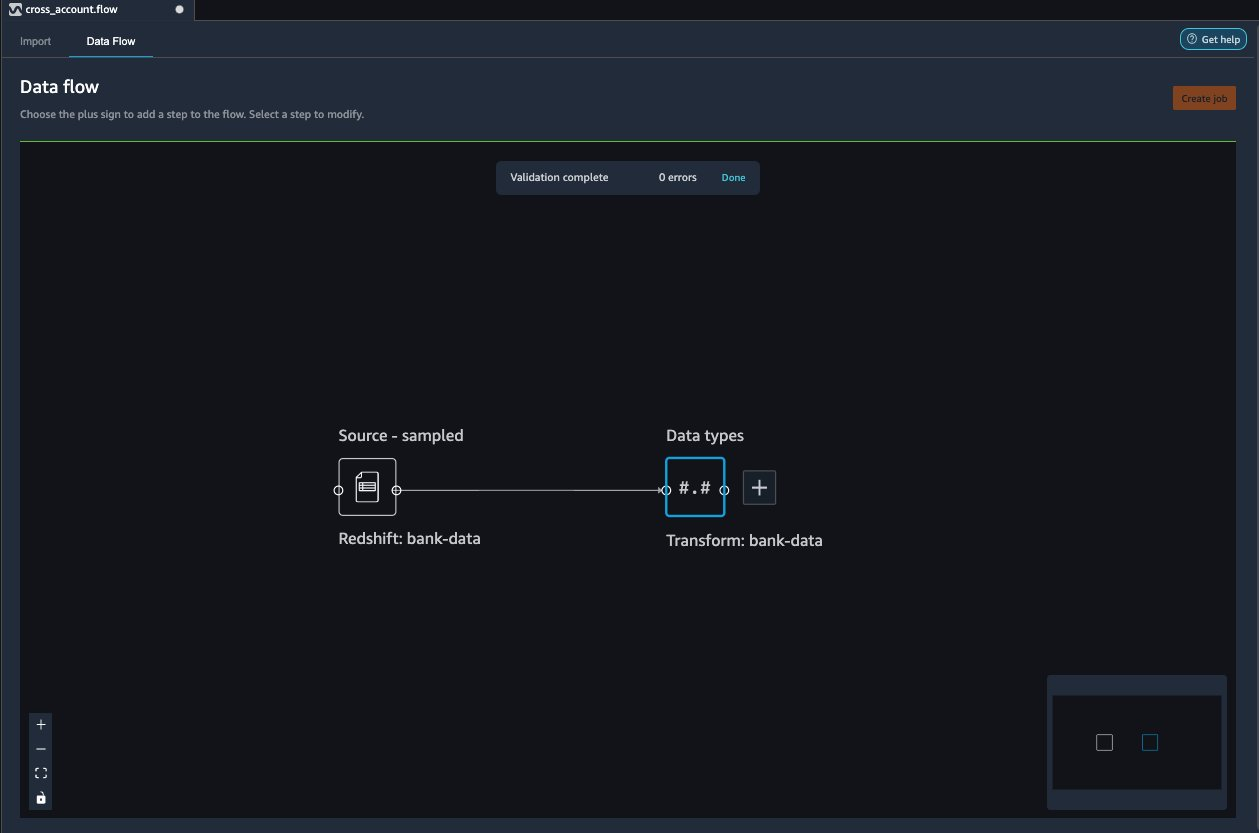\n\nAfter you have loaded the data into Data Wrangler, you can do exploratory data analysis and prepare data for ML.\n\n10. Choose the plus sign and choose **Add analysis**.\n\nData Wrangler provides built-in analyses. These include but aren’t limited to a data quality and insights report, data correlation, a pre-training bias report, a summary of your dataset, and visualizations (such as histograms and scatter plots). You can also create your own custom visualization.\n\n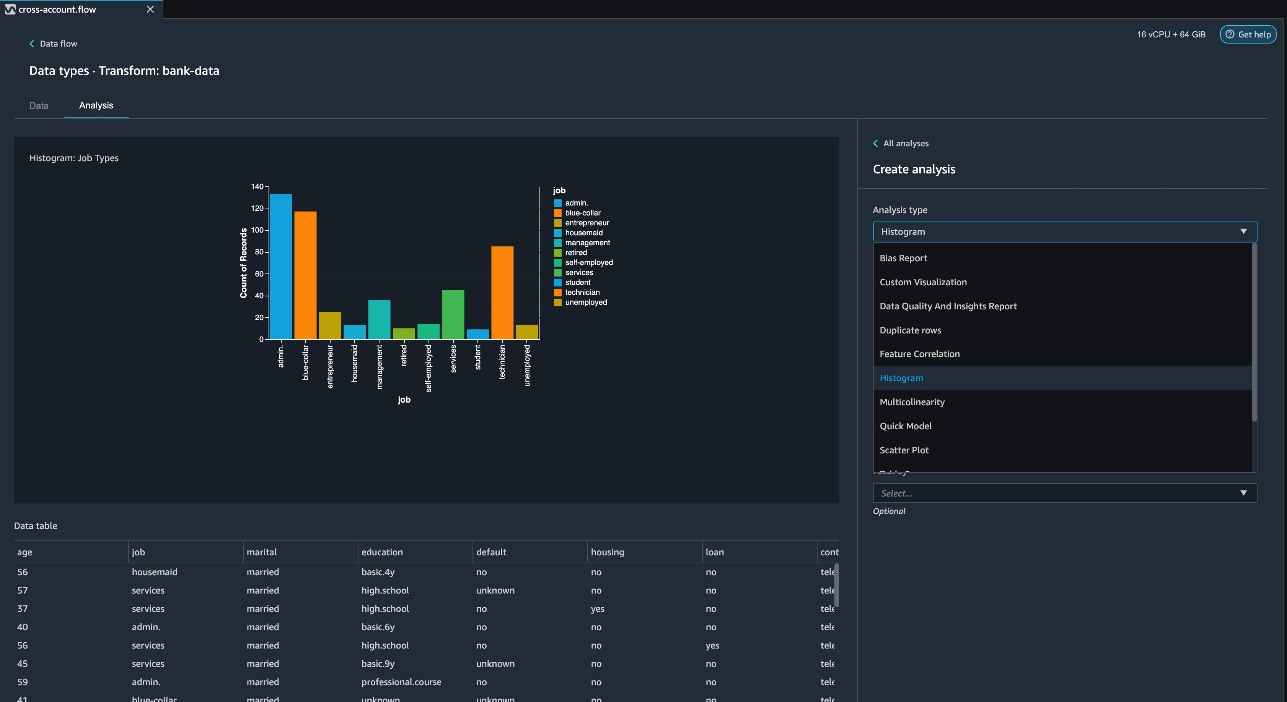\n\nYou can use the Data Quality and Insights Report to automatically generate visualizations and analyses to identify data quality issues, and recommend the right transformation required for your dataset.\n\n11. Choose **Data Quality and Insights Report**, and choose the **Target column** as **y**.\n12. Because this is a classification problem statement, for **Problem type**, select **Classification**.\n13. Choose **Create**.\n\n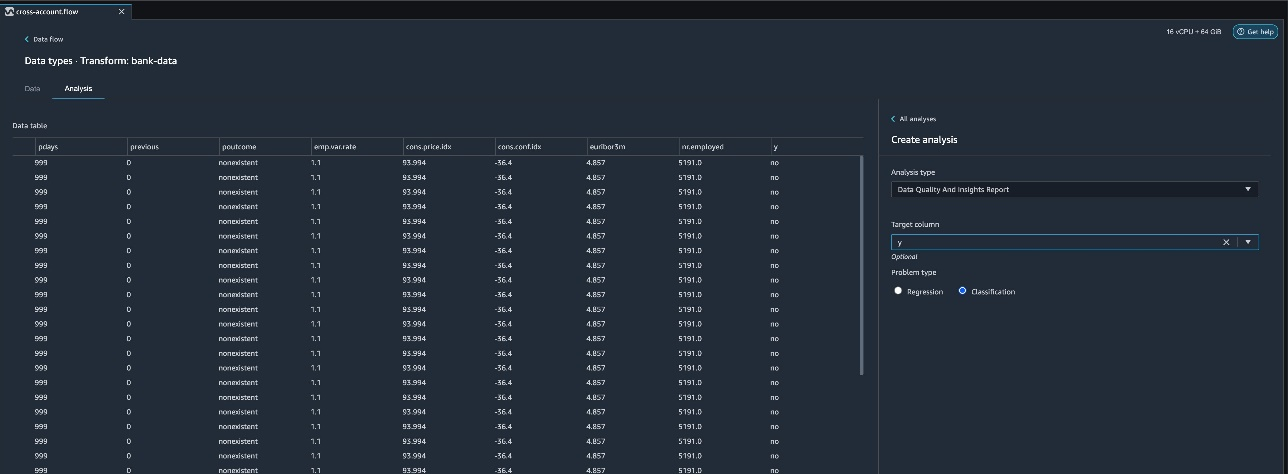\n\nData Wrangler creates a detailed report on your dataset. You can also download the report to your local machine.\n\n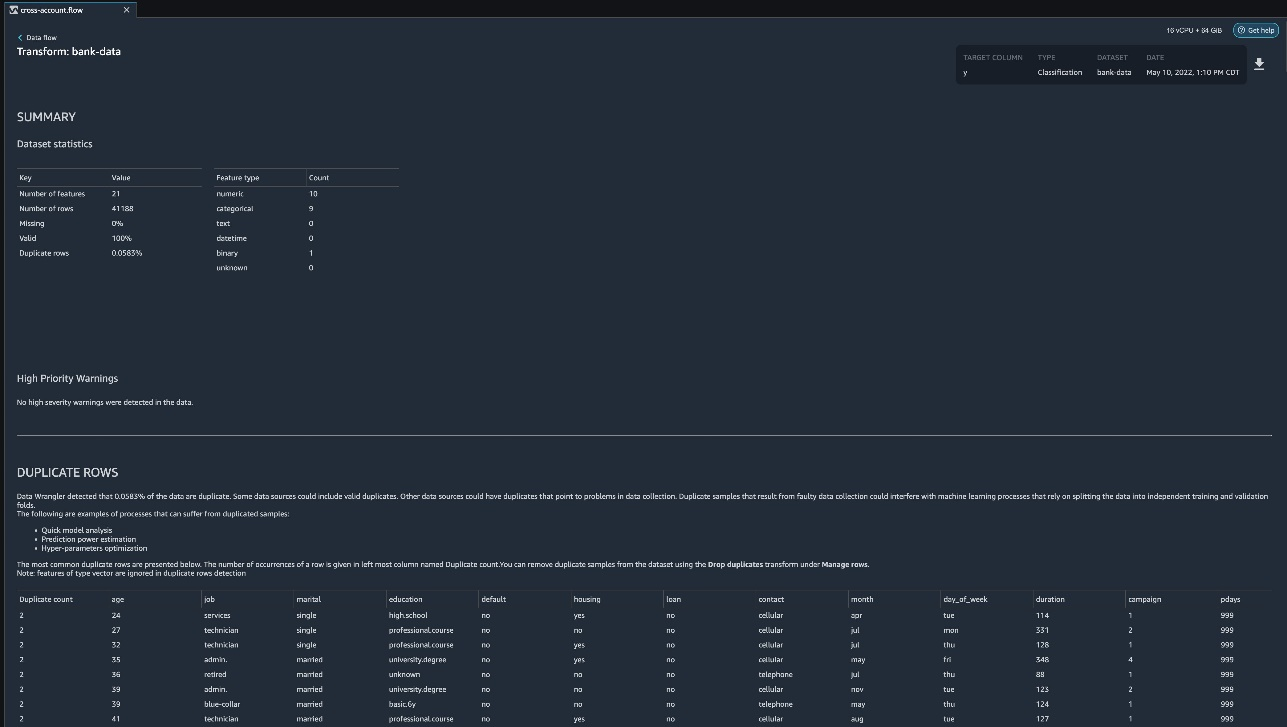\n\n14. For data preparation, choose the plus sign and choose **Add analysis**.\n15. Choose **Add step** to start building your transformations.\n\n\n\nAt the time of this writing, Data Wrangler provides over 300 built-in transformations. You can also write your own transformations using Pandas or PySpark.\n\n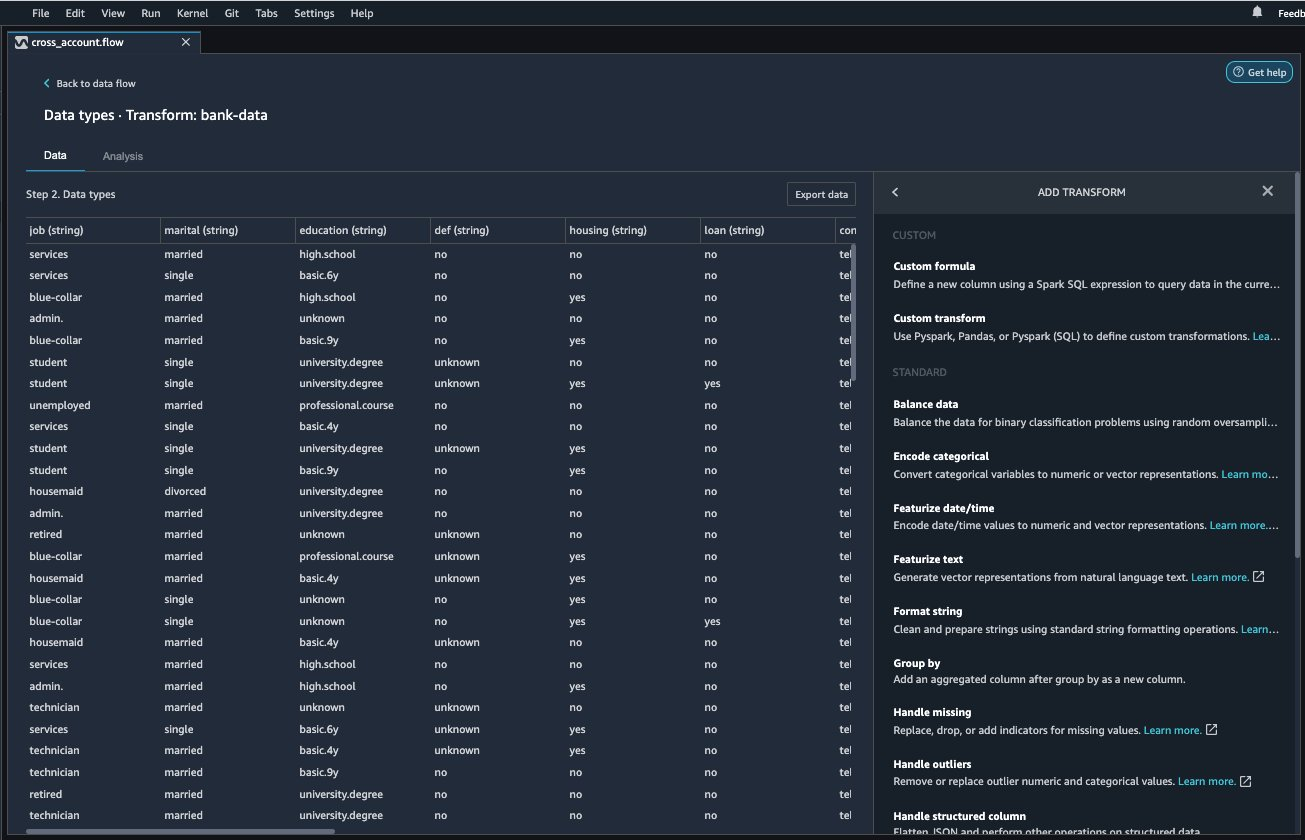\n\nYou can now start building your transforms and analysis based on your business requirement.\n\n### **Conclusion**\n\nIn this post, we explored sharing data across accounts using Amazon Redshift datashares without having to manually download and upload data. We walked through how to access the shared data using Data Wrangler and prepare the data for your ML use cases. This no-code/low-code capability of Amazon Redshift datashares and Data Wrangler accelerates training data preparation and increases the agility of data engineers and data scientists with faster iterative data preparation.\n\nTo learn more about Amazon Redshift and SageMaker, refer to the [Amazon Redshift Database Developer Guide](https://awsdocs.s3.amazonaws.com/redshift/latest/redshift-dg.pdf) and [Amazon SageMaker Documentation](https://docs.aws.amazon.com/sagemaker/index.html).\n\n### **About the Authors**\n\n\n\n**Meenakshisundaram Thandavarayan** is a Senior AI/ML specialist with AWS. He helps hi-tech strategic accounts on their AI and ML journey. He is very passionate about data-driven AI.\n\n\n\n**James Wu** is a Senior AI/ML Specialist Solution Architect at AWS. helping customers design and build AI/ML solutions. James’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. Prior to joining AWS, James was an architect, developer, and technology leader for over 10 years, including 6 years in engineering and 4 years in marketing & advertising industries.","render":"<p>Organizations moving towards a data-driven culture embrace the use of data and machine learning (ML) in decision-making. To make ML-based decisions from data, you need your data available, accessible, clean, and in the right format to train ML models. Organizations with a multi-account architecture want to avoid situations where they must extract data from one account and load it into another for data preparation activities. Manually building and maintaining the different extract, transform, and load (ETL) jobs in different accounts adds complexity and cost, and makes it more difficult to maintain the governance, compliance, and security best practices to keep your data safe.</p>\n<p><a href=\"https://aws.amazon.com/redshift/\" target=\"_blank\">Amazon Redshift</a> is a fast, fully managed cloud data warehouse. The Amazon Redshift cross-account data sharing feature provides a simple and secure way to share fresh, complete, and consistent data in your Amazon Redshift data warehouse with any number of stakeholders in different AWS accounts. <a href=\"https://docs.aws.amazon.com/sagemaker/latest/dg/data-wrangler.html\" target=\"_blank\">Amazon SageMaker Data Wrangler</a> is a capability of <a href=\"https://aws.amazon.com/sagemaker/\" target=\"_blank\">Amazon SageMaker</a> that makes it faster for data scientists and engineers to prepare data for ML applications by using a visual interface. Data Wrangler allows you to explore and transform data for ML by connecting to Amazon Redshift datashares.</p>\n<p>In this post, we walk through setting up a cross-account integration using an Amazon Redshift datashare and preparing data using Data Wrangler.</p>\n<h3><a id=\"Solution_overview_6\"></a><strong>Solution overview</strong></h3>\n<p>We start with two AWS accounts: a producer account with the Amazon Redshift data warehouse, and a consumer account for SageMaker ML use cases. For this post, we use the <a href=\"https://sagemaker-sample-data-us-west-2.s3-us-west-2.amazonaws.com/autopilot/direct_marketing/bank-additional.zip\" target=\"_blank\">banking dataset</a>. To follow along, download the dataset to your local machine. The following is a high-level overview of the workflow:</p>\n<ol>\n<li>Instantiate an Amazon Redshift RA3 cluster in the producer account and load the dataset.</li>\n<li>Create an Amazon Redshift datashare in the producer account and allow the consumer account to access the data.</li>\n<li>Access the Amazon Redshift datashare in the consumer account.</li>\n<li>Analyze and process data with Data Wrangler in the consumer account and build your data preparation workflows.</li>\n</ol>\n<p><img src=\"https://dev-media.amazoncloud.cn/080b43484e1b4293a8c8b622086ac7ac_image.png\" alt=\"image.png\" /></p>\n<p>Be aware of the <a href=\"https://docs.aws.amazon.com/redshift/latest/dg/considerations.html\" target=\"_blank\">considerations </a>for working with Amazon Redshift data sharing:</p>\n<ul>\n<li><strong>Multiple AWS accounts</strong> – You need at least two AWS accounts: a producer account and a consumer account.</li>\n<li><strong>Cluster type</strong> – Data sharing is supported in the RA3 cluster type. When instantiating an Amazon Redshift cluster, make sure to choose the RA3 cluster type.</li>\n<li><strong>Encryption</strong>– For data sharing to work, both the producer and consumer clusters must be encrypted and should be in the same AWS Region.</li>\n<li><strong>Regions</strong>– Cross-account data sharing is available for all Amazon Redshift <a href=\"https://aws.amazon.com/redshift/pricing/\" target=\"_blank\">RA3 node types</a> in US East (N. Virginia), US East (Ohio), US West (N. California), US West (Oregon), Asia Pacific (Mumbai), Asia Pacific (Seoul), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Canada (Central), Europe (Frankfurt), Europe (Ireland), Europe (London), Europe (Paris), Europe (Stockholm), and South America (São Paulo).</li>\n<li><strong>Pricing</strong>– Cross-account data sharing is available across clusters that are in the same Region. There is no cost to share data. You just pay for the Amazon Redshift clusters that participate in sharing.</li>\n</ul>\n<p>Cross-account data sharing is a two-step process. First, a producer cluster administrator creates a datashare, adds objects, and gives access to the consumer account. Then the producer account administrator authorizes sharing data for the specified consumer. You can do this from the Amazon Redshift console.</p>\n<h3><a id=\"Create_an_Amazon_Redshift_datashare_in_the_producer_account_27\"></a><strong>Create an Amazon Redshift datashare in the producer account</strong></h3>\n<p>To create your datashare, complete the following steps:</p>\n<ol>\n<li>On the Amazon Redshift console, create an Amazon Redshift cluster.</li>\n<li>Specify <strong>Production</strong> and choose the RA3 node type.</li>\n<li>Under <strong>Additional configurations</strong>, deselect <strong>Use defaults</strong>.</li>\n<li>Under <strong>Database configurations</strong>, set up encryption for your cluster.</li>\n</ol>\n<p><img src=\"https://dev-media.amazoncloud.cn/534e3aca056b4afdbb88951ed83f9d33_image.png\" alt=\"image.png\" /></p>\n<ol start=\"5\">\n<li>\n<p>After you create the cluster, import the direct marketing bank dataset. You can download from the following URL: <a href=\"https://sagemaker-sample-data-us-west-2.s3-us-west-2.amazonaws.com/autopilot/direct_marketing/bank-additional.zip\" target=\"_blank\">https://sagemaker-sample-data-us-west-2.s3-us-west-2.amazonaws.com/autopilot/direct_marketing/bank-additional.zip</a>.</p>\n</li>\n<li>\n<p>Upload <code>bank-additional-full.csv</code> to an <a href=\"http://aws.amazon.com/s3\" target=\"_blank\">Amazon Simple Storage Service</a> (Amazon S3) bucket your cluster has access to.</p>\n</li>\n<li>\n<p>Use the Amazon Redshift query editor and run the following SQL query to copy the data into Amazon Redshift:</p>\n</li>\n</ol>\n<pre><code class=\"lang-\">create table bank_additional_full (\n age char(40),\n job char(40),\n marital char(40),\n education char(40),\n default_history varchar(40),\n housing char(40),\n loan char(40),\n contact char(40),\n month char(40),\n day_of_week char(40),\n duration char(40),\n campaign char(40),\n pdays char(40),\n previous char(40),\n poutcome char(40),\n emp_var_rate char(40),\n cons_price_idx char(40),\n cons_conf_idx char(40),\n euribor3m char(40),\n nr_employed char(40),\n y char(40));\ncopy bank_additional_full\nfrom <S3 LOCATION OF THE CSV FILE>\ncredentials <CLUSTER ROLE ARN>\nregion 'us-east-1'\nformat csv\nIGNOREBLANKLINES\nIGNOREHEADER 1\n</code></pre>\n<ol start=\"8\">\n<li>Navigate to the cluster details page and on the <strong>Datashares</strong> tab, choose <strong>Create datashare</strong>.</li>\n</ol>\n<p><img src=\"https://dev-media.amazoncloud.cn/cfdfab08481b478ea765dbeb748d4dda_image.png\" alt=\"image.png\" /></p>\n<ol start=\"9\">\n<li>For <strong>Datashare name</strong>, enter a name.</li>\n<li>For <strong>Database name</strong>, choose a database.</li>\n</ol>\n<p><img src=\"https://dev-media.amazoncloud.cn/2af21cdb46674e37a6fd17a0a138c3d0_image.png\" alt=\"image.png\" /></p>\n<ol start=\"11\">\n<li>In the <strong>Add datashare objects</strong> section, choose the objects from the database you want to include in the datashare.<br />\nYou have granular control of what you choose to share with others. For simplicity, we share all the tables. In practice, you might choose one or more tables, views, or user-defined functions.</li>\n<li>Choose <strong>Add</strong>.</li>\n</ol>\n<p><img src=\"https://dev-media.amazoncloud.cn/dc9646f662c94a0dab1d73444f576b3f_image.png\" alt=\"image.png\" /></p>\n<ol start=\"13\">\n<li>To add data consumers, select Add AWS accounts to the datashare and add your secondary AWS account ID.</li>\n<li>Choose Create datashare.</li>\n</ol>\n<p><img src=\"https://dev-media.amazoncloud.cn/a1663be0941c4eaeb322b912954475f8_image.png\" alt=\"image.png\" /></p>\n<ol start=\"15\">\n<li>To authorize the data consumer you just created, go to the <strong>Datashares</strong> page on the Amazon Redshift console and choose the new datashare.</li>\n</ol>\n<p><img src=\"https://dev-media.amazoncloud.cn/71771e6163f148368ec55080b14d1a60_image.png\" alt=\"image.png\" /></p>\n<ol start=\"16\">\n<li>Select the data consumer and choose Authorize.</li>\n</ol>\n<p>The consumer status changes from <code>Pending authorization</code> to <code>Authorized</code>.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/1bf75aa4f4ca4e87b0f16661bf4c470e_image.png\" alt=\"image.png\" /></p>\n<h3><a id=\"Access_the_Amazon_Redshift_crossaccount_datashare_in_the_consumer_AWS_account_105\"></a><strong>Access the Amazon Redshift cross-account datashare in the consumer AWS account</strong></h3>\n<p>Now that the datashare is set up, switch to your consumer AWS account to consume the datashare. Make sure you have at least one Amazon Redshift cluster created in your consumer account. The cluster has to be encrypted and in the same Region as the source.</p>\n<ol>\n<li>On the Amazon Redshift console, choose **Datashares **in the navigation pane.</li>\n<li>On the <strong>From other accounts</strong> tab, select the datashare you created and choose <strong>Associate</strong>.</li>\n</ol>\n<p><img src=\"https://dev-media.amazoncloud.cn/73e0a7ed37434acc8962f65c228c7225_image.png\" alt=\"image.png\" /></p>\n<ol start=\"3\">\n<li>You can associate the datashare with one or more clusters in this account or associate the datashare to the entire account so that the current and future clusters in the consumer account get access to this share.</li>\n</ol>\n<p><img src=\"https://dev-media.amazoncloud.cn/0b5118efabc14f04b8ccab3fe002ed0b_image.png\" alt=\"image.png\" /></p>\n<ol start=\"4\">\n<li>Specify your connection details and choose <strong>Connect</strong>.</li>\n</ol>\n<p><img src=\"https://dev-media.amazoncloud.cn/7031fea0cf8b48778a6e74f4d1a32443_image.png\" alt=\"image.png\" /></p>\n<ol start=\"5\">\n<li>Choose <strong>Create database from datashare</strong> and enter a name for your new database.</li>\n</ol>\n<p><img src=\"https://dev-media.amazoncloud.cn/0b9507b8da974f6dab62d2e1e2e5429f_image.png\" alt=\"image.png\" /></p>\n<ol start=\"6\">\n<li>To test the datashare, go to query editor and run queries against the new database to make sure all the objects are available as part of the datashare.</li>\n</ol>\n<p><img src=\"https://dev-media.amazoncloud.cn/2cd47247498140a7bf2352b843e2ef7b_image.png\" alt=\"image.png\" /></p>\n<h3><a id=\"Analyze_and_process_data_with_Data_Wrangler_130\"></a><strong>Analyze and process data with Data Wrangler</strong></h3>\n<p>You can now use Data Wrangler to access the cross-account data created as a datashare in Amazon Redshift.</p>\n<ol>\n<li>Open <a href=\"https://docs.aws.amazon.com/sagemaker/latest/dg/studio.html\" target=\"_blank\">Amazon SageMaker Studio</a>.</li>\n<li>On the File menu, choose **New **and <strong>Data Wrangler Flow</strong>.</li>\n</ol>\n<p><img src=\"https://dev-media.amazoncloud.cn/4a4356424eac4bacac3c4c477d806240_image.png\" alt=\"image.png\" /></p>\n<ol start=\"3\">\n<li>On the <strong>Import</strong> tab, choose <strong>Add data source</strong> and <strong>Amazon Redshift</strong>.</li>\n</ol>\n<p><img src=\"https://dev-media.amazoncloud.cn/11230b2544ab4c2cbb7e8692419e07ee_image.png\" alt=\"image.png\" /></p>\n<ol start=\"4\">\n<li>Enter the connection details of the Amazon Redshift cluster you just created in the consumer account for the datashare.</li>\n<li>Choose <strong>Connect</strong>.</li>\n<li>Use the <a href=\"http://aws.amazon.com/iam\" target=\"_blank\">AWS Identity and Access Management</a> (IAM) role you used for your Amazon Redshift cluster.<br />\nNote that even though the datashare is a new database in the Amazon Redshift cluster, you can’t connect to it directly from Data Wrangler.</li>\n</ol>\n<p><img src=\"https://dev-media.amazoncloud.cn/3a1819b333c041d9b05ac3de140ca331_image.png\" alt=\"image.png\" /></p>\n<p><img src=\"https://dev-media.amazoncloud.cn/1f0b3f5553e24b22a9c65ff75211151d_image.png\" alt=\"image.png\" /></p>\n<p>The correct way is to connect to the default cluster database first, and then use SQL to query the datashare database. Provide the required information for connecting to the default cluster database. Note that an <a href=\"http://aws.amazon.com/kms\" target=\"_blank\">AWS Key Management Service</a> (AWS KMS) key ID is not required in order to connect.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/c77a82c45a6e4dcfaa8ee7fcacdc579d_image.png\" alt=\"image.png\" /></p>\n<p>Data Wrangler is now connected to the Amazon Redshift instance.</p>\n<ol start=\"7\">\n<li>Query the data in the Amazon Redshift datashare database using a SQL editor.</li>\n</ol>\n<p><img src=\"https://dev-media.amazoncloud.cn/bc19c2a773a1442d84df66c1d5b75d8b_image.png\" alt=\"image.png\" /></p>\n<ol start=\"8\">\n<li>Choose Import to <strong>import</strong> the dataset to Data Wrangler.</li>\n<li>Enter a name for the dataset and choose <strong>Add</strong>.<br />\n<img src=\"https://dev-media.amazoncloud.cn/375903b75e084ad8ba900517f9d63b36_image.png\" alt=\"image.png\" /></li>\n</ol>\n<p>You can now see the flow on the Data Flow tab of Data Wrangler.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/12f99cce5a2f470386e0963add98ce16_image.png\" alt=\"image.png\" /></p>\n<p>After you have loaded the data into Data Wrangler, you can do exploratory data analysis and prepare data for ML.</p>\n<ol start=\"10\">\n<li>Choose the plus sign and choose <strong>Add analysis</strong>.</li>\n</ol>\n<p>Data Wrangler provides built-in analyses. These include but aren’t limited to a data quality and insights report, data correlation, a pre-training bias report, a summary of your dataset, and visualizations (such as histograms and scatter plots). You can also create your own custom visualization.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/819a5bcf22e04c0da8f1b154830b470f_image.png\" alt=\"image.png\" /></p>\n<p>You can use the Data Quality and Insights Report to automatically generate visualizations and analyses to identify data quality issues, and recommend the right transformation required for your dataset.</p>\n<ol start=\"11\">\n<li>Choose <strong>Data Quality and Insights Report</strong>, and choose the <strong>Target column</strong> as <strong>y</strong>.</li>\n<li>Because this is a classification problem statement, for <strong>Problem type</strong>, select <strong>Classification</strong>.</li>\n<li>Choose <strong>Create</strong>.</li>\n</ol>\n<p><img src=\"https://dev-media.amazoncloud.cn/5ce34ecd3a164c00af8bb29dbcb2cd6a_image.png\" alt=\"image.png\" /></p>\n<p>Data Wrangler creates a detailed report on your dataset. You can also download the report to your local machine.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/8eb048f898ab46ffaff30398839dc05d_image.png\" alt=\"image.png\" /></p>\n<ol start=\"14\">\n<li>For data preparation, choose the plus sign and choose <strong>Add analysis</strong>.</li>\n<li>Choose <strong>Add step</strong> to start building your transformations.</li>\n</ol>\n<p><img src=\"https://dev-media.amazoncloud.cn/75c72a1e82464897a89855798cdb3042_image.png\" alt=\"image.png\" /></p>\n<p>At the time of this writing, Data Wrangler provides over 300 built-in transformations. You can also write your own transformations using Pandas or PySpark.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/30a7fe3cfff749b78274426b049f6a29_image.png\" alt=\"image.png\" /></p>\n<p>You can now start building your transforms and analysis based on your business requirement.</p>\n<h3><a id=\"Conclusion_201\"></a><strong>Conclusion</strong></h3>\n<p>In this post, we explored sharing data across accounts using Amazon Redshift datashares without having to manually download and upload data. We walked through how to access the shared data using Data Wrangler and prepare the data for your ML use cases. This no-code/low-code capability of Amazon Redshift datashares and Data Wrangler accelerates training data preparation and increases the agility of data engineers and data scientists with faster iterative data preparation.</p>\n<p>To learn more about Amazon Redshift and SageMaker, refer to the <a href=\"https://awsdocs.s3.amazonaws.com/redshift/latest/redshift-dg.pdf\" target=\"_blank\">Amazon Redshift Database Developer Guide</a> and <a href=\"https://docs.aws.amazon.com/sagemaker/index.html\" target=\"_blank\">Amazon SageMaker Documentation</a>.</p>\n<h3><a id=\"About_the_Authors_207\"></a><strong>About the Authors</strong></h3>\n<p><img src=\"https://dev-media.amazoncloud.cn/fffffe2ec8bf4457900b87a116602dc5_image.png\" alt=\"image.png\" /></p>\n<p><strong>Meenakshisundaram Thandavarayan</strong> is a Senior AI/ML specialist with AWS. He helps hi-tech strategic accounts on their AI and ML journey. He is very passionate about data-driven AI.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/43aa5605687f4427ad0b16f3c25e248d_image.png\" alt=\"image.png\" /></p>\n<p><strong>James Wu</strong> is a Senior AI/ML Specialist Solution Architect at AWS. helping customers design and build AI/ML solutions. James’s work covers a wide range of ML use cases, with a primary interest in computer vision, deep learning, and scaling ML across the enterprise. Prior to joining AWS, James was an architect, developer, and technology leader for over 10 years, including 6 years in engineering and 4 years in marketing & advertising industries.</p>\n"}
Import data from cross-account Amazon Redshift in Amazon SageMaker Data Wrangler for exploratory data analysis and data preparation
海外精选

海外精选的内容汇集了全球优质的亚马逊云科技相关技术内容。同时,内容中提到的“AWS”
是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。

 0
0 0
0亚马逊云科技解决方案 基于行业客户应用场景及技术领域的解决方案
联系亚马逊云科技专家
亚马逊云科技解决方案
基于行业客户应用场景及技术领域的解决方案
联系专家

0
目录

 分享
分享 点赞
点赞 收藏
收藏 目录
目录立即注册,开启您的免费套餐
立即关注

亚马逊云开发者
公众号

User Group
公众号

亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
关于我们 
更多资源
开发者工具
更多支持
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
