{"value":"If you use the default lifecycle configuration for your domain or user profile in [Amazon SageMaker Studio](https://docs.aws.amazon.com/sagemaker/latest/dg/studio.html) and use [Amazon SageMaker Data Wrangler](https://aws.amazon.com/cn/sagemaker/data-wrangler/) for data preparation, then this post is for you. In this post, we show how you can create a Data Wrangler flow and use it for data preparation in a Studio environment with a default lifecycle configuration.\n\nData Wrangler is a capability of[ Amazon SageMaker](https://aws.amazon.com/cn/sagemaker/) that makes it faster for data scientists and engineers to prepare data for machine learning (ML) applications via a visual interface. Data preparation is a crucial step of the ML lifecycle, and Data Wrangler provides an end-to-end solution to import, explore, transform, featurize, and process data for ML in a visual, low-code experience. It lets you easily and quickly connect to AWS components like [Amazon Simple Storage Service](https://aws.amazon.com/cn/s3/) (Amazon S3), [Amazon Athena](https://aws.amazon.com/cn/athena/?whats-new-cards.sort-by=item.additionalFields.postDateTime&whats-new-cards.sort-order=desc), [Amazon Redshift](https://aws.amazon.com/cn/redshift/), and [AWS Lake Formation](https://aws.amazon.com/cn/lake-formation/?whats-new-cards.sort-by=item.additionalFields.postDateTime&whats-new-cards.sort-order=desc), and external sources like Snowflake and DataBricks DeltaLake. Data Wrangler supports standard data types such as CSV, JSON, ORC, and Parquet.\n\nStudio apps are interactive applications that enable Studio’s visual interface, code authoring, and run experience. App types can be either Jupyter Server or Kernel Gateway:\n\n- Jupyter Server – Enables access to the visual interface for Studio. Every user in Studio gets their own Jupyter Server app.\n- Kernel Gateway – Enables access to the code run environment and kernels for your Studio notebooks and terminals. For more information, see [Jupyter Kernel Gateway](https://jupyter-kernel-gateway.readthedocs.io/en/latest/).\n\n[Lifecycle configurations](https://docs.aws.amazon.com/sagemaker/latest/dg/studio-lcc.html) (LCCs) are shell scripts to automate customization for your Studio environments, such as installing JupyterLab extensions, preloading datasets, and setting up source code repositories. LCC scripts are triggered by Studio lifecycle events, such as starting a new Studio notebook. To set a lifecycle configuration as the default for your domain or user profile programmatically, you can create a new resource or update an existing resource. To associate a lifecycle configuration as a default, you first need to create a lifecycle configuration following the steps in [Creating and Associating a Lifecycle Configuration](https://docs.aws.amazon.com/sagemaker/latest/dg/studio-lcc-create.html)\n\nNote: Default lifecycle configurations set up at the domain level are inherited by all users, whereas those set up at the user level are scoped to a specific user. If you apply both domain-level and user profile-level lifecycle configurations at the same time, the user profile-level lifecycle configuration takes precedence and is applied to the application irrespective of what lifecycle configuration is applied at the domain level. For more information, see [Setting Default Lifecycle Configurations](https://docs.aws.amazon.com/sagemaker/latest/dg/studio-lcc-defaults.html).\n\nData Wrangler accepts the default Kernel Gateway lifecycle configuration, but some of the commands defined in the default Kernel Gateway lifecycle configuration aren’t applicable to Data Wrangler, which can cause Data Wrangler to fail to start. The following screenshot shows an example of an error message you might get when launching the Data Wrangler flow. This may happen only with default lifecycle configurations and not with lifecycle configurations.\n\n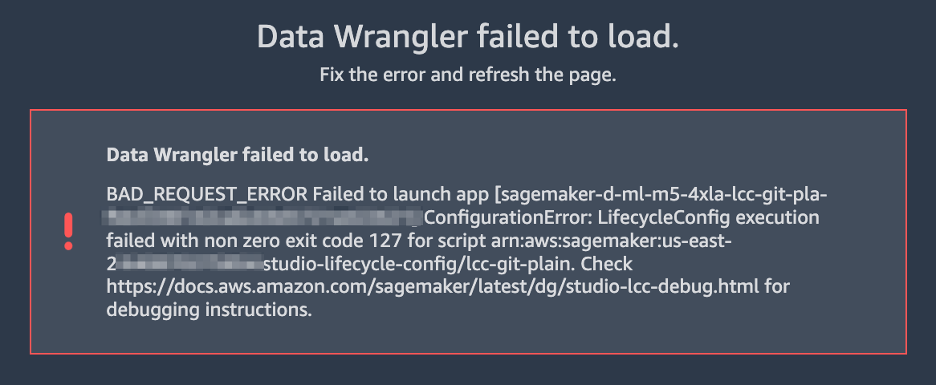\n\n\n#### **Solution overview**\n\nCustomers using the default lifecycle configuration in Studio can follow this post and use the supplied code block within the lifecycle configuration script to launch a Data Wrangler app without any errors.\n\n#### **Set up the default lifecycle configuration**\n\nTo set up a default lifecycle configuration, you must add it to the ```DefaultResourceSpec```of the appropriate app type. The behavior of your lifecycle configuration depends on whether it’s added to the ```DefaultResourceSpec```of a Jupyter Server or Kernel Gateway app:\n\n- Jupyter Server apps – When added to the ```DefaultResourceSpec```of a Jupyter Server app, the default lifecycle configuration script runs automatically when the user logs in to Studio for the first time or restarts Studio. You can use this to automate one-time setup actions for the Studio developer environment, such as installing notebook extensions or setting up a GitHub repo. For an example of this, [see Customize Amazon SageMaker Studio using Lifecycle Configurations](https://aws.amazon.com/cn/blogs/machine-learning/customize-amazon-sagemaker-studio-using-lifecycle-configurations/).\n- **Kernel Gateway apps** – When added to the ```DefaultResourceSpec```of a Kernel Gateway app, Studio defaults to selecting the lifecycle configuration script from the Studio launcher. You can launch a notebook or terminal with the default script or choose a different one from the list of lifecycle configurations.\n\nA default Kernel Gateway lifecycle configuration specified in ```DefaultResourceSpec```\n applies to all Kernel Gateway images in the Studio domain unless you choose a different script from the list presented in the Studio launcher.\n\nWhen you work with lifecycle configurations for Studio, you create a lifecycle configuration and attach it to either your Studio domain or user profile. You can then launch a Jupyter Server or Kernel Gateway application to use the lifecycle configuration.\n\nThe following table summarizes these errors you may encounter when launching a Data Wrangler application with default lifecycle configurations.\n\n\n\nWhen you use the default lifecycle configuration associated with Studio and Data Wrangler (Kernel Gateway app), you might encounter Kernel Gateway app failure. In this post, we demonstrate how to set the default lifecycle configuration properly to exclude running commands in a Data Wrangler application so you don’t encounter Kernel Gateway app failure.\n\nLet’s say you want to install a [git-clone-repo](https://github.com/aws-samples/sagemaker-studio-lifecycle-config-examples/tree/main/scripts/git-clone-repo) script as the default lifecycle configuration that checks out a Git repository under the user’s home folder automatically when the Jupyter server starts. Let’s look at each scenario of applying a lifecycle configuration (Studio domain, user profile, or application level).\n\n#### **Apply lifecycle configuration at the Studio domain or user profile level**\n\nTo apply the default Kernel Gateway lifecycle configuration at the Studio domain or user profile level, complete the steps in this section. We start with instructions for the user profile level.\n\nIn your lifecycle configuration script, you have to include the following code block that checks and skips the Data Wrangler Kernel Gateway app:\n\n```\nBash\n```\n```\n#!/bin/bash\nset -eux\nSTATUS=$(\npython3 -c \"import sagemaker_dataprep\"\necho $?\n)\nif [ \"$STATUS\" -eq 0 ]; then\necho 'Instance is of Type Data Wrangler'\nelse\necho 'Instance is not of Type Data Wrangler'\n<remainder of LCC here within in else block – this contains some pip install, etc>\nfi\n```\n\nFor example, let’s use the [following script](https://github.com/aws-samples/sagemaker-studio-lifecycle-config-examples/blob/main/scripts/git-clone-repo/on-jupyter-server-start.sh) as our original (note that the folder to clone the repo is changed to ```/root from /home/sagemaker-user```):\n\n```\nBash\n```\n```\n# Clones a git repository into the user's home folder\n#!/bin/bash\n\nset -eux\n\n# Replace this with the URL of your git repository\nexport REPOSITORY_URL=\"https://github.com/aws-samples/sagemaker-studio-lifecycle-config-examples.git\"\n\ngit -C /root clone $REPOSITORY_URL\n```\n\nThe new modified script looks like the following:\n\n```\nBash\n```\n```\n#!/bin/bash\nset -eux\nSTATUS=$(\npython3 -c \"import sagemaker_dataprep\"\necho $?\n)\nif [ \"$STATUS\" -eq 0 ]; then\necho 'Instance is of Type Data Wrangler'\nelse\necho 'Instance is not of Type Data Wrangler'\n\n# Replace this with the URL of your git repository\nexport REPOSITORY_URL=\"https://github.com/aws-samples/sagemaker-studio-lifecycle-config-examples.git\"\n\ngit -C /root clone $REPOSITORY_URL\n\nfi\n```\n\nYou can save this script as ```git_command_test.sh```.\n\nNow you run a series of commands in your terminal or command prompt. You should configure the AWS Command Line Interface (AWS CLI) to interact with AWS. If you haven’t set up the AWS CLI, refer to [Configuring the AWS CLI](https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-configure.html).\n\n1. Convert your ```git_command_test```.sh file into Base64 format. This requirement prevents errors due to the encoding of spacing and line breaks.\n\n```\nLCC_GIT=openssl base64 -A -in /Users/abcde/Downloads/git_command_test.sh\n```\n\n2. Create a Studio lifecycle configuration. The following command creates a lifecycle configuration that runs on launch of an associated Kernel Gateway app:\n\n```\naws sagemaker create-studio-lifecycle-config —region us-east-2 —studio-lifecycle-config-name lcc-git —studio-lifecycle-config-content $LCC_GIT —studio-lifecycle-config-app-type KernelGateway\n```\n\n3. Use the following API call to create a new user profile with an associated lifecycle configuration:\n\n```\naws sagemaker create-user-profile --domain-id d-vqc14vvvvvvv \\\n--user-profile-name test \\\n--region us-east-2 \\\n--user-settings '{\n\"KernelGatewayAppSettings\": {\n\"LifecycleConfigArns\" : [\"arn:aws:sagemaker:us-east-2:000000000000:studio-lifecycle-config/lcc-git\"],\n\"DefaultResourceSpec\": {\n\"InstanceType\": \"ml.m5.xlarge\",\n\"LifecycleConfigArn\": \"arn:aws:sagemaker:us-east-2:00000000000:studio-lifecycle-config/lcc-git\"\n}\n}\n}'\n```\n\n\nAlternatively, if you want to create a Studio domain to associate your lifecycle configuration at the domain level, or update the user profile or domain, you can follow the steps in [Setting Default Lifecycle Configurations](https://docs.aws.amazon.com/sagemaker/latest/dg/studio-lcc-defaults.html).\n\n4. Now you can launch your Studio app from the SageMaker Control Panel.\n\n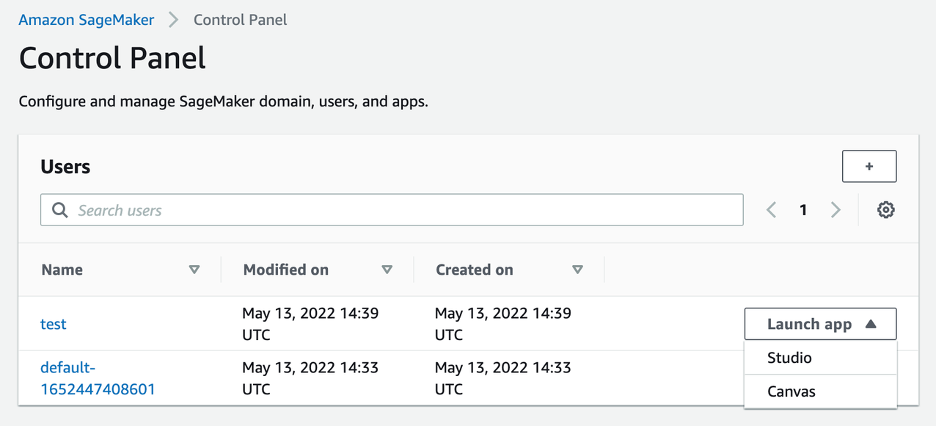\n\n5. In your Studio environment, on the File menu, choose New and Data Wrangler Flow.The new Data Wrangler flow should open without any issues.\n\n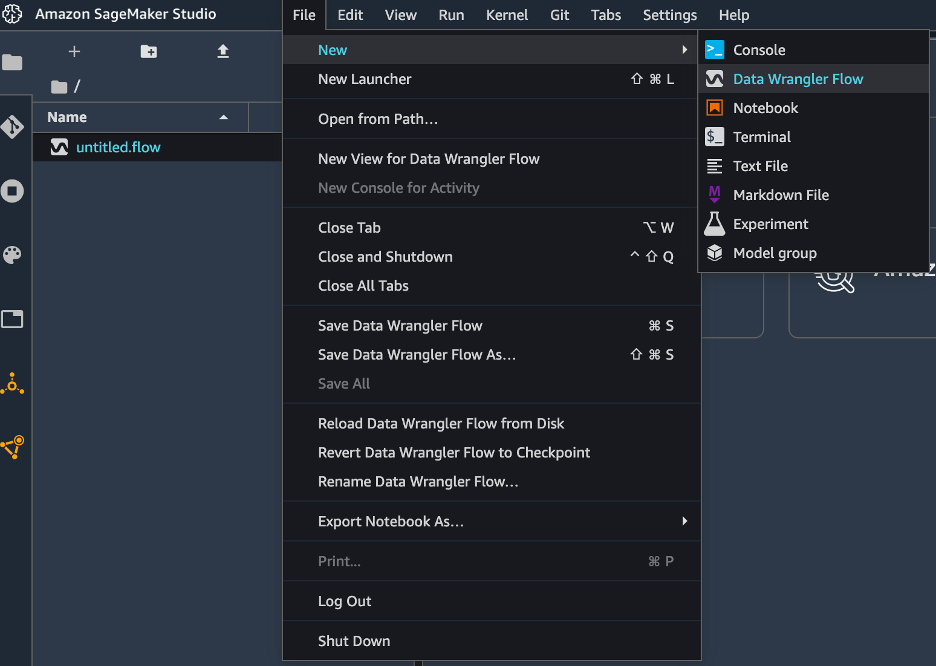\n\n6. To validate the Git clone, you can open a new Launcher in Studio.\n\n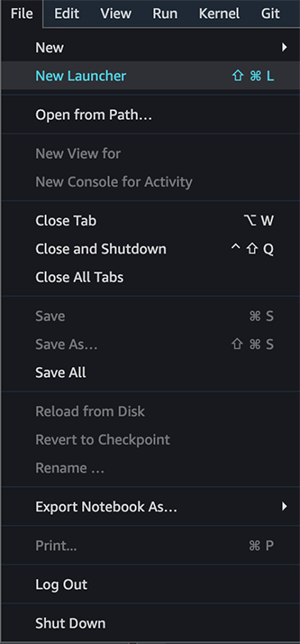\n\n7. Under **Notebooks and compute resources**, choose the Python 3 notebook and the Data Science SageMaker image to start your script as your default lifecycle configuration script.\n\n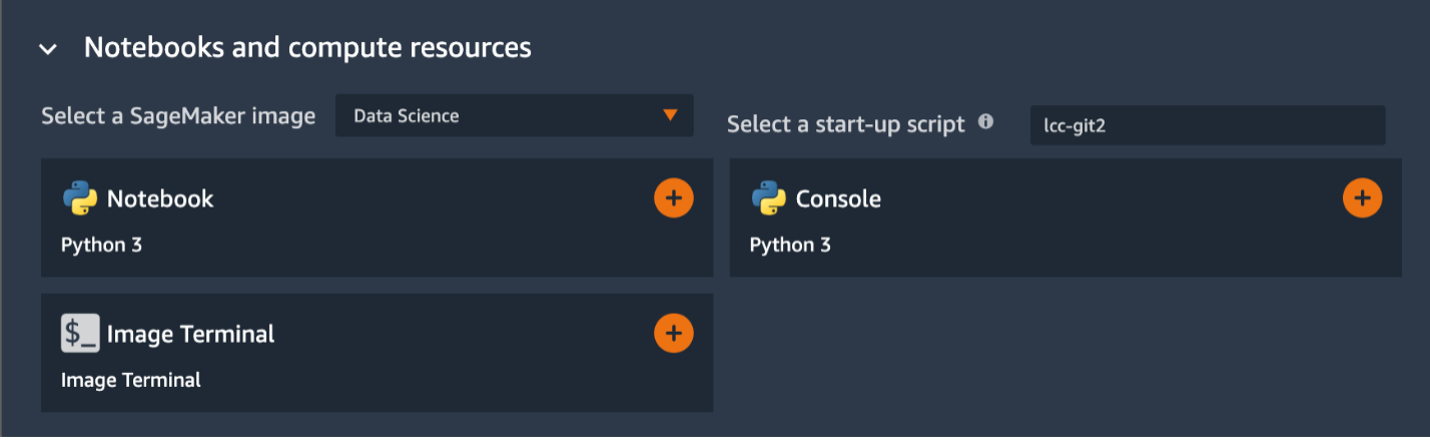\n\nYou can see the Git cloned to ```/root```in the following screenshot.\n\n\n\nWe have successfully applied the default Kernel lifecycle configuration at the user profile level and created a Data Wrangler flow. To configure at the Studio domain level, the only change is instead of creating a user profile, you pass the ARN of the lifecycle configuration in a [create-domain](https://docs.aws.amazon.com/sagemaker/latest/APIReference/API_CreateDomain.html) call.\n\n#### **Apply lifecycle configuration at the application level**\n\nIf you apply the default Kernel Gateway lifecycle configuration at the application level, you won’t have any issues because Data Wrangler skips the lifecycle configuration applied at the application level.\n\n#### **Conclusion**\n\nIn this post, we showed how to configure your default lifecycle configuration properly for Studio when you use Data Wrangler for data preparation and visualization requirements.\n\nTo summarize, if you need to use the default lifecycle configuration for Studio to automate customization for your Studio environments and use Data Wrangler for data preparation, you can apply the default Kernel Gateway lifecycle configuration at the user profile or Studio domain level with the appropriate code block included in your lifecycle configuration so that the default lifecycle configuration checks it and skips the Data Wrangler Kernel Gateway app.\n\nFor more information, see the following resources:\n\n- [Amazon SageMaker Studio lifecycle configuration documentation](https://docs.aws.amazon.com/sagemaker/latest/dg/studio-lcc.html) \n- [Amazon SageMaker Studio](https://docs.aws.amazon.com/sagemaker/latest/dg/studio.html)\n- [Repository of example lifecycle configuration scripts](https://github.com/aws-samples/sagemaker-studio-lifecycle-config-examples)\n- [Debugging Lifecycle Configurations](https://docs.aws.amazon.com/sagemaker/latest/dg/studio-lcc-debug.html)\n\n\t——————————————————————————————————————————\n\n#### **About the Authors**\n\n R**ajakumar Sampathkumaris** a Principal Technical Account Manager at AWS, providing customers guidance on business-technology alignment and supporting the reinvention of their cloud operation models and processes. He is passionate about cloud and machine learning. Raj is also a machine learning specialist and works with AWS customers to design, deploy, and manage their AWS workloads and architectures.\n\n **Vicky Zhang** is a Software Development Engineer at Amazon SageMaker. She is passionate about problem solving. In her spare time, she enjoys watching detective movies and playing badminton.\n\n **Rahul Nabera** is a Data Analytics Consultant in AWS Professional Services. His current work focuses on enabling customers build their data and machine learning workloads on AWS. In his spare time, he enjoys playing cricket and volleyball.","render":"<p>If you use the default lifecycle configuration for your domain or user profile in <a href=\"https://docs.aws.amazon.com/sagemaker/latest/dg/studio.html\" target=\"_blank\">Amazon SageMaker Studio</a> and use <a href=\"https://aws.amazon.com/cn/sagemaker/data-wrangler/\" target=\"_blank\">Amazon SageMaker Data Wrangler</a> for data preparation, then this post is for you. In this post, we show how you can create a Data Wrangler flow and use it for data preparation in a Studio environment with a default lifecycle configuration.</p>\n<p>Data Wrangler is a capability of<a href=\"https://aws.amazon.com/cn/sagemaker/\" target=\"_blank\"> Amazon SageMaker</a> that makes it faster for data scientists and engineers to prepare data for machine learning (ML) applications via a visual interface. Data preparation is a crucial step of the ML lifecycle, and Data Wrangler provides an end-to-end solution to import, explore, transform, featurize, and process data for ML in a visual, low-code experience. It lets you easily and quickly connect to AWS components like <a href=\"https://aws.amazon.com/cn/s3/\" target=\"_blank\">Amazon Simple Storage Service</a> (Amazon S3), <a href=\"https://aws.amazon.com/cn/athena/?whats-new-cards.sort-by=item.additionalFields.postDateTime&whats-new-cards.sort-order=desc\" target=\"_blank\">Amazon Athena</a>, <a href=\"https://aws.amazon.com/cn/redshift/\" target=\"_blank\">Amazon Redshift</a>, and <a href=\"https://aws.amazon.com/cn/lake-formation/?whats-new-cards.sort-by=item.additionalFields.postDateTime&whats-new-cards.sort-order=desc\" target=\"_blank\">AWS Lake Formation</a>, and external sources like Snowflake and DataBricks DeltaLake. Data Wrangler supports standard data types such as CSV, JSON, ORC, and Parquet.</p>\n<p>Studio apps are interactive applications that enable Studio’s visual interface, code authoring, and run experience. App types can be either Jupyter Server or Kernel Gateway:</p>\n<ul>\n<li>Jupyter Server – Enables access to the visual interface for Studio. Every user in Studio gets their own Jupyter Server app.</li>\n<li>Kernel Gateway – Enables access to the code run environment and kernels for your Studio notebooks and terminals. For more information, see <a href=\"https://jupyter-kernel-gateway.readthedocs.io/en/latest/\" target=\"_blank\">Jupyter Kernel Gateway</a>.</li>\n</ul>\n<p><a href=\"https://docs.aws.amazon.com/sagemaker/latest/dg/studio-lcc.html\" target=\"_blank\">Lifecycle configurations</a> (LCCs) are shell scripts to automate customization for your Studio environments, such as installing JupyterLab extensions, preloading datasets, and setting up source code repositories. LCC scripts are triggered by Studio lifecycle events, such as starting a new Studio notebook. To set a lifecycle configuration as the default for your domain or user profile programmatically, you can create a new resource or update an existing resource. To associate a lifecycle configuration as a default, you first need to create a lifecycle configuration following the steps in <a href=\"https://docs.aws.amazon.com/sagemaker/latest/dg/studio-lcc-create.html\" target=\"_blank\">Creating and Associating a Lifecycle Configuration</a></p>\n<p>Note: Default lifecycle configurations set up at the domain level are inherited by all users, whereas those set up at the user level are scoped to a specific user. If you apply both domain-level and user profile-level lifecycle configurations at the same time, the user profile-level lifecycle configuration takes precedence and is applied to the application irrespective of what lifecycle configuration is applied at the domain level. For more information, see <a href=\"https://docs.aws.amazon.com/sagemaker/latest/dg/studio-lcc-defaults.html\" target=\"_blank\">Setting Default Lifecycle Configurations</a>.</p>\n<p>Data Wrangler accepts the default Kernel Gateway lifecycle configuration, but some of the commands defined in the default Kernel Gateway lifecycle configuration aren’t applicable to Data Wrangler, which can cause Data Wrangler to fail to start. The following screenshot shows an example of an error message you might get when launching the Data Wrangler flow. This may happen only with default lifecycle configurations and not with lifecycle configurations.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/59e9d6d6262146979f8b8e35ce0dcc7f_image.png\" alt=\"image.png\" /></p>\n<h4><a id=\"Solution_overview_18\"></a><strong>Solution overview</strong></h4>\n<p>Customers using the default lifecycle configuration in Studio can follow this post and use the supplied code block within the lifecycle configuration script to launch a Data Wrangler app without any errors.</p>\n<h4><a id=\"Set_up_the_default_lifecycle_configuration_22\"></a><strong>Set up the default lifecycle configuration</strong></h4>\n<p>To set up a default lifecycle configuration, you must add it to the <code>DefaultResourceSpec</code>of the appropriate app type. The behavior of your lifecycle configuration depends on whether it’s added to the <code>DefaultResourceSpec</code>of a Jupyter Server or Kernel Gateway app:</p>\n<ul>\n<li>Jupyter Server apps – When added to the <code>DefaultResourceSpec</code>of a Jupyter Server app, the default lifecycle configuration script runs automatically when the user logs in to Studio for the first time or restarts Studio. You can use this to automate one-time setup actions for the Studio developer environment, such as installing notebook extensions or setting up a GitHub repo. For an example of this, <a href=\"https://aws.amazon.com/cn/blogs/machine-learning/customize-amazon-sagemaker-studio-using-lifecycle-configurations/\" target=\"_blank\">see Customize Amazon SageMaker Studio using Lifecycle Configurations</a>.</li>\n<li><strong>Kernel Gateway apps</strong> – When added to the <code>DefaultResourceSpec</code>of a Kernel Gateway app, Studio defaults to selecting the lifecycle configuration script from the Studio launcher. You can launch a notebook or terminal with the default script or choose a different one from the list of lifecycle configurations.</li>\n</ul>\n<p>A default Kernel Gateway lifecycle configuration specified in <code>DefaultResourceSpec</code><br />\napplies to all Kernel Gateway images in the Studio domain unless you choose a different script from the list presented in the Studio launcher.</p>\n<p>When you work with lifecycle configurations for Studio, you create a lifecycle configuration and attach it to either your Studio domain or user profile. You can then launch a Jupyter Server or Kernel Gateway application to use the lifecycle configuration.</p>\n<p>The following table summarizes these errors you may encounter when launching a Data Wrangler application with default lifecycle configurations.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/47005d195c714fd381e264dee1f3d31e_image.png\" alt=\"image.png\" /></p>\n<p>When you use the default lifecycle configuration associated with Studio and Data Wrangler (Kernel Gateway app), you might encounter Kernel Gateway app failure. In this post, we demonstrate how to set the default lifecycle configuration properly to exclude running commands in a Data Wrangler application so you don’t encounter Kernel Gateway app failure.</p>\n<p>Let’s say you want to install a <a href=\"https://github.com/aws-samples/sagemaker-studio-lifecycle-config-examples/tree/main/scripts/git-clone-repo\" target=\"_blank\">git-clone-repo</a> script as the default lifecycle configuration that checks out a Git repository under the user’s home folder automatically when the Jupyter server starts. Let’s look at each scenario of applying a lifecycle configuration (Studio domain, user profile, or application level).</p>\n<h4><a id=\"Apply_lifecycle_configuration_at_the_Studio_domain_or_user_profile_level_42\"></a><strong>Apply lifecycle configuration at the Studio domain or user profile level</strong></h4>\n<p>To apply the default Kernel Gateway lifecycle configuration at the Studio domain or user profile level, complete the steps in this section. We start with instructions for the user profile level.</p>\n<p>In your lifecycle configuration script, you have to include the following code block that checks and skips the Data Wrangler Kernel Gateway app:</p>\n<pre><code class=\"lang-\">Bash\n</code></pre>\n<pre><code class=\"lang-\">#!/bin/bash\nset -eux\nSTATUS=$(\npython3 -c "import sagemaker_dataprep"\necho $?\n)\nif [ "$STATUS" -eq 0 ]; then\necho 'Instance is of Type Data Wrangler'\nelse\necho 'Instance is not of Type Data Wrangler'\n<remainder of LCC here within in else block – this contains some pip install, etc>\nfi\n</code></pre>\n<p>For example, let’s use the <a href=\"https://github.com/aws-samples/sagemaker-studio-lifecycle-config-examples/blob/main/scripts/git-clone-repo/on-jupyter-server-start.sh\" target=\"_blank\">following script</a> as our original (note that the folder to clone the repo is changed to <code>/root from /home/sagemaker-user</code>):</p>\n<pre><code class=\"lang-\">Bash\n</code></pre>\n<pre><code class=\"lang-\"># Clones a git repository into the user's home folder\n#!/bin/bash\n\nset -eux\n\n# Replace this with the URL of your git repository\nexport REPOSITORY_URL="https://github.com/aws-samples/sagemaker-studio-lifecycle-config-examples.git"\n\ngit -C /root clone $REPOSITORY_URL\n</code></pre>\n<p>The new modified script looks like the following:</p>\n<pre><code class=\"lang-\">Bash\n</code></pre>\n<pre><code class=\"lang-\">#!/bin/bash\nset -eux\nSTATUS=$(\npython3 -c "import sagemaker_dataprep"\necho $?\n)\nif [ "$STATUS" -eq 0 ]; then\necho 'Instance is of Type Data Wrangler'\nelse\necho 'Instance is not of Type Data Wrangler'\n\n# Replace this with the URL of your git repository\nexport REPOSITORY_URL="https://github.com/aws-samples/sagemaker-studio-lifecycle-config-examples.git"\n\ngit -C /root clone $REPOSITORY_URL\n\nfi\n</code></pre>\n<p>You can save this script as <code>git_command_test.sh</code>.</p>\n<p>Now you run a series of commands in your terminal or command prompt. You should configure the AWS Command Line Interface (AWS CLI) to interact with AWS. If you haven’t set up the AWS CLI, refer to <a href=\"https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-configure.html\" target=\"_blank\">Configuring the AWS CLI</a>.</p>\n<ol>\n<li>Convert your <code>git_command_test</code>.sh file into Base64 format. This requirement prevents errors due to the encoding of spacing and line breaks.</li>\n</ol>\n<pre><code class=\"lang-\">LCC_GIT=openssl base64 -A -in /Users/abcde/Downloads/git_command_test.sh\n</code></pre>\n<ol start=\"2\">\n<li>Create a Studio lifecycle configuration. The following command creates a lifecycle configuration that runs on launch of an associated Kernel Gateway app:</li>\n</ol>\n<pre><code class=\"lang-\">aws sagemaker create-studio-lifecycle-config —region us-east-2 —studio-lifecycle-config-name lcc-git —studio-lifecycle-config-content $LCC_GIT —studio-lifecycle-config-app-type KernelGateway\n</code></pre>\n<ol start=\"3\">\n<li>Use the following API call to create a new user profile with an associated lifecycle configuration:</li>\n</ol>\n<pre><code class=\"lang-\">aws sagemaker create-user-profile --domain-id d-vqc14vvvvvvv \\\n--user-profile-name test \\\n--region us-east-2 \\\n--user-settings '{\n"KernelGatewayAppSettings": {\n"LifecycleConfigArns" : ["arn:aws:sagemaker:us-east-2:000000000000:studio-lifecycle-config/lcc-git"],\n"DefaultResourceSpec": {\n"InstanceType": "ml.m5.xlarge",\n"LifecycleConfigArn": "arn:aws:sagemaker:us-east-2:00000000000:studio-lifecycle-config/lcc-git"\n}\n}\n}'\n</code></pre>\n<p>Alternatively, if you want to create a Studio domain to associate your lifecycle configuration at the domain level, or update the user profile or domain, you can follow the steps in <a href=\"https://docs.aws.amazon.com/sagemaker/latest/dg/studio-lcc-defaults.html\" target=\"_blank\">Setting Default Lifecycle Configurations</a>.</p>\n<ol start=\"4\">\n<li>Now you can launch your Studio app from the SageMaker Control Panel.</li>\n</ol>\n<p><img src=\"https://dev-media.amazoncloud.cn/af1f5959afdf490098107f355ed0cb6a_image.png\" alt=\"image.png\" /></p>\n<ol start=\"5\">\n<li>In your Studio environment, on the File menu, choose New and Data Wrangler Flow.The new Data Wrangler flow should open without any issues.</li>\n</ol>\n<p><img src=\"https://dev-media.amazoncloud.cn/9c13d09ebdde42eeaa991fd782c42e0f_image.png\" alt=\"image.png\" /></p>\n<ol start=\"6\">\n<li>To validate the Git clone, you can open a new Launcher in Studio.</li>\n</ol>\n<p><img src=\"https://dev-media.amazoncloud.cn/8e6789cd11a7406c864cba2478b71b60_image.png\" alt=\"image.png\" /></p>\n<ol start=\"7\">\n<li>Under <strong>Notebooks and compute resources</strong>, choose the Python 3 notebook and the Data Science SageMaker image to start your script as your default lifecycle configuration script.</li>\n</ol>\n<p><img src=\"https://dev-media.amazoncloud.cn/007e51e282674d568e2fb1fc29a6eb2b_image.png\" alt=\"image.png\" /></p>\n<p>You can see the Git cloned to <code>/root</code>in the following screenshot.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/1c5bd50b641f4d77a23f41aa1588cc13_image.png\" alt=\"image.png\" /></p>\n<p>We have successfully applied the default Kernel lifecycle configuration at the user profile level and created a Data Wrangler flow. To configure at the Studio domain level, the only change is instead of creating a user profile, you pass the ARN of the lifecycle configuration in a <a href=\"https://docs.aws.amazon.com/sagemaker/latest/APIReference/API_CreateDomain.html\" target=\"_blank\">create-domain</a> call.</p>\n<h4><a id=\"Apply_lifecycle_configuration_at_the_application_level_166\"></a><strong>Apply lifecycle configuration at the application level</strong></h4>\n<p>If you apply the default Kernel Gateway lifecycle configuration at the application level, you won’t have any issues because Data Wrangler skips the lifecycle configuration applied at the application level.</p>\n<h4><a id=\"Conclusion_170\"></a><strong>Conclusion</strong></h4>\n<p>In this post, we showed how to configure your default lifecycle configuration properly for Studio when you use Data Wrangler for data preparation and visualization requirements.</p>\n<p>To summarize, if you need to use the default lifecycle configuration for Studio to automate customization for your Studio environments and use Data Wrangler for data preparation, you can apply the default Kernel Gateway lifecycle configuration at the user profile or Studio domain level with the appropriate code block included in your lifecycle configuration so that the default lifecycle configuration checks it and skips the Data Wrangler Kernel Gateway app.</p>\n<p>For more information, see the following resources:</p>\n<ul>\n<li>\n<p><a href=\"https://docs.aws.amazon.com/sagemaker/latest/dg/studio-lcc.html\" target=\"_blank\">Amazon SageMaker Studio lifecycle configuration documentation</a></p>\n</li>\n<li>\n<p><a href=\"https://docs.aws.amazon.com/sagemaker/latest/dg/studio.html\" target=\"_blank\">Amazon SageMaker Studio</a></p>\n</li>\n<li>\n<p><a href=\"https://github.com/aws-samples/sagemaker-studio-lifecycle-config-examples\" target=\"_blank\">Repository of example lifecycle configuration scripts</a></p>\n</li>\n<li>\n<p><a href=\"https://docs.aws.amazon.com/sagemaker/latest/dg/studio-lcc-debug.html\" target=\"_blank\">Debugging Lifecycle Configurations</a></p>\n<p>——————————————————————————————————————————</p>\n</li>\n</ul>\n<h4><a id=\"About_the_Authors_185\"></a><strong>About the Authors</strong></h4>\n<p><img src=\"https://dev-media.amazoncloud.cn/c60acfbabab04c14b15d2d53dd3097c7_image.png\" alt=\"image.png\" /> R<strong>ajakumar Sampathkumaris</strong> a Principal Technical Account Manager at AWS, providing customers guidance on business-technology alignment and supporting the reinvention of their cloud operation models and processes. He is passionate about cloud and machine learning. Raj is also a machine learning specialist and works with AWS customers to design, deploy, and manage their AWS workloads and architectures.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/69b2e85c6d2b43f58c9768671d3531f9_image.png\" alt=\"image.png\" /> <strong>Vicky Zhang</strong> is a Software Development Engineer at Amazon SageMaker. She is passionate about problem solving. In her spare time, she enjoys watching detective movies and playing badminton.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/4395343de02d403c80ac350609391e2b_image.png\" alt=\"image.png\" /> <strong>Rahul Nabera</strong> is a Data Analytics Consultant in AWS Professional Services. His current work focuses on enabling customers build their data and machine learning workloads on AWS. In his spare time, he enjoys playing cricket and volleyball.</p>\n"}
Use Amazon SageMaker Data Wrangler in Amazon SageMaker Studio with a default lifecycle configuration
海外精选

海外精选的内容汇集了全球优质的亚马逊云科技相关技术内容。同时,内容中提到的“AWS”
是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。

 0
0 0
0亚马逊云科技解决方案 基于行业客户应用场景及技术领域的解决方案
联系亚马逊云科技专家
亚马逊云科技解决方案
基于行业客户应用场景及技术领域的解决方案
联系专家

0
目录

 分享
分享 点赞
点赞 收藏
收藏 目录
目录立即注册,开启您的免费套餐
立即关注

亚马逊云开发者
公众号

User Group
公众号

亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
关于我们 
更多资源
开发者工具
更多支持
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
