{"value":"Online conversations are ubiquitous in modern life, spanning industries from video games to telecommunications. This has led to an exponential growth in the amount of online conversation data, which has helped in the development of state-of-the-art natural language processing (NLP) systems like chatbots and natural language generation (NLG) models. Over time, various NLP techniques for text analysis have also evolved. This necessitates the requirement for a fully managed service that can be integrated into applications using API calls without the need for extensive machine learning (ML) expertise. AWS offers pre-trained AWS AI services like [Amazon Comprehend](https://aws.amazon.com/cn/comprehend/), which can effectively handle NLP use cases involving classification, text summarization, entity recognition, and more to gather insights from text.\n\nAdditionally, online conversations have led to a wide-spread phenomenon of non-traditional usage of language. Traditional NLP techniques often perform poorly on this text data due to the constantly evolving and domain-specific vocabularies that exist within different platforms, as well as the significant lexical deviations of words from proper English, either by accident or intentionally as a form of adversarial attack.\n\nIn this post, we describe multiple ML approaches for text classification of online conversations with tools and services available on AWS.\n\n#### **Prerequisites**\n\nBefore diving deep into this use case, please complete the following prerequisites:\n\n1. Set up an [AWS account](https://aws.amazon.com/cn/getting-started/guides/setup-environment/module-one/) and [create an IAM user](https://aws.amazon.com/cn/getting-started/guides/setup-environment/module-two/).\n2. Set up the [AWS CLI](https://aws.amazon.com/cn/getting-started/guides/setup-environment/module-three/) and [AWS SDKs](https://aws.amazon.com/tools/).\n3. (Optional) Set up your [Cloud9 IDE environment](https://aws.amazon.com/cn/getting-started/guides/setup-environment/module-four/).\n\n#### **Dataset**\n\nFor this post, we use the [Jigsaw Unintended Bias in Toxicity Classification dataset](https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification/overview), a benchmark for the specific problem of classification of toxicity in online conversations. The dataset provides toxicity labels as well as several subgroup attributes such as obscene, identity attack, insult, threat, and sexually explicit. Labels are provided as fractional values, which represent the proportion of human annotators who believed the attribute applied to a given piece of text, which are rarely unanimous. To generate binary labels (for example, toxic or non-toxic), a threshold of 0.5 is applied to the fractional values, and comments with values greater than the threshold are treated as the positive class for that label.\n\n#### **Subword embedding and RNNs**\n\nFor our first modeling approach, we use a combination of subword embedding and recurrent neural networks (RNNs) to train text classification models. Subword embeddings were introduced by [Bojanowski et al. in 2017](https://arxiv.org/abs/1607.04606) as an improvement upon previous word-level embedding methods. Traditional Word2Vec skip-gram models are trained to learn a static vector representation of a target word that optimally predicts that word’s context. Subword models, on the other hand, represent each target word as a bag of the character n-grams that make up the word, where an n-gram is composed of a set of n consecutive characters. This method allows for the embedding model to better represent the underlying morphology of related words in the corpus as well as the computation of embeddings for novel, out-of-vocabulary (OOV) words. This is particularly important in the context of online conversations, a problem space in which users often misspell words (sometimes intentionally to evade detection) and also use a unique, constantly evolving vocabulary that might not be captured by a general training corpus.\n\n[Amazon SageMaker](https://aws.amazon.com/cn/sagemaker/) makes it easy to train and optimize an unsupervised subword embedding model on your own corpus of domain-specific text data with the built-in [BlazingText algorithm](https://docs.aws.amazon.com/sagemaker/latest/dg/blazingtext.html). We can also download existing general-purpose models trained on large datasets of online text, such as the following [English language models available directly from fastText](https://fasttext.cc/docs/en/english-vectors.html). From your SageMaker notebook instance, simply run the following to download a pretrained fastText model:\n\n```\n!wget -O vectors.zip https://dl.fbaipublicfiles.com/fasttext/vectors-english/crawl-300d-2M-subword.zip\n```\n\nWhether you’ve trained your own embeddings with BlazingText or downloaded a pretrained model, the result is a zipped model binary that you can use with the gensim library to embed a given target word as a vector based on its constituent subwords:\n\n```\n# Imports\nimport os\nfrom zipfile import ZipFile\nfrom gensim.models.fasttext import load_facebook_vectors\n\n# Unzip the model binary into 'dir_path'\nwith ZipFile('vectors.zip', 'r') as zipObj:\n zipObj.extractall(path=<dir_path_name>)\n\n# Load embedding model into memory\nembed_model = load_facebook_vectors(os.path.join(<dir_path_name>, 'vectors.bin'))\n\n# Compute embedding vector for 'word'\nword_embedding = embed_model[word]\n```\nAfter we preprocess a given segment of text, we can use this approach to generate a vector representation for each of the constituent words (as separated by spaces). We then use SageMaker and a deep learning framework such as PyTorch to train a customized RNN with a binary or multilabel classification objective to predict whether the text is toxic or not and the specific sub-type of toxicity based on labeled training examples.\n\nTo upload your preprocessed text to[ Amazon Simple Storage Service](https://aws.amazon.com/cn/s3/) (Amazon S3), use the following code:\n\n```\nimport boto3\ns3 = boto3.client('s3')\n\nbucket = <bucket_name>\nprefix = <prefix_name>\n\ns3.upload_file('train.pkl', bucket, os.path.join(prefix, 'train/train.pkl'))\ns3.upload_file('valid.pkl', bucket, os.path.join(prefix, 'valid/valid.pkl'))\ns3.upload_file('test.pkl', bucket, os.path.join(prefix, 'test/test.pkl'))\n```\n\nTo initiate scalable, multi-GPU model training with SageMaker, enter the following code:\n\n```\nimport sagemaker\nsess = sagemaker.Session()\nrole = iam.get_role(RoleName= ‘AmazonSageMakerFullAccess’)['Role']['Arn']\n\nfrom sagemaker.pytorch import PyTorch\n\n# hyperparameters, which are passed into the training job\nhyperparameters = {\n 'epochs': 20, # Maximum number of epochs to train model\n 'train-batch-size': 128, # Training batch size (No. sentences)\n 'eval-batch-size': 1024, # Evaluation batch size (No. sentences)\n 'embed-size': 300, # Vector dimension of word embeddings (Must match embedding model)\n 'lstm-hidden-size': 200, # Number of neurons in LSTM hidden layer\n 'lstm-num-layers': 2, # Number of stacked LSTM layers\n 'proj-size': 100, # Number of neurons in intermediate projection layer\n 'num-targets': len(<list_of_label_names>), # Number of targets for classification\n 'class-weight': ' '.join([str(c) for c in <list_of_weights_per_class>]), # Weight to apply to each target during training\n 'total-length':<max_number_of_words_per_sentence>,\n 'metric-for-best-model': 'ap_score_weighted', # Metric on which to select the best model\n}\n\n# create the Estimator\npytorch_estimator = PyTorch(\n entry_point='train.py',\n source_dir=<source_dir_path>,\n instance_type=<train_instance_type>,\n volume_size=200,\n instance_count=1,\n role=role,\n framework_version='1.6.0’,\n py_version='py36',\n hyperparameters=hyperparameters,\n metric_definitions=[\n {'Name': 'validation:accuracy', 'Regex': 'eval_accuracy = (.*?);'},\n {'Name': 'validation:f1-micro', 'Regex': 'eval_f1_score_micro = (.*?);'},\n {'Name': 'validation:f1-macro', 'Regex': 'eval_f1_score_macro = (.*?);'},\n {'Name': 'validation:f1-weighted', 'Regex': 'eval_f1_score_weighted = (.*?);'},\n {'Name': 'validation:ap-micro', 'Regex': 'eval_ap_score_micro = (.*?);'},\n {'Name': 'validation:ap-macro', 'Regex': 'eval_ap_score_macro = (.*?);'},\n {'Name': 'validation:ap-weighted', 'Regex': 'eval_ap_score_weighted = (.*?);'},\n {'Name': 'validation:auc-micro', 'Regex': 'eval_auc_score_micro = (.*?);'},\n {'Name': 'validation:auc-macro', 'Regex': 'eval_auc_score_macro = (.*?);'},\n {'Name': 'validation:auc-weighted', 'Regex': 'eval_auc_score_weighted = (.*?);'}\n ]\n)\n\npytorch_estimator.fit(\n {\n 'train': 's3://<bucket_name>/<prefix_name>/train',\n 'valid': 's3://<bucket_name>/<prefix_name>/valid',\n 'test': 's3://<bucket_name>/<prefix_name>/test'\n }\n)\n```\n\nWithin <source_dir_path>, we define a PyTorch Dataset that is used by train.py to prepare the text data for training and evaluation of the model:\n\n```\ndef pad_matrix(m: torch.Tensor, max_len: int =100)-> tuple[int, torch.Tensor] :\n \"\"\"Pads an embedding matrix to a specified maximum length.\"\"\"\n if m.ndim == 1:\n m = m.reshape(1, -1)\n mask = np.ones_like(m)\n if m.shape[0] > max_len:\n m = m[:max_len, :]\n mask = mask[:max_len, :]\n else:\n m = np.pad(m, ((0, max_len - m.shape[0]), (0,0)))\n mask = np.pad(mask, ((0, max_len - mask.shape[0]), (0,0)))\n return m, mask\n\n\nclass EmbeddingDataset(Dataset: torch.utils.data.Dataset):\n \"\"\"PyTorch dataset representing pretrained sentence embeddings, masks, and labels.\"\"\"\n def __init__(self, text: str, labels: int, max_len: int=100):\n self.text = text\n self.labels = labels\n self.max_len = max_len\n\n def __len__(self) -> int:\n return len(self.labels)\n\n def __getitem__(self, idx: int) -> dict: \n e = embed_line(self.text[idx])\n length = e.shape[0]\n m, mask = pad_matrix(e, max_len=self.max_len)\n \n item = {}\n item['embeddings'] = torch.from_numpy(m)\n item['mask'] = torch.from_numpy(mask)\n item['labels'] = torch.tensor(self.labels[idx])\n if length > self.max_len:\n item['lengths'] = torch.tensor(self.max_len)\n else:\n item['lengths'] = torch.tensor(length)\n \n return item\n```\n\nNote that this code anticipates that the ```vectors.zip```file containing your fastText or BlazingText embeddings will be stored in <source_dir_path>.\n\nAdditionally, you can easily deploy pretrained fastText models on their own to live SageMaker endpoints to compute embedding vectors on the fly for use in relevant word-level tasks. See the following [GitHub example](https://github.com/aws/amazon-sagemaker-examples/blob/main/introduction_to_amazon_algorithms/blazingtext_hosting_pretrained_fasttext/blazingtext_hosting_pretrained_fasttext.ipynb) for more details.\n\n#### **Transformers with Hugging Face**\n\nFor our second modeling approach, we transition to the usage of Transformers, introduced in the paper [Attention Is All You Need](https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf). Transformers are deep learning models designed to deliberately avoid the pitfalls of RNNs by relying on a self-attention mechanism to draw global dependencies between input and output. The Transformer model architecture allows for significantly better parallelization and can achieve high performance in relatively short training time.\n\nBuilt on the success of Transformers, BERT, introduced in the paper [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805), added bidirectional pre-training for language representation. Inspired by the Cloze task, BERT is pre-trained with masked language modeling (MLM), in which the model learns to recover the original words for randomly masked tokens. The BERT model is also pretrained on the next sentence prediction (NSP) task to predict if two sentences are in correct reading order. Since its advent in 2018, BERT and its variations have been widely used in text classification tasks. \n\nOur solution uses a variant of BERT known as RoBERTa, which was introduced in the paper [RoBERTa: A Robustly Optimized BERT Pretraining Approach](https://arxiv.org/abs/1907.11692). RoBERTa further improves BERT performance on a variety of natural language tasks by optimized model training, including training models longer on a 10 times larger bigger corpus, using optimized hyperparameters, dynamic random masking, removing the NSP task, and more.\n\nOur RoBERTa-based models use the [Hugging Face Transformers](https://huggingface.co/docs/transformers/index) library, which is a popular open-source Python framework that provides high-quality implementations of all kinds of state-of-the-art Transformer models for a variety of NLP tasks. [Hugging Face has partnered with AWS](https://huggingface.co/blog/the-partnership-amazon-sagemaker-and-hugging-face) to enable you to easily train and deploy Transformer models on SageMaker. This functionality is available through [Hugging Face AWS Deep Learning Container images](https://github.com/aws/deep-learning-containers/blob/master/available_images.md#huggingface-training-containers), which include the Transformers, Tokenizers, and Datasets libraries, and optimized integration with SageMaker for model training and inference.\n\nIn our implementation, we inherit the RoBERTa architecture backbone from the Hugging Face Transformers framework and use SageMaker to train and deploy our own text classification model, which we call RoBERTox. RoBERTox uses byte pair encoding (BPE), introduced in [Neural Machine Translation of Rare Words with Subword Units](https://arxiv.org/abs/1508.07909), to tokenize input text into subword representations. We can then train our models and tokenizers on the Jigsaw data or any large domain-specific corpus (such as the chat logs from a specific game) and use them for customized text classification. We define our custom classification model class in the following code:\n\n```\nclass RoBERToxForSequenceClassification(CustomLossMixIn, RobertaPreTrainedModel):\n _keys_to_ignore_on_load_missing = [r\"position_ids\"]\n\n def __init__(self, config: PretrainedConfig, *inputs, **kwargs):\n \"\"\"Initialize the RoBERToxForSequenceClassification instance\n\n Parameters\n ----------\n config : PretrainedConfig\n num_labels : Optional[int]\n if not None, overwrite the default classification head in pretrained model.\n mode : Optional[str]\n 'MULTI_CLASS', 'MULTI_LABEL' or \"REGRESSION\". Used to determine loss\n class_weight : Optional[List[float]]\n If not None, add class weight to BCEWithLogitsLoss or CrossEntropyLoss\n \"\"\"\n super().__init__(config, *inputs, **kwargs)\n # Define model architecture\n self.roberta = RobertaModel(self.config, add_pooling_layer=False)\n self.classifier = RobertaClassificationHead(self.config)\n self.init_weights()\n\n @modeling_roberta.add_start_docstrings_to_model_forward(\n modeling_roberta.ROBERTA_INPUTS_DOCSTRING.format(\"batch_size, sequence_length\")\n )\n @modeling_roberta.add_code_sample_docstrings(\n tokenizer_class=modeling_roberta._TOKENIZER_FOR_DOC,\n checkpoint=modeling_roberta._CHECKPOINT_FOR_DOC,\n output_type=SequenceClassifierOutput,\n config_class=modeling_roberta._CONFIG_FOR_DOC,\n )\n def forward(\n self,\n input_ids: torch.Tensor = None,\n attention_mask: torch.Tensor = None,\n token_type_ids: torch.Tensor = None,\n position_ids: torch.Tensor =None,\n head_mask: torch.Tensor =None,\n inputs_embeds: torch.Tensor =None,\n labels: torch.Tensor =None,\n output_attentions: torch.Tensor =None,\n output_hidden_states: torch.Tensor =None,\n return_dict: bool =None,\n sample_weights: torch.Tensor =None,\n ) -> : dict:\n \"\"\"Forward pass to return loss, logits, ...\n\n Returns\n --------\n output : SequenceClassifierOutput\n has those keys: loss, logits, hidden states, attentions\n \"\"\"\n return_dict = return_dict or self.config.use_return_dict\n\n outputs = self.roberta(\n input_ids,\n attention_mask=attention_mask,\n token_type_ids=token_type_ids,\n position_ids=position_ids,\n head_mask=head_mask,\n inputs_embeds=inputs_embeds,\n output_attentions=output_attentions,\n output_hidden_states=output_hidden_states,\n return_dict=return_dict,\n )\n sequence_output = outputs[0] # [CLS] embedding\n logits = self.classifier(sequence_output)\n loss = self.compute_loss(logits, labels, sample_weights=sample_weights)\n\n if not return_dict:\n output = (logits,) + outputs[2:]\n return ((loss,) + output) if loss is not None else output\n\n return SequenceClassifierOutput(\n loss=loss,\n logits=logits,\n hidden_states=outputs.hidden_states,\n attentions=outputs.attentions,\n )\n\n def compute_loss(self, logits: torch.Tensor, labels: torch.Tensor, sample_weights: Optional[torch.Tensor] = None) -> torch.FloatTensor:\n return super().compute_loss(logits, labels, sample_weights)\n```\n\nBefore training, we prepare our text data and labels using Hugging Face’s datasets library and upload the result to Amazon S3:\n\n```\nfrom datasets import Dataset\nimport multiprocessing\n\ndata_train = Dataset.from_pandas(df_train)\n…\n\ntokenizer = <instantiated_huggingface_tokenizer>\n\ndef preprocess_function(examples: examples) -> torch.Tensor:\n result = tokenizer(examples[\"text\"], padding=\"max_length\", max_length=128, truncation=True)\n return result\n\nnum_proc = multiprocessing.cpu_count()\nprint(\"Number of CPUs =\", num_proc)\n\ndata_train = data_train.map(\n preprocess_function,\n batched=True,\n load_from_cache_file=False,\n num_proc=num_proc\n)\n…\n\nimport botocore\nfrom datasets.filesystems import S3FileSystem\n\ns3_session = botocore.session.Session()\n\n# create S3FileSystem instance with s3_session\ns3 = S3FileSystem(session=s3_session) \n\n# saves encoded_dataset to your s3 bucket\ndata_train.save_to_disk(f's3://<bucket_name>/<prefix_name>/train', fs=s3)\n… \n```\n\nWe initiate training of the model in a similar fashion to the RNN:\n\n```\nimport sagemaker\nsess = sagemaker.Session()\nrole = sagemaker.get_execution_role()\nfrom sagemaker.huggingface import HuggingFace\n\n# hyperparameters, which are passed into the training job\nhyperparameters = {\n 'model-name': <huggingface_base_model_name>,\n 'epochs': 10,\n 'train-batch-size': 32,\n 'eval-batch-size': 64,\n 'num-labels': len(<list_of_label_names>),\n 'class-weight': ' '.join([str(c) for c in <list_of_class_weights>]),\n 'metric-for-best-model': 'ap_score_weighted',\n 'save-total-limit': 1,\n}\n\n# create the Estimator\nhuggingface_estimator = HuggingFace(\n entry_point='train.py',\n source_dir=<source_dir_path>,\n instance_type=<train_instance_type>,\n instance_count=1,\n role=role,\n transformers_version='4.6.1',\n pytorch_version='1.7.1',\n py_version='py36',\n hyperparameters=hyperparameters,\n metric_definitions=[\n {'Name': 'validation:accuracy', 'Regex': 'eval_accuracy = (.*?);'},\n {'Name': 'validation:f1-micro', 'Regex': 'eval_f1_score_micro = (.*?);'},\n {'Name': 'validation:f1-macro', 'Regex': 'eval_f1_score_macro = (.*?);'},\n {'Name': 'validation:f1-weighted', 'Regex': 'eval_f1_score_weighted = (.*?);'},\n {'Name': 'validation:ap-micro', 'Regex': 'eval_ap_score_micro = (.*?);'},\n {'Name': 'validation:ap-macro', 'Regex': 'eval_ap_score_macro = (.*?);'},\n {'Name': 'validation:ap-weighted', 'Regex': 'eval_ap_score_weighted = (.*?);'},\n {'Name': 'validation:auc-micro', 'Regex': 'eval_auc_score_micro = (.*?);'},\n {'Name': 'validation:auc-macro', 'Regex': 'eval_auc_score_macro = (.*?);'},\n {'Name': 'validation:auc-weighted', 'Regex': 'eval_auc_score_weighted = (.*?);'}\n ]\n)\n\nhuggingface_estimator.fit(\n {\n 'train': 's3://<bucket_name>/<prefix_name>/train',\n 'valid': 's3://<bucket_name>/<prefix_name>/valid',\n 'test': 's3://<bucket_name>/<prefix_name>/test'\n)\n```\n\nFinally, the following Python code snippet illustrates the process of serving RoBERTox via a live SageMaker endpoint for real-time text classification for a JSON request:\n\n```\nfrom sagemaker.huggingface import HuggingFaceModel\nfrom sagemaker import get_execution_role\nfrom sagemaker.predictor import Predictor\nfrom sagemaker.serializers import JSONSerializer\nfrom sagemaker.deserializers import JSONDeserializer\n\nclass Classifier(Predictor):\n def __init__(self, endpoint_name, sagemaker_session):\n super().__init__(endpoint_name, sagemaker_session,\n serializer=JSONSerializer(),\n deserializer=JSONDeserializer())\n\n\nhf_model = HuggingFaceModel(\n role=get_execution_role(),\n model_data=<s3_model_and_tokenizer.tar.gz>,\n entry_point=\"inference.py\",\n transformers_version=\"4.6.1\",\n pytorch_version=\"1.7.1\",\n py_version=\"py36\",\n predictor_cls=Classifier\n)\n\npredictor = hf_model.deploy(instance_type=<deploy_instance_type>, initial_instance_count=1)\n```\n\n#### **Evaluation of model performance: Jigsaw unintended bias dataset**\n\nThe following table contains performance metrics for models trained and evaluated on data from the Jigsaw Unintended Bias in Toxicity Detection Kaggle competition. We trained models for three different but interrelated tasks:\n\n- **Binary case** – The model was trained on the full training dataset to predict the ```toxicity```\n label only\n- **Fine-grained case** – The subset of the training data for which ```toxicity>=0.5```\n was used to predict other toxicity sub-type labels (```obscene```, ```threat```, ```insult```, ```identity_attack```, ```sexual_explicit```)\n- **Multitask case** – The full training dataset was used to predict all six labels simultaneously\n\nWe trained RNN and RoBERTa models for each of these three tasks using the Jigsaw-provided fractional labels, which correspond to the proportion of annotators who thought the label was appropriate for the text, as well as with binary labels combined with class weights in the network loss function. In the binary labeling scheme, the proportions were thresholded at 0.5 for each available label (1 if label>=0.5, 0 otherwise), and the model loss functions were weighted based on the relative proportions of each binary label in the training dataset. In all cases, we found that using the fractional labels directly resulted in the best performance, indicating the added value of the information inherent in the degree of agreement between annotators.\n\nWe display two model metrics: the average precision (AP), which provides a summary of the precision-recall curve by computing the weighted mean of the precision values achieved at each classification threshold, and the area under the receiver operating characteristic curve (AUC), which aggregates model performance across classification thresholds with respect to the true positive rate and false positive rate. Note that the true class for a given text instance in the test set corresponds to whether the true proportion is greater than or equal to 0.5 (1 if label>=0.5, 0 otherwise).\n\n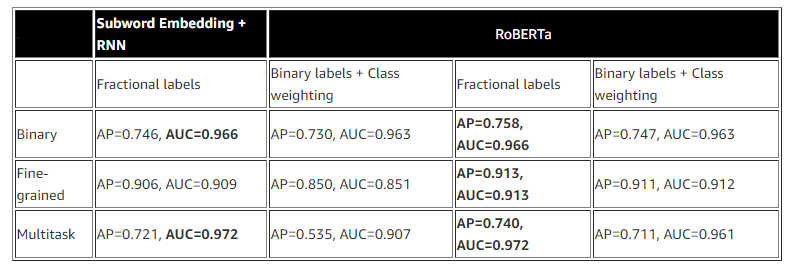\n\n#### **Conclusion**\n\nIn this post, we presented two text classification approaches for online conversations using AWS ML services. You can generalize these solutions across online communication platforms, with industries such as gaming particularly likely to benefit from improved ability to detect harmful content. In future posts, we plan to further discuss an end-to-end architecture for seamless deployment of models into your AWS account.\n\nIf you’d like help accelerating your use of ML in your products and processes, please contact the [Amazon ML Solutions Lab](https://aws.amazon.com/cn/ml-solutions-lab/).\n\n ——————————————————————————————————————————————— \n\n\n#### **About the Authors**\n\n **Ryan Brand**s a Data Scientist in the Amazon Machine Learning Solutions Lab. He has specific experience in applying machine learning to problems in healthcare and the life sciences, and in his free time he enjoys reading history and science fiction.\n\n **Sourav Bhabesh** is a Data Scientist at the Amazon ML Solutions Lab. He develops AI/ML solutions for AWS customers across various industries. His specialty is Natural Language Processing (NLP) and is passionate about deep learning. Outside of work he enjoys reading books and traveling.\n\n **Liutong Zhou** is an Applied Scientist at the Amazon ML Solutions Lab. He builds bespoke AI/ML solutions for AWS customers across various industries. He specializes in Natural Language Processing (NLP) and is passionate about multi-modal deep learning. He is a lyric tenor and enjoys singing operas outside of work.\n\n **Sia Gholami** is a Senior Data Scientist at the Amazon ML Solutions Lab, where he builds AI/ML solutions for customers across various industries. He is passionate about natural language processing (NLP) and deep learning. Outside of work, Sia enjoys spending time in nature and playing tennis.\n\n **Daniel Horowitz** is an Applied AI Science Manager. He leads a team of scientists on the Amazon ML Solutions Lab working to solve customer problems and drive cloud adoption with ML.\n\n\n\n\n\n\n","render":"<p>Online conversations are ubiquitous in modern life, spanning industries from video games to telecommunications. This has led to an exponential growth in the amount of online conversation data, which has helped in the development of state-of-the-art natural language processing (NLP) systems like chatbots and natural language generation (NLG) models. Over time, various NLP techniques for text analysis have also evolved. This necessitates the requirement for a fully managed service that can be integrated into applications using API calls without the need for extensive machine learning (ML) expertise. AWS offers pre-trained AWS AI services like <a href=\"https://aws.amazon.com/cn/comprehend/\" target=\"_blank\">Amazon Comprehend</a>, which can effectively handle NLP use cases involving classification, text summarization, entity recognition, and more to gather insights from text.</p>\n<p>Additionally, online conversations have led to a wide-spread phenomenon of non-traditional usage of language. Traditional NLP techniques often perform poorly on this text data due to the constantly evolving and domain-specific vocabularies that exist within different platforms, as well as the significant lexical deviations of words from proper English, either by accident or intentionally as a form of adversarial attack.</p>\n<p>In this post, we describe multiple ML approaches for text classification of online conversations with tools and services available on AWS.</p>\n<h4><a id=\"Prerequisites_6\"></a><strong>Prerequisites</strong></h4>\n<p>Before diving deep into this use case, please complete the following prerequisites:</p>\n<ol>\n<li>Set up an <a href=\"https://aws.amazon.com/cn/getting-started/guides/setup-environment/module-one/\" target=\"_blank\">AWS account</a> and <a href=\"https://aws.amazon.com/cn/getting-started/guides/setup-environment/module-two/\" target=\"_blank\">create an IAM user</a>.</li>\n<li>Set up the <a href=\"https://aws.amazon.com/cn/getting-started/guides/setup-environment/module-three/\" target=\"_blank\">AWS CLI</a> and <a href=\"https://aws.amazon.com/tools/\" target=\"_blank\">AWS SDKs</a>.</li>\n<li>(Optional) Set up your <a href=\"https://aws.amazon.com/cn/getting-started/guides/setup-environment/module-four/\" target=\"_blank\">Cloud9 IDE environment</a>.</li>\n</ol>\n<h4><a id=\"Dataset_14\"></a><strong>Dataset</strong></h4>\n<p>For this post, we use the <a href=\"https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification/overview\" target=\"_blank\">Jigsaw Unintended Bias in Toxicity Classification dataset</a>, a benchmark for the specific problem of classification of toxicity in online conversations. The dataset provides toxicity labels as well as several subgroup attributes such as obscene, identity attack, insult, threat, and sexually explicit. Labels are provided as fractional values, which represent the proportion of human annotators who believed the attribute applied to a given piece of text, which are rarely unanimous. To generate binary labels (for example, toxic or non-toxic), a threshold of 0.5 is applied to the fractional values, and comments with values greater than the threshold are treated as the positive class for that label.</p>\n<h4><a id=\"Subword_embedding_and_RNNs_18\"></a><strong>Subword embedding and RNNs</strong></h4>\n<p>For our first modeling approach, we use a combination of subword embedding and recurrent neural networks (RNNs) to train text classification models. Subword embeddings were introduced by <a href=\"https://arxiv.org/abs/1607.04606\" target=\"_blank\">Bojanowski et al. in 2017</a> as an improvement upon previous word-level embedding methods. Traditional Word2Vec skip-gram models are trained to learn a static vector representation of a target word that optimally predicts that word’s context. Subword models, on the other hand, represent each target word as a bag of the character n-grams that make up the word, where an n-gram is composed of a set of n consecutive characters. This method allows for the embedding model to better represent the underlying morphology of related words in the corpus as well as the computation of embeddings for novel, out-of-vocabulary (OOV) words. This is particularly important in the context of online conversations, a problem space in which users often misspell words (sometimes intentionally to evade detection) and also use a unique, constantly evolving vocabulary that might not be captured by a general training corpus.</p>\n<p><a href=\"https://aws.amazon.com/cn/sagemaker/\" target=\"_blank\">Amazon SageMaker</a> makes it easy to train and optimize an unsupervised subword embedding model on your own corpus of domain-specific text data with the built-in <a href=\"https://docs.aws.amazon.com/sagemaker/latest/dg/blazingtext.html\" target=\"_blank\">BlazingText algorithm</a>. We can also download existing general-purpose models trained on large datasets of online text, such as the following <a href=\"https://fasttext.cc/docs/en/english-vectors.html\" target=\"_blank\">English language models available directly from fastText</a>. From your SageMaker notebook instance, simply run the following to download a pretrained fastText model:</p>\n<pre><code class=\"lang-\">!wget -O vectors.zip https://dl.fbaipublicfiles.com/fasttext/vectors-english/crawl-300d-2M-subword.zip\n</code></pre>\n<p>Whether you’ve trained your own embeddings with BlazingText or downloaded a pretrained model, the result is a zipped model binary that you can use with the gensim library to embed a given target word as a vector based on its constituent subwords:</p>\n<pre><code class=\"lang-\"># Imports\nimport os\nfrom zipfile import ZipFile\nfrom gensim.models.fasttext import load_facebook_vectors\n\n# Unzip the model binary into 'dir_path'\nwith ZipFile('vectors.zip', 'r') as zipObj:\n zipObj.extractall(path=<dir_path_name>)\n\n# Load embedding model into memory\nembed_model = load_facebook_vectors(os.path.join(<dir_path_name>, 'vectors.bin'))\n\n# Compute embedding vector for 'word'\nword_embedding = embed_model[word]\n</code></pre>\n<p>After we preprocess a given segment of text, we can use this approach to generate a vector representation for each of the constituent words (as separated by spaces). We then use SageMaker and a deep learning framework such as PyTorch to train a customized RNN with a binary or multilabel classification objective to predict whether the text is toxic or not and the specific sub-type of toxicity based on labeled training examples.</p>\n<p>To upload your preprocessed text to<a href=\"https://aws.amazon.com/cn/s3/\" target=\"_blank\"> Amazon Simple Storage Service</a> (Amazon S3), use the following code:</p>\n<pre><code class=\"lang-\">import boto3\ns3 = boto3.client('s3')\n\nbucket = <bucket_name>\nprefix = <prefix_name>\n\ns3.upload_file('train.pkl', bucket, os.path.join(prefix, 'train/train.pkl'))\ns3.upload_file('valid.pkl', bucket, os.path.join(prefix, 'valid/valid.pkl'))\ns3.upload_file('test.pkl', bucket, os.path.join(prefix, 'test/test.pkl'))\n</code></pre>\n<p>To initiate scalable, multi-GPU model training with SageMaker, enter the following code:</p>\n<pre><code class=\"lang-\">import sagemaker\nsess = sagemaker.Session()\nrole = iam.get_role(RoleName= ‘AmazonSageMakerFullAccess’)['Role']['Arn']\n\nfrom sagemaker.pytorch import PyTorch\n\n# hyperparameters, which are passed into the training job\nhyperparameters = {\n 'epochs': 20, # Maximum number of epochs to train model\n 'train-batch-size': 128, # Training batch size (No. sentences)\n 'eval-batch-size': 1024, # Evaluation batch size (No. sentences)\n 'embed-size': 300, # Vector dimension of word embeddings (Must match embedding model)\n 'lstm-hidden-size': 200, # Number of neurons in LSTM hidden layer\n 'lstm-num-layers': 2, # Number of stacked LSTM layers\n 'proj-size': 100, # Number of neurons in intermediate projection layer\n 'num-targets': len(<list_of_label_names>), # Number of targets for classification\n 'class-weight': ' '.join([str(c) for c in <list_of_weights_per_class>]), # Weight to apply to each target during training\n 'total-length':<max_number_of_words_per_sentence>,\n 'metric-for-best-model': 'ap_score_weighted', # Metric on which to select the best model\n}\n\n# create the Estimator\npytorch_estimator = PyTorch(\n entry_point='train.py',\n source_dir=<source_dir_path>,\n instance_type=<train_instance_type>,\n volume_size=200,\n instance_count=1,\n role=role,\n framework_version='1.6.0’,\n py_version='py36',\n hyperparameters=hyperparameters,\n metric_definitions=[\n {'Name': 'validation:accuracy', 'Regex': 'eval_accuracy = (.*?);'},\n {'Name': 'validation:f1-micro', 'Regex': 'eval_f1_score_micro = (.*?);'},\n {'Name': 'validation:f1-macro', 'Regex': 'eval_f1_score_macro = (.*?);'},\n {'Name': 'validation:f1-weighted', 'Regex': 'eval_f1_score_weighted = (.*?);'},\n {'Name': 'validation:ap-micro', 'Regex': 'eval_ap_score_micro = (.*?);'},\n {'Name': 'validation:ap-macro', 'Regex': 'eval_ap_score_macro = (.*?);'},\n {'Name': 'validation:ap-weighted', 'Regex': 'eval_ap_score_weighted = (.*?);'},\n {'Name': 'validation:auc-micro', 'Regex': 'eval_auc_score_micro = (.*?);'},\n {'Name': 'validation:auc-macro', 'Regex': 'eval_auc_score_macro = (.*?);'},\n {'Name': 'validation:auc-weighted', 'Regex': 'eval_auc_score_weighted = (.*?);'}\n ]\n)\n\npytorch_estimator.fit(\n {\n 'train': 's3://<bucket_name>/<prefix_name>/train',\n 'valid': 's3://<bucket_name>/<prefix_name>/valid',\n 'test': 's3://<bucket_name>/<prefix_name>/test'\n }\n)\n</code></pre>\n<p>Within <source_dir_path>, we define a PyTorch Dataset that is used by train.py to prepare the text data for training and evaluation of the model:</p>\n<pre><code class=\"lang-\">def pad_matrix(m: torch.Tensor, max_len: int =100)-> tuple[int, torch.Tensor] :\n """Pads an embedding matrix to a specified maximum length."""\n if m.ndim == 1:\n m = m.reshape(1, -1)\n mask = np.ones_like(m)\n if m.shape[0] > max_len:\n m = m[:max_len, :]\n mask = mask[:max_len, :]\n else:\n m = np.pad(m, ((0, max_len - m.shape[0]), (0,0)))\n mask = np.pad(mask, ((0, max_len - mask.shape[0]), (0,0)))\n return m, mask\n\n\nclass EmbeddingDataset(Dataset: torch.utils.data.Dataset):\n """PyTorch dataset representing pretrained sentence embeddings, masks, and labels."""\n def __init__(self, text: str, labels: int, max_len: int=100):\n self.text = text\n self.labels = labels\n self.max_len = max_len\n\n def __len__(self) -> int:\n return len(self.labels)\n\n def __getitem__(self, idx: int) -> dict: \n e = embed_line(self.text[idx])\n length = e.shape[0]\n m, mask = pad_matrix(e, max_len=self.max_len)\n \n item = {}\n item['embeddings'] = torch.from_numpy(m)\n item['mask'] = torch.from_numpy(mask)\n item['labels'] = torch.tensor(self.labels[idx])\n if length > self.max_len:\n item['lengths'] = torch.tensor(self.max_len)\n else:\n item['lengths'] = torch.tensor(length)\n \n return item\n</code></pre>\n<p>Note that this code anticipates that the <code>vectors.zip</code>file containing your fastText or BlazingText embeddings will be stored in <source_dir_path>.</p>\n<p>Additionally, you can easily deploy pretrained fastText models on their own to live SageMaker endpoints to compute embedding vectors on the fly for use in relevant word-level tasks. See the following <a href=\"https://github.com/aws/amazon-sagemaker-examples/blob/main/introduction_to_amazon_algorithms/blazingtext_hosting_pretrained_fasttext/blazingtext_hosting_pretrained_fasttext.ipynb\" target=\"_blank\">GitHub example</a> for more details.</p>\n<h4><a id=\"Transformers_with_Hugging_Face_168\"></a><strong>Transformers with Hugging Face</strong></h4>\n<p>For our second modeling approach, we transition to the usage of Transformers, introduced in the paper <a href=\"https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf\" target=\"_blank\">Attention Is All You Need</a>. Transformers are deep learning models designed to deliberately avoid the pitfalls of RNNs by relying on a self-attention mechanism to draw global dependencies between input and output. The Transformer model architecture allows for significantly better parallelization and can achieve high performance in relatively short training time.</p>\n<p>Built on the success of Transformers, BERT, introduced in the paper <a href=\"https://arxiv.org/abs/1810.04805\" target=\"_blank\">BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding</a>, added bidirectional pre-training for language representation. Inspired by the Cloze task, BERT is pre-trained with masked language modeling (MLM), in which the model learns to recover the original words for randomly masked tokens. The BERT model is also pretrained on the next sentence prediction (NSP) task to predict if two sentences are in correct reading order. Since its advent in 2018, BERT and its variations have been widely used in text classification tasks.</p>\n<p>Our solution uses a variant of BERT known as RoBERTa, which was introduced in the paper <a href=\"https://arxiv.org/abs/1907.11692\" target=\"_blank\">RoBERTa: A Robustly Optimized BERT Pretraining Approach</a>. RoBERTa further improves BERT performance on a variety of natural language tasks by optimized model training, including training models longer on a 10 times larger bigger corpus, using optimized hyperparameters, dynamic random masking, removing the NSP task, and more.</p>\n<p>Our RoBERTa-based models use the <a href=\"https://huggingface.co/docs/transformers/index\" target=\"_blank\">Hugging Face Transformers</a> library, which is a popular open-source Python framework that provides high-quality implementations of all kinds of state-of-the-art Transformer models for a variety of NLP tasks. <a href=\"https://huggingface.co/blog/the-partnership-amazon-sagemaker-and-hugging-face\" target=\"_blank\">Hugging Face has partnered with AWS</a> to enable you to easily train and deploy Transformer models on SageMaker. This functionality is available through <a href=\"https://github.com/aws/deep-learning-containers/blob/master/available_images.md#huggingface-training-containers\" target=\"_blank\">Hugging Face AWS Deep Learning Container images</a>, which include the Transformers, Tokenizers, and Datasets libraries, and optimized integration with SageMaker for model training and inference.</p>\n<p>In our implementation, we inherit the RoBERTa architecture backbone from the Hugging Face Transformers framework and use SageMaker to train and deploy our own text classification model, which we call RoBERTox. RoBERTox uses byte pair encoding (BPE), introduced in <a href=\"https://arxiv.org/abs/1508.07909\" target=\"_blank\">Neural Machine Translation of Rare Words with Subword Units</a>, to tokenize input text into subword representations. We can then train our models and tokenizers on the Jigsaw data or any large domain-specific corpus (such as the chat logs from a specific game) and use them for customized text classification. We define our custom classification model class in the following code:</p>\n<pre><code class=\"lang-\">class RoBERToxForSequenceClassification(CustomLossMixIn, RobertaPreTrainedModel):\n _keys_to_ignore_on_load_missing = [r"position_ids"]\n\n def __init__(self, config: PretrainedConfig, *inputs, **kwargs):\n """Initialize the RoBERToxForSequenceClassification instance\n\n Parameters\n ----------\n config : PretrainedConfig\n num_labels : Optional[int]\n if not None, overwrite the default classification head in pretrained model.\n mode : Optional[str]\n 'MULTI_CLASS', 'MULTI_LABEL' or "REGRESSION". Used to determine loss\n class_weight : Optional[List[float]]\n If not None, add class weight to BCEWithLogitsLoss or CrossEntropyLoss\n """\n super().__init__(config, *inputs, **kwargs)\n # Define model architecture\n self.roberta = RobertaModel(self.config, add_pooling_layer=False)\n self.classifier = RobertaClassificationHead(self.config)\n self.init_weights()\n\n @modeling_roberta.add_start_docstrings_to_model_forward(\n modeling_roberta.ROBERTA_INPUTS_DOCSTRING.format("batch_size, sequence_length")\n )\n @modeling_roberta.add_code_sample_docstrings(\n tokenizer_class=modeling_roberta._TOKENIZER_FOR_DOC,\n checkpoint=modeling_roberta._CHECKPOINT_FOR_DOC,\n output_type=SequenceClassifierOutput,\n config_class=modeling_roberta._CONFIG_FOR_DOC,\n )\n def forward(\n self,\n input_ids: torch.Tensor = None,\n attention_mask: torch.Tensor = None,\n token_type_ids: torch.Tensor = None,\n position_ids: torch.Tensor =None,\n head_mask: torch.Tensor =None,\n inputs_embeds: torch.Tensor =None,\n labels: torch.Tensor =None,\n output_attentions: torch.Tensor =None,\n output_hidden_states: torch.Tensor =None,\n return_dict: bool =None,\n sample_weights: torch.Tensor =None,\n ) -> : dict:\n """Forward pass to return loss, logits, ...\n\n Returns\n --------\n output : SequenceClassifierOutput\n has those keys: loss, logits, hidden states, attentions\n """\n return_dict = return_dict or self.config.use_return_dict\n\n outputs = self.roberta(\n input_ids,\n attention_mask=attention_mask,\n token_type_ids=token_type_ids,\n position_ids=position_ids,\n head_mask=head_mask,\n inputs_embeds=inputs_embeds,\n output_attentions=output_attentions,\n output_hidden_states=output_hidden_states,\n return_dict=return_dict,\n )\n sequence_output = outputs[0] # [CLS] embedding\n logits = self.classifier(sequence_output)\n loss = self.compute_loss(logits, labels, sample_weights=sample_weights)\n\n if not return_dict:\n output = (logits,) + outputs[2:]\n return ((loss,) + output) if loss is not None else output\n\n return SequenceClassifierOutput(\n loss=loss,\n logits=logits,\n hidden_states=outputs.hidden_states,\n attentions=outputs.attentions,\n )\n\n def compute_loss(self, logits: torch.Tensor, labels: torch.Tensor, sample_weights: Optional[torch.Tensor] = None) -> torch.FloatTensor:\n return super().compute_loss(logits, labels, sample_weights)\n</code></pre>\n<p>Before training, we prepare our text data and labels using Hugging Face’s datasets library and upload the result to Amazon S3:</p>\n<pre><code class=\"lang-\">from datasets import Dataset\nimport multiprocessing\n\ndata_train = Dataset.from_pandas(df_train)\n…\n\ntokenizer = <instantiated_huggingface_tokenizer>\n\ndef preprocess_function(examples: examples) -> torch.Tensor:\n result = tokenizer(examples["text"], padding="max_length", max_length=128, truncation=True)\n return result\n\nnum_proc = multiprocessing.cpu_count()\nprint("Number of CPUs =", num_proc)\n\ndata_train = data_train.map(\n preprocess_function,\n batched=True,\n load_from_cache_file=False,\n num_proc=num_proc\n)\n…\n\nimport botocore\nfrom datasets.filesystems import S3FileSystem\n\ns3_session = botocore.session.Session()\n\n# create S3FileSystem instance with s3_session\ns3 = S3FileSystem(session=s3_session) \n\n# saves encoded_dataset to your s3 bucket\ndata_train.save_to_disk(f's3://<bucket_name>/<prefix_name>/train', fs=s3)\n… \n</code></pre>\n<p>We initiate training of the model in a similar fashion to the RNN:</p>\n<pre><code class=\"lang-\">import sagemaker\nsess = sagemaker.Session()\nrole = sagemaker.get_execution_role()\nfrom sagemaker.huggingface import HuggingFace\n\n# hyperparameters, which are passed into the training job\nhyperparameters = {\n 'model-name': <huggingface_base_model_name>,\n 'epochs': 10,\n 'train-batch-size': 32,\n 'eval-batch-size': 64,\n 'num-labels': len(<list_of_label_names>),\n 'class-weight': ' '.join([str(c) for c in <list_of_class_weights>]),\n 'metric-for-best-model': 'ap_score_weighted',\n 'save-total-limit': 1,\n}\n\n# create the Estimator\nhuggingface_estimator = HuggingFace(\n entry_point='train.py',\n source_dir=<source_dir_path>,\n instance_type=<train_instance_type>,\n instance_count=1,\n role=role,\n transformers_version='4.6.1',\n pytorch_version='1.7.1',\n py_version='py36',\n hyperparameters=hyperparameters,\n metric_definitions=[\n {'Name': 'validation:accuracy', 'Regex': 'eval_accuracy = (.*?);'},\n {'Name': 'validation:f1-micro', 'Regex': 'eval_f1_score_micro = (.*?);'},\n {'Name': 'validation:f1-macro', 'Regex': 'eval_f1_score_macro = (.*?);'},\n {'Name': 'validation:f1-weighted', 'Regex': 'eval_f1_score_weighted = (.*?);'},\n {'Name': 'validation:ap-micro', 'Regex': 'eval_ap_score_micro = (.*?);'},\n {'Name': 'validation:ap-macro', 'Regex': 'eval_ap_score_macro = (.*?);'},\n {'Name': 'validation:ap-weighted', 'Regex': 'eval_ap_score_weighted = (.*?);'},\n {'Name': 'validation:auc-micro', 'Regex': 'eval_auc_score_micro = (.*?);'},\n {'Name': 'validation:auc-macro', 'Regex': 'eval_auc_score_macro = (.*?);'},\n {'Name': 'validation:auc-weighted', 'Regex': 'eval_auc_score_weighted = (.*?);'}\n ]\n)\n\nhuggingface_estimator.fit(\n {\n 'train': 's3://<bucket_name>/<prefix_name>/train',\n 'valid': 's3://<bucket_name>/<prefix_name>/valid',\n 'test': 's3://<bucket_name>/<prefix_name>/test'\n)\n</code></pre>\n<p>Finally, the following Python code snippet illustrates the process of serving RoBERTox via a live SageMaker endpoint for real-time text classification for a JSON request:</p>\n<pre><code class=\"lang-\">from sagemaker.huggingface import HuggingFaceModel\nfrom sagemaker import get_execution_role\nfrom sagemaker.predictor import Predictor\nfrom sagemaker.serializers import JSONSerializer\nfrom sagemaker.deserializers import JSONDeserializer\n\nclass Classifier(Predictor):\n def __init__(self, endpoint_name, sagemaker_session):\n super().__init__(endpoint_name, sagemaker_session,\n serializer=JSONSerializer(),\n deserializer=JSONDeserializer())\n\n\nhf_model = HuggingFaceModel(\n role=get_execution_role(),\n model_data=<s3_model_and_tokenizer.tar.gz>,\n entry_point="inference.py",\n transformers_version="4.6.1",\n pytorch_version="1.7.1",\n py_version="py36",\n predictor_cls=Classifier\n)\n\npredictor = hf_model.deploy(instance_type=<deploy_instance_type>, initial_instance_count=1)\n</code></pre>\n<h4><a id=\"Evaluation_of_model_performance_Jigsaw_unintended_bias_dataset_386\"></a><strong>Evaluation of model performance: Jigsaw unintended bias dataset</strong></h4>\n<p>The following table contains performance metrics for models trained and evaluated on data from the Jigsaw Unintended Bias in Toxicity Detection Kaggle competition. We trained models for three different but interrelated tasks:</p>\n<ul>\n<li><strong>Binary case</strong> – The model was trained on the full training dataset to predict the <code>toxicity</code><br />\nlabel only</li>\n<li><strong>Fine-grained case</strong> – The subset of the training data for which <code>toxicity>=0.5</code><br />\nwas used to predict other toxicity sub-type labels (<code>obscene</code>, <code>threat</code>, <code>insult</code>, <code>identity_attack</code>, <code>sexual_explicit</code>)</li>\n<li><strong>Multitask case</strong> – The full training dataset was used to predict all six labels simultaneously</li>\n</ul>\n<p>We trained RNN and RoBERTa models for each of these three tasks using the Jigsaw-provided fractional labels, which correspond to the proportion of annotators who thought the label was appropriate for the text, as well as with binary labels combined with class weights in the network loss function. In the binary labeling scheme, the proportions were thresholded at 0.5 for each available label (1 if label>=0.5, 0 otherwise), and the model loss functions were weighted based on the relative proportions of each binary label in the training dataset. In all cases, we found that using the fractional labels directly resulted in the best performance, indicating the added value of the information inherent in the degree of agreement between annotators.</p>\n<p>We display two model metrics: the average precision (AP), which provides a summary of the precision-recall curve by computing the weighted mean of the precision values achieved at each classification threshold, and the area under the receiver operating characteristic curve (AUC), which aggregates model performance across classification thresholds with respect to the true positive rate and false positive rate. Note that the true class for a given text instance in the test set corresponds to whether the true proportion is greater than or equal to 0.5 (1 if label>=0.5, 0 otherwise).</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/ab2c10c1964d4973a34d2bf73d325c3e_image.png\" alt=\"image.png\" /></p>\n<h4><a id=\"Conclusion_402\"></a><strong>Conclusion</strong></h4>\n<p>In this post, we presented two text classification approaches for online conversations using AWS ML services. You can generalize these solutions across online communication platforms, with industries such as gaming particularly likely to benefit from improved ability to detect harmful content. In future posts, we plan to further discuss an end-to-end architecture for seamless deployment of models into your AWS account.</p>\n<p>If you’d like help accelerating your use of ML in your products and processes, please contact the <a href=\"https://aws.amazon.com/cn/ml-solutions-lab/\" target=\"_blank\">Amazon ML Solutions Lab</a>.</p>\n<p>———————————————————————————————————————————————</p>\n<h4><a id=\"About_the_Authors_411\"></a><strong>About the Authors</strong></h4>\n<p><img src=\"https://dev-media.amazoncloud.cn/62a2860cf3b146748870ded31a286595_image.png\" alt=\"image.png\" /> <strong>Ryan Brand</strong>s a Data Scientist in the Amazon Machine Learning Solutions Lab. He has specific experience in applying machine learning to problems in healthcare and the life sciences, and in his free time he enjoys reading history and science fiction.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/689bc7f28e8544c9904e0771ea1ea280_image.png\" alt=\"image.png\" /> <strong>Sourav Bhabesh</strong> is a Data Scientist at the Amazon ML Solutions Lab. He develops AI/ML solutions for AWS customers across various industries. His specialty is Natural Language Processing (NLP) and is passionate about deep learning. Outside of work he enjoys reading books and traveling.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/9acd3a7629a5498ebbf607534ebb05fd_image.png\" alt=\"image.png\" /> <strong>Liutong Zhou</strong> is an Applied Scientist at the Amazon ML Solutions Lab. He builds bespoke AI/ML solutions for AWS customers across various industries. He specializes in Natural Language Processing (NLP) and is passionate about multi-modal deep learning. He is a lyric tenor and enjoys singing operas outside of work.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/bcf1e0513f0147c488ae3aec3756a0c8_image.png\" alt=\"image.png\" /> <strong>Sia Gholami</strong> is a Senior Data Scientist at the Amazon ML Solutions Lab, where he builds AI/ML solutions for customers across various industries. He is passionate about natural language processing (NLP) and deep learning. Outside of work, Sia enjoys spending time in nature and playing tennis.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/fd33fe1aa4344de0b1ad29b38d88c7c5_image.png\" alt=\"image.png\" /> <strong>Daniel Horowitz</strong> is an Applied AI Science Manager. He leads a team of scientists on the Amazon ML Solutions Lab working to solve customer problems and drive cloud adoption with ML.</p>\n"}
Text classification for online conversations with machine learning on Amazon
海外精选

海外精选的内容汇集了全球优质的亚马逊云科技相关技术内容。同时,内容中提到的“AWS”
是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。

 0
0 0
0亚马逊云科技解决方案 基于行业客户应用场景及技术领域的解决方案
联系亚马逊云科技专家
亚马逊云科技解决方案
基于行业客户应用场景及技术领域的解决方案
联系专家

0
目录

 分享
分享 点赞
点赞 收藏
收藏 目录
目录立即注册,开启您的免费套餐
立即关注

亚马逊云开发者
公众号

User Group
公众号

亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
关于我们 
更多资源
开发者工具
更多支持
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
