{"value":"The process of building a machine learning (ML) model is iterative until you find the candidate model that is performing well and is ready to be deployed. As data scientists iterate through that process, they need a reliable method to easily track experiments to understand how each model version was built and how it performed.\n\n[Amazon SageMaker](https://aws.amazon.com/sagemaker/) allows teams to take advantage of a broad range of features to quickly prepare, build, train, deploy, and monitor ML models. [Amazon SageMaker Pipelines](https://aws.amazon.com/sagemaker/pipelines/) provides a repeatable process for iterating through model build activities, and is integrated with [Amazon SageMaker Experiments](https://docs.aws.amazon.com/sagemaker/latest/dg/experiments.html). By default, every SageMaker pipeline is associated with an experiment, and every run of that pipeline is tracked as a trial in that experiment. Then your iterations are automatically tracked without any additional steps.\n\nIn this post, we take a closer look at the motivation behind having an automated process to track experiments with Experiments and the native capabilities built into Pipelines.\n\n### **Why is it important to keep your experiments organized?**\n\nLet’s take a step back for a moment and try to understand why it’s important to have experiments organized for machine learning. When data scientists approach a new ML problem, they have to answer many different questions, from data availability to how they will measure model performance.\n\nAt the start, the process is full of uncertainty and is highly iterative. As a result, this experimentation phase can produce multiple models, each created from their own inputs (datasets, training scripts, and hyperparameters) and producing their own outputs (model artifacts and evaluation metrics). The challenge then is to keep track of all these inputs and outputs of each iteration.\n\nData scientists typically train many different model versions until they find the combination of data transformation, algorithm, and hyperparameters that results in the best performing version of a model. Each of these unique combinations is a single experiment. With a traceable record of the inputs, algorithms, and hyperparameters that were used by that trial, the data science team can find it easy to reproduce their steps.\n\nHaving an automated process in place to track experiments improves the ability to reproduce as well as deploy specific model versions that are performing well. The Pipelines native integration with Experiments makes it easy to automatically track and manage experiments across pipeline runs.\n\n\n### **Benefits of SageMaker Experiments**\n\nSageMaker Experiments allows data scientists organize, track, compare, and evaluate their training iterations.\n\nLet’s start first with an overview of what you can do with Experiments:\n\n- **Organize experiments** – Experiments structures experimentation with a top-level entity called an experiment that contains a set of trials. Each trial contains a set of steps called trial components. Each trial component is a combination of datasets, algorithms, and parameters. You can picture experiments as the top-level folder for organizing your hypotheses, your trials as the subfolders for each group test run, and your trial components as your files for each instance of a test run.\n- **Track experiments** – Experiments allows data scientists to track experiments. It offers the possibility to automatically assign SageMaker jobs to a trial via simple configurations and via the tracking SDKs.\n- **Compare and evaluate experiments** – The integration of Experiments with [Amazon SageMaker Studio](https://docs.aws.amazon.com/sagemaker/latest/dg/studio.html) makes it easy to produce data visualizations and compare different trials. You can also access the trial data via the Python SDK to generate your own visualization using your preferred plotting libraries.\n\nTo learn more about Experiments APIs and SDKs, we recommend the following documentation: [CreateExperiment](https://docs.aws.amazon.com/sagemaker/latest/APIReference/API_CreateExperiment.html) and [Amazon SageMaker Experiments Python SDK](https://sagemaker-experiments.readthedocs.io/en/latest/).\n\nIf you want to dive deeper, we recommend looking into the [amazon-sagemaker-examples/sagemaker-experiments GitHub repository](https://github.com/aws/amazon-sagemaker-examples/tree/main/sagemaker-experiments) for further examples.\n\n### **Integration between Pipelines and Experiments**\n\nThe model building pipelines that are part of Pipelines are purpose-built for ML and allow you to orchestrate your model build tasks using a pipeline tool that includes native integrations with other SageMaker features as well as the flexibility to extend your pipeline with steps run outside SageMaker. Each step defines an action that the pipeline takes. The dependencies between steps are defined by a direct acyclic graph (DAG) built using the Pipelines Python SDK. You can build a SageMaker pipeline programmatically via the same SDK. After a pipeline is deployed, you can optionally visualize its workflow within Studio.\n\nPipelines automatically integrate with Experiments by automatically creating an experiment and trial for every run. Pipelines automatically create an experiment and a trial for every run of the pipeline before running the steps unless one or both of these inputs are specified. While running the pipeline’s SageMaker job, the pipeline associates the trial with the experiment, and associates to the trial every trial component that is created by the job. Specifying your own experiment or trial programmatically allows you to fine-tune how to organize your experiments.\n\nThe workflow we present in this example consists of a series of steps: a preprocessing step to split our input dataset into train, test, and validation datasets; a tuning step to tune our hyperparameters and kick off training jobs to train a model using the [XGBoost built-in algorithm](https://docs.aws.amazon.com/sagemaker/latest/dg/xgboost.html); and finally a model step to create a SageMaker model from the best trained model artifact. Pipelines also offers several natively supported [step types](https://docs.aws.amazon.com/sagemaker/latest/dg/build-and-manage-steps.html) outside of what is discussed in this post. We also illustrate how you can track your pipeline workflow and generate metrics and comparison charts. Furthermore, we show how to associate the new trial generated to an existing experiment that might have been created before the pipeline was defined.\n\n### **SageMaker Pipelines code**\n\nYou can review and download the notebook from the [GitHub repository](https://github.com/aws-samples/sagemaker-experiments-and-pipelines/blob/main/02-PipelineExperiments.ipynb) associated with this post. We look at the Pipelines-specific code to understand it better.\n\nPipelines enables you to pass parameters at run time. Here we define the processing and training instance types and counts at run time with preset defaults:\n\n```\nbase_job_prefix = \"pipeline-experiment-sample\"\nmodel_package_group_name = \"pipeline-experiment-model-package\"\n\nprocessing_instance_count = ParameterInteger(\n name=\"ProcessingInstanceCount\", default_value=1\n)\n\ntraining_instance_count = ParameterInteger(\n name=\"TrainingInstanceCount\", default_value=1\n)\n\nprocessing_instance_type = ParameterString(\n name=\"ProcessingInstanceType\", default_value=\"ml.m5.xlarge\"\n)\ntraining_instance_type = ParameterString(\n name=\"TrainingInstanceType\", default_value=\"ml.m5.xlarge\"\n)\n```\n\nNext, we set up a processing script that downloads and splits the input dataset into train, test, and validation parts. We use ```SKLearnProcessor``` for running this preprocessing step. To do so, we define a processor object with the instance type and count needed to run the processing job.\n\nPipelines allows us to achieve data versioning in a programmatic way by using execution-specific variables like ```ExecutionVariables.PIPELINE_EXECUTION_ID```, which is the unique ID of a pipeline run. We can, for example, create a unique key for storing the output datasets in [Amazon Simple Storage Service ](http://aws.amazon.com/s3)(Amazon S3) that ties them to a specific pipeline run. For the full list of variables, refer to [Execution Variables](https://sagemaker.readthedocs.io/en/stable/workflows/pipelines/sagemaker.workflow.pipelines.html#execution-variables).\n\n```\nframework_version = \"0.23-1\"\n\nsklearn_processor = SKLearnProcessor(\n framework_version=framework_version,\n instance_type=processing_instance_type,\n instance_count=processing_instance_count,\n base_job_name=\"sklearn-ca-housing\",\n role=role,\n)\n\nprocess_step = ProcessingStep(\n name=\"ca-housing-preprocessing\",\n processor=sklearn_processor,\n outputs=[\n ProcessingOutput(\n output_name=\"train\",\n source=\"/opt/ml/processing/train\",\n destination=Join(\n on=\"/\",\n values=[\n \"s3://{}\".format(bucket),\n prefix,\n ExecutionVariables.PIPELINE_EXECUTION_ID,\n \"train\",\n ],\n ),\n ),\n ProcessingOutput(\n output_name=\"validation\",\n source=\"/opt/ml/processing/validation\",\n destination=Join(\n on=\"/\",\n values=[\n \"s3://{}\".format(bucket),\n prefix,\n ExecutionVariables.PIPELINE_EXECUTION_ID,\n \"validation\",\n ],\n )\n ),\n ProcessingOutput(\n output_name=\"test\",\n source=\"/opt/ml/processing/test\",\n destination=Join(\n on=\"/\",\n values=[\n \"s3://{}\".format(bucket),\n prefix,\n ExecutionVariables.PIPELINE_EXECUTION_ID,\n \"test\",\n ],\n )\n ),\n ],\n code=\"california-housing-preprocessing.py\",\n)\n\n\n```\n\nThen we move on to create an estimator object to train an XGBoost model. We set some static hyperparameters that are commonly used with XGBoost:\n\n```\nmodel_path = f\"s3://{default_bucket}/{base_job_prefix}/ca-housing-experiment-pipeline\"\n\nimage_uri = sagemaker.image_uris.retrieve(\n framework=\"xgboost\",\n region=region,\n version=\"1.2-2\",\n py_version=\"py3\",\n instance_type=training_instance_type,\n)\n\nxgb_train = Estimator(\n image_uri=image_uri,\n instance_type=training_instance_type,\n instance_count=training_instance_count,\n output_path=model_path,\n base_job_name=f\"{base_job_prefix}/ca-housing-train\",\n sagemaker_session=sagemaker_session,\n role=role,\n)\n\nxgb_train.set_hyperparameters(\n eval_metric=\"rmse\",\n objective=\"reg:squarederror\", # Define the object metric for the training job\n num_round=50,\n max_depth=5,\n eta=0.2,\n gamma=4,\n min_child_weight=6,\n subsample=0.7\n)\n\n```\n\nWe do hyperparameter tuning of the models we create by using a ```ContinuousParameter``` range for ```lambda```. Choosing one metric to be the objective metric tells the tuner (the instance that runs the hyperparameters tuning jobs) that you will evaluate the training job based on this specific metric. The tuner returns the best combination based on the best value for this objective metric, meaning the best combination that minimizes the best root mean square error (RMSE).\n\n```\nobjective_metric_name = \"validation:rmse\"\n\nhyperparameter_ranges = {\n \"lambda\": ContinuousParameter(0.01, 10, scaling_type=\"Logarithmic\")\n}\n\ntuner = HyperparameterTuner(estimator,\n objective_metric_name,\n hyperparameter_ranges,\n objective_type=objective_type,\n strategy=\"Bayesian\",\n max_jobs=10,\n max_parallel_jobs=3)\n\ntune_step = TuningStep(\n name=\"HPTuning\",\n tuner=tuner_log,\n inputs={\n \"train\": TrainingInput(\n s3_data=process_step.properties.ProcessingOutputConfig.Outputs[\n \"train\"\n ].S3Output.S3Uri,\n content_type=\"text/csv\",\n ),\n \"validation\": TrainingInput(\n s3_data=process_step.properties.ProcessingOutputConfig.Outputs[\n \"validation\"\n ].S3Output.S3Uri,\n content_type=\"text/csv\",\n ),\n } \n)\n```\nThe tuning step runs multiple trials with the goal of determining the best model among the parameter ranges tested. With the``` method get_top_model_s3_uri```, we rank the top 50 performing versions of the model artifact S3 URI and only extract the best performing version (we specify ```k=0``` for the best) to create a SageMaker model.\n\n```\nmodel_bucket_key = f\"{default_bucket}/{base_job_prefix}/ca-housing-experiment-pipeline\"\nmodel_candidate = Model(\n image_uri=image_uri,\n model_data=tune_step.get_top_model_s3_uri(top_k=0, s3_bucket=model_bucket_key),\n sagemaker_session=sagemaker_session,\n role=role,\n predictor_cls=XGBoostPredictor,\n)\n\ncreate_model_step = CreateModelStep(\n name=\"CreateTopModel\",\n model=model_candidate,\n inputs=sagemaker.inputs.CreateModelInput(instance_type=\"ml.m4.large\"),\n)\n\n```\n\nWhen the pipeline runs, it creates trial components for each hyperparameter tuning job and each SageMaker job created by the pipeline steps.\n\nYou can further configure the integration of pipelines with Experiments by creating a ```PipelineExperimentConfig``` object and pass it to the pipeline object. The two parameters define the name of the experiment that will be created, and the trial that will refer to the whole run of the pipeline.\n\nIf you want to associate a pipeline run to an existing experiment, you can pass its name, and Pipelines will associate the new trial to it. You can prevent the creation of an experiment and trial for a pipeline run by setting ```pipeline_experiment_config ```to ```None```.\n\n```\n#Pipeline experiment config\nca_housing_experiment_config = PipelineExperimentConfig(\n experiment_name,\n Join(\n on=\"-\",\n values=[\n \"pipeline-execution\",\n ExecutionVariables.PIPELINE_EXECUTION_ID\n ],\n )\n)\n```\n\nWe pass on the instance types and counts as parameters, and chain the preceding steps in order as follows. The pipeline workflow is implicitly defined by the outputs of a step being the inputs of another step.\n\n```\npipeline_name = f\"CAHousingExperimentsPipeline\"\n\npipeline = Pipeline(\n name=pipeline_name,\n pipeline_experiment_config=ca_housing_experiment_config,\n parameters=[\n processing_instance_count,\n processing_instance_type,\n training_instance_count,\n training_instance_type\n ],\n steps=[process_step,tune_step,create_model_step],\n)\n```\n\nThe full-fledged pipeline is now created and ready to go. We add an execution role to the pipeline and start it. From here, we can go to the SageMaker Studio Pipelines console and visually track every step. You can also access the linked logs from the console to debug a pipeline.\n\n```\npipeline.upsert(role_arn=sagemaker.get_execution_role())\nexecution = pipeline.start()\n```\n\n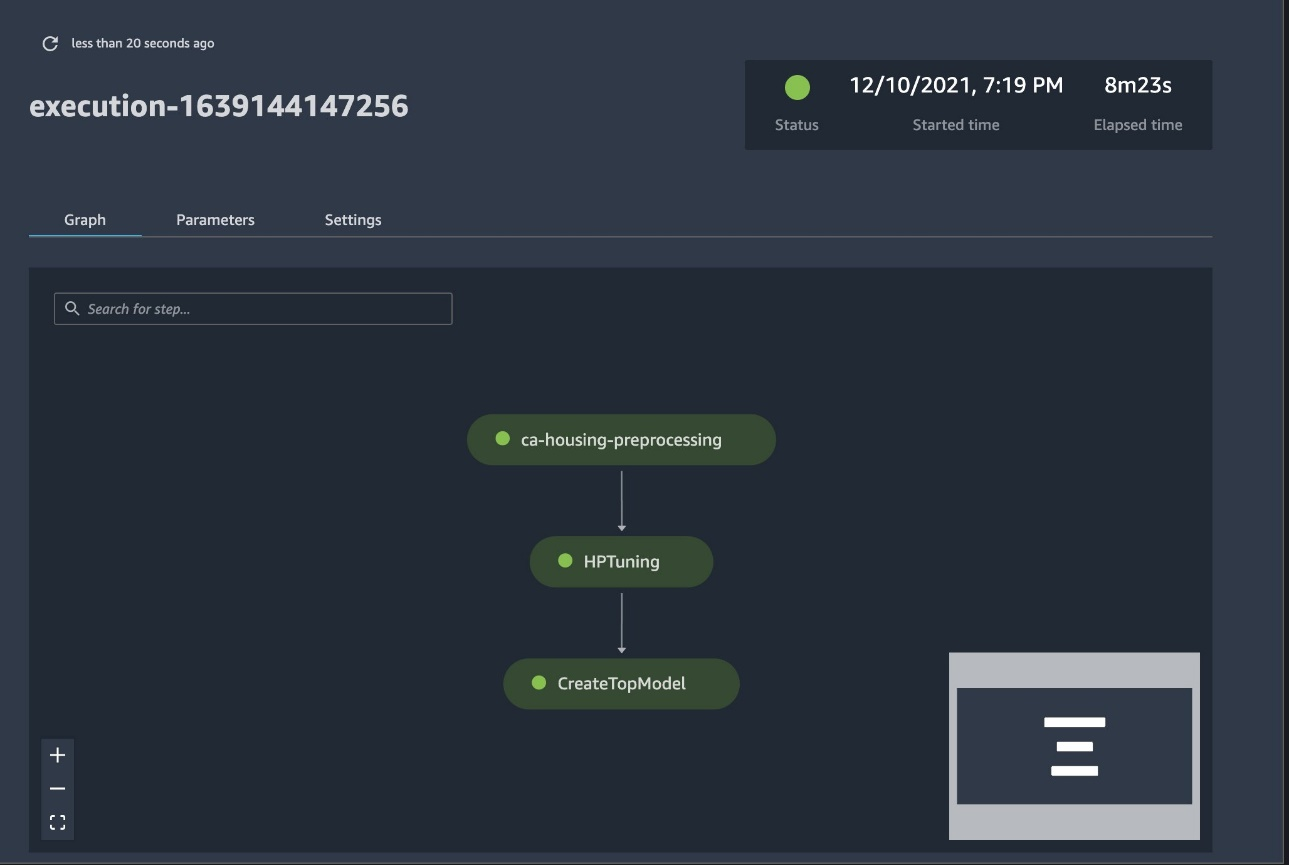\n\nThe preceding screenshot shows in green a successfully run pipeline. We obtain the metrics of one trial from a run of the pipeline with the following code:\n\n\n```\n# SM Pipeline injects the Execution ID into trial component names\nexecution_id = execution.describe()['PipelineExecutionArn'].split('/')[-1]\nsource_arn_filter = Filter(\n name=\"TrialComponentName\", operator=Operator.CONTAINS, value=execution_id\n)\n\nsource_type_filter = Filter(\n name=\"Source.SourceType\", operator=Operator.EQUALS, value=\"SageMakerTrainingJob\"\n)\n\nsearch_expression = SearchExpression(\n filters=[source_arn_filter, source_type_filter]\n)\n\ntrial_component_analytics = ExperimentAnalytics(\n sagemaker_session=sagemaker_session,\n experiment_name=experiment_name,\n search_expression=search_expression.to_boto()\n)\n\nanalytic_table = trial_component_analytics.dataframe()\nanalytic_table.head()\n```\n\n### **Compare the metrics for each trial component**\n\nYou can plot the results of hyperparameter tuning in Studio or via other Python plotting libraries. We show both ways of doing this.\n\n##### **Explore the training and evaluation metrics in Studio**\n\nStudio provides an interactive user interface where you can generate interactive plots. The steps are as follows:\n\n1. Choose **Experiments and Trials** from the **SageMaker resources** icon on the left sidebar.\n2. Choose your experiment to open it.\n3. Choose (right-click) the trial of interest.\n4. Choose **Open in trial component list**.\n5. Press **Shift** to select the trial components representing the training jobs.\n6. Choose **Add chart**.\n7. Choose **New chart** and customize it to plot the collected metrics that you want to analyze. For our use case, choose the following:\n a. For **Data type**¸ select **Summary Statistics**.\n b. For **Chart type**¸ select **Scatter Plot**.\n c. For **X-axis**, choose ```lambda```.\n d. For **Y-axis**, choose ```validation:rmse_last```.\n\n\nThe new chart appears at the bottom of the window, labeled as ‘8’.\n\nYou can include more or fewer training jobs by pressing Shift and choosing the eye icon for a more interactive experience.\n\n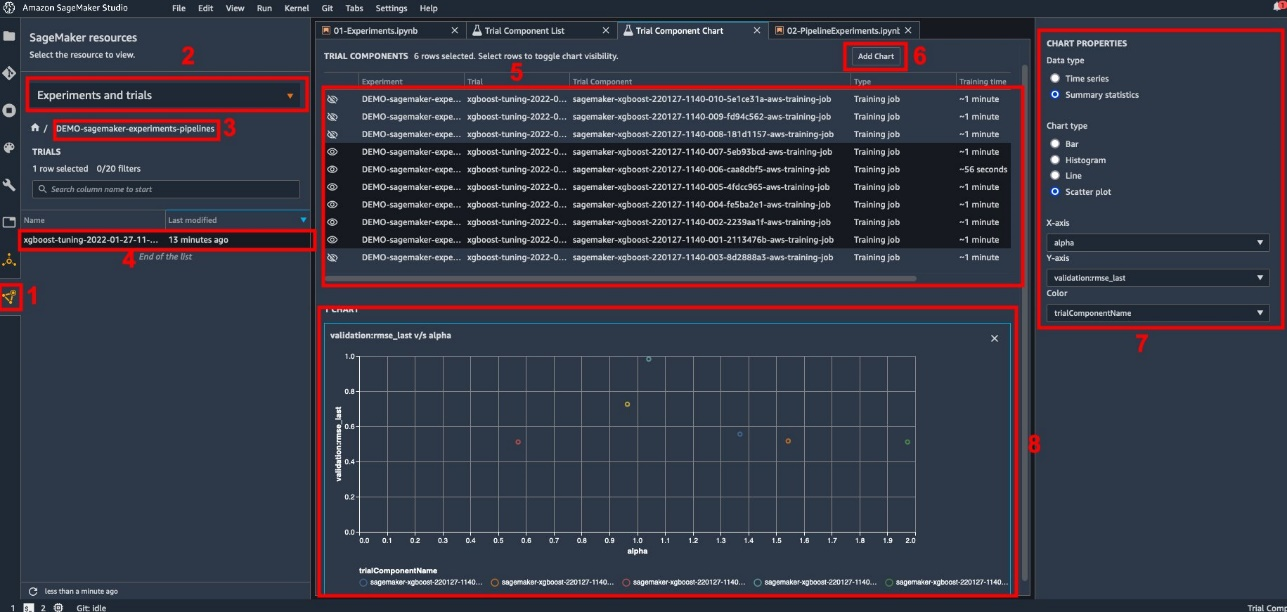\n\n\n#### **Analytics with SageMaker Experiments**\n\nWhen the pipeline run is complete, we can quickly visualize how different variations of the model compare in terms of the metrics collected during training. Earlier, we exported all trial metrics to a [Pandas](https://pandas.pydata.org/) ```DataFrame``` using ```ExperimentAnalytics```. We can reproduce the plot obtained in Studio by using the Matplotlib library.\n\n```\nanalytic_table.plot.scatter(\"lambda\", \"validation:rmse - Last\", grid=True)\n\n```\n### **Conclusion**\n\nThe native integration between SageMaker Pipelines and SageMaker Experiments allows data scientists to automatically organize, track, and visualize experiments during model development activities. You can create experiments to organize all your model development work, such as the following:\n \n- A business use case you’re addressing, such as creating an experiment to predict customer churn\n- An experiment owned by the data science team regarding marketing analytics, for example\n- A specific data science and ML project\n\nIn this post, we dove into Pipelines to show how you can use it in tandem with Experiments to organize a fully automated end-to-end workflow.\n\nAs a next step, you can use these three SageMaker features – Studio, Experiments and Pipelines – for your next ML project.\n\n#### **Suggested readings**\n\n- [Amazon SageMaker now supports cross-account lineage tracking and multi-hop lineage querying](https://aws.amazon.com/about-aws/whats-new/2021/12/amazon-sagemaker-cross-account-lineage-tracking-query/)\n- [Announcing Amazon SageMaker Inference Recommender](https://aws.amazon.com/blogs/aws/announcing-amazon-sagemaker-inference-recommender/)\n- [Introducing the Well-Architected Framework for Machine Learning](https://aws.amazon.com/blogs/architecture/introducing-the-well-architected-framework-for-machine-learning/)\n- [Machine Learning Lens: AWS Well-Architected Framework](https://docs.aws.amazon.com/wellarchitected/latest/machine-learning-lens/machine-learning-lens.html)\n- [Roundup of re:Invent 2021 Amazon SageMaker announcements](https://aws.amazon.com/blogs/machine-learning/roundup-of-reinvent-2021-amazon-sagemaker-announcements/?nc1=b_nrp)\n\n##### **About the authors**\n\n\n\n**Paolo Di Francesco** is a solutions architect at AWS. He has experience in the telecommunications and software engineering. He is passionate about machine learning and is currently focusing on using his experience to help customers reach their goals on AWS, in particular in discussions around MLOps. Outside of work, he enjoys playing football and reading.\n\n\n\n**Mario Bourgoin** is a Senior Partner Solutions Architect for AWS, an AI/ML specialist, and the global tech lead for MLOps. He works with enterprise customers and partners deploying AI solutions in the cloud. He has more than 30 years of experience doing machine learning and AI at startups and in enterprises, starting with creating one of the first commercial machine learning systems for big data. Mario spends his free time playing with his three Belgian Tervurens, cooking dinner for his family, and learning about mathematics and cosmology.\n\n\n\n**Ganapathi Krishnamoorthi** is a Senior ML Solutions Architect at AWS. Ganapathi provides prescriptive guidance to startup and enterprise customers helping them to design and deploy cloud applications at scale. He is specialized in machine learning and is focused on helping customers leverage AI/ML for their business outcomes. When not at work, he enjoys exploring outdoors and listening to music.\n\n\n\n**Valerie Sounthakith** is a Solutions Architect for AWS, working in the Gaming Industry and with Partners deploying AI solutions. She is aiming to build her career around Computer Vision. During her free time, Valerie spends it to travel, discover new food spots and change her house interiors.","render":"<p>The process of building a machine learning (ML) model is iterative until you find the candidate model that is performing well and is ready to be deployed. As data scientists iterate through that process, they need a reliable method to easily track experiments to understand how each model version was built and how it performed.</p>\n<p><a href=\"https://aws.amazon.com/sagemaker/\" target=\"_blank\">Amazon SageMaker</a> allows teams to take advantage of a broad range of features to quickly prepare, build, train, deploy, and monitor ML models. <a href=\"https://aws.amazon.com/sagemaker/pipelines/\" target=\"_blank\">Amazon SageMaker Pipelines</a> provides a repeatable process for iterating through model build activities, and is integrated with <a href=\"https://docs.aws.amazon.com/sagemaker/latest/dg/experiments.html\" target=\"_blank\">Amazon SageMaker Experiments</a>. By default, every SageMaker pipeline is associated with an experiment, and every run of that pipeline is tracked as a trial in that experiment. Then your iterations are automatically tracked without any additional steps.</p>\n<p>In this post, we take a closer look at the motivation behind having an automated process to track experiments with Experiments and the native capabilities built into Pipelines.</p>\n<h3><a id=\"Why_is_it_important_to_keep_your_experiments_organized_6\"></a><strong>Why is it important to keep your experiments organized?</strong></h3>\n<p>Let’s take a step back for a moment and try to understand why it’s important to have experiments organized for machine learning. When data scientists approach a new ML problem, they have to answer many different questions, from data availability to how they will measure model performance.</p>\n<p>At the start, the process is full of uncertainty and is highly iterative. As a result, this experimentation phase can produce multiple models, each created from their own inputs (datasets, training scripts, and hyperparameters) and producing their own outputs (model artifacts and evaluation metrics). The challenge then is to keep track of all these inputs and outputs of each iteration.</p>\n<p>Data scientists typically train many different model versions until they find the combination of data transformation, algorithm, and hyperparameters that results in the best performing version of a model. Each of these unique combinations is a single experiment. With a traceable record of the inputs, algorithms, and hyperparameters that were used by that trial, the data science team can find it easy to reproduce their steps.</p>\n<p>Having an automated process in place to track experiments improves the ability to reproduce as well as deploy specific model versions that are performing well. The Pipelines native integration with Experiments makes it easy to automatically track and manage experiments across pipeline runs.</p>\n<h3><a id=\"Benefits_of_SageMaker_Experiments_17\"></a><strong>Benefits of SageMaker Experiments</strong></h3>\n<p>SageMaker Experiments allows data scientists organize, track, compare, and evaluate their training iterations.</p>\n<p>Let’s start first with an overview of what you can do with Experiments:</p>\n<ul>\n<li><strong>Organize experiments</strong> – Experiments structures experimentation with a top-level entity called an experiment that contains a set of trials. Each trial contains a set of steps called trial components. Each trial component is a combination of datasets, algorithms, and parameters. You can picture experiments as the top-level folder for organizing your hypotheses, your trials as the subfolders for each group test run, and your trial components as your files for each instance of a test run.</li>\n<li><strong>Track experiments</strong> – Experiments allows data scientists to track experiments. It offers the possibility to automatically assign SageMaker jobs to a trial via simple configurations and via the tracking SDKs.</li>\n<li><strong>Compare and evaluate experiments</strong> – The integration of Experiments with <a href=\"https://docs.aws.amazon.com/sagemaker/latest/dg/studio.html\" target=\"_blank\">Amazon SageMaker Studio</a> makes it easy to produce data visualizations and compare different trials. You can also access the trial data via the Python SDK to generate your own visualization using your preferred plotting libraries.</li>\n</ul>\n<p>To learn more about Experiments APIs and SDKs, we recommend the following documentation: <a href=\"https://docs.aws.amazon.com/sagemaker/latest/APIReference/API_CreateExperiment.html\" target=\"_blank\">CreateExperiment</a> and <a href=\"https://sagemaker-experiments.readthedocs.io/en/latest/\" target=\"_blank\">Amazon SageMaker Experiments Python SDK</a>.</p>\n<p>If you want to dive deeper, we recommend looking into the <a href=\"https://github.com/aws/amazon-sagemaker-examples/tree/main/sagemaker-experiments\" target=\"_blank\">amazon-sagemaker-examples/sagemaker-experiments GitHub repository</a> for further examples.</p>\n<h3><a id=\"Integration_between_Pipelines_and_Experiments_31\"></a><strong>Integration between Pipelines and Experiments</strong></h3>\n<p>The model building pipelines that are part of Pipelines are purpose-built for ML and allow you to orchestrate your model build tasks using a pipeline tool that includes native integrations with other SageMaker features as well as the flexibility to extend your pipeline with steps run outside SageMaker. Each step defines an action that the pipeline takes. The dependencies between steps are defined by a direct acyclic graph (DAG) built using the Pipelines Python SDK. You can build a SageMaker pipeline programmatically via the same SDK. After a pipeline is deployed, you can optionally visualize its workflow within Studio.</p>\n<p>Pipelines automatically integrate with Experiments by automatically creating an experiment and trial for every run. Pipelines automatically create an experiment and a trial for every run of the pipeline before running the steps unless one or both of these inputs are specified. While running the pipeline’s SageMaker job, the pipeline associates the trial with the experiment, and associates to the trial every trial component that is created by the job. Specifying your own experiment or trial programmatically allows you to fine-tune how to organize your experiments.</p>\n<p>The workflow we present in this example consists of a series of steps: a preprocessing step to split our input dataset into train, test, and validation datasets; a tuning step to tune our hyperparameters and kick off training jobs to train a model using the <a href=\"https://docs.aws.amazon.com/sagemaker/latest/dg/xgboost.html\" target=\"_blank\">XGBoost built-in algorithm</a>; and finally a model step to create a SageMaker model from the best trained model artifact. Pipelines also offers several natively supported <a href=\"https://docs.aws.amazon.com/sagemaker/latest/dg/build-and-manage-steps.html\" target=\"_blank\">step types</a> outside of what is discussed in this post. We also illustrate how you can track your pipeline workflow and generate metrics and comparison charts. Furthermore, we show how to associate the new trial generated to an existing experiment that might have been created before the pipeline was defined.</p>\n<h3><a id=\"SageMaker_Pipelines_code_39\"></a><strong>SageMaker Pipelines code</strong></h3>\n<p>You can review and download the notebook from the <a href=\"https://github.com/aws-samples/sagemaker-experiments-and-pipelines/blob/main/02-PipelineExperiments.ipynb\" target=\"_blank\">GitHub repository</a> associated with this post. We look at the Pipelines-specific code to understand it better.</p>\n<p>Pipelines enables you to pass parameters at run time. Here we define the processing and training instance types and counts at run time with preset defaults:</p>\n<pre><code class=\"lang-\">base_job_prefix = "pipeline-experiment-sample"\nmodel_package_group_name = "pipeline-experiment-model-package"\n\nprocessing_instance_count = ParameterInteger(\n name="ProcessingInstanceCount", default_value=1\n)\n\ntraining_instance_count = ParameterInteger(\n name="TrainingInstanceCount", default_value=1\n)\n\nprocessing_instance_type = ParameterString(\n name="ProcessingInstanceType", default_value="ml.m5.xlarge"\n)\ntraining_instance_type = ParameterString(\n name="TrainingInstanceType", default_value="ml.m5.xlarge"\n)\n</code></pre>\n<p>Next, we set up a processing script that downloads and splits the input dataset into train, test, and validation parts. We use <code>SKLearnProcessor</code> for running this preprocessing step. To do so, we define a processor object with the instance type and count needed to run the processing job.</p>\n<p>Pipelines allows us to achieve data versioning in a programmatic way by using execution-specific variables like <code>ExecutionVariables.PIPELINE_EXECUTION_ID</code>, which is the unique ID of a pipeline run. We can, for example, create a unique key for storing the output datasets in <a href=\"http://aws.amazon.com/s3\" target=\"_blank\">Amazon Simple Storage Service </a>(Amazon S3) that ties them to a specific pipeline run. For the full list of variables, refer to <a href=\"https://sagemaker.readthedocs.io/en/stable/workflows/pipelines/sagemaker.workflow.pipelines.html#execution-variables\" target=\"_blank\">Execution Variables</a>.</p>\n<pre><code class=\"lang-\">framework_version = "0.23-1"\n\nsklearn_processor = SKLearnProcessor(\n framework_version=framework_version,\n instance_type=processing_instance_type,\n instance_count=processing_instance_count,\n base_job_name="sklearn-ca-housing",\n role=role,\n)\n\nprocess_step = ProcessingStep(\n name="ca-housing-preprocessing",\n processor=sklearn_processor,\n outputs=[\n ProcessingOutput(\n output_name="train",\n source="/opt/ml/processing/train",\n destination=Join(\n on="/",\n values=[\n "s3://{}".format(bucket),\n prefix,\n ExecutionVariables.PIPELINE_EXECUTION_ID,\n "train",\n ],\n ),\n ),\n ProcessingOutput(\n output_name="validation",\n source="/opt/ml/processing/validation",\n destination=Join(\n on="/",\n values=[\n "s3://{}".format(bucket),\n prefix,\n ExecutionVariables.PIPELINE_EXECUTION_ID,\n "validation",\n ],\n )\n ),\n ProcessingOutput(\n output_name="test",\n source="/opt/ml/processing/test",\n destination=Join(\n on="/",\n values=[\n "s3://{}".format(bucket),\n prefix,\n ExecutionVariables.PIPELINE_EXECUTION_ID,\n "test",\n ],\n )\n ),\n ],\n code="california-housing-preprocessing.py",\n)\n\n\n</code></pre>\n<p>Then we move on to create an estimator object to train an XGBoost model. We set some static hyperparameters that are commonly used with XGBoost:</p>\n<pre><code class=\"lang-\">model_path = f"s3://{default_bucket}/{base_job_prefix}/ca-housing-experiment-pipeline"\n\nimage_uri = sagemaker.image_uris.retrieve(\n framework="xgboost",\n region=region,\n version="1.2-2",\n py_version="py3",\n instance_type=training_instance_type,\n)\n\nxgb_train = Estimator(\n image_uri=image_uri,\n instance_type=training_instance_type,\n instance_count=training_instance_count,\n output_path=model_path,\n base_job_name=f"{base_job_prefix}/ca-housing-train",\n sagemaker_session=sagemaker_session,\n role=role,\n)\n\nxgb_train.set_hyperparameters(\n eval_metric="rmse",\n objective="reg:squarederror", # Define the object metric for the training job\n num_round=50,\n max_depth=5,\n eta=0.2,\n gamma=4,\n min_child_weight=6,\n subsample=0.7\n)\n\n</code></pre>\n<p>We do hyperparameter tuning of the models we create by using a <code>ContinuousParameter</code> range for <code>lambda</code>. Choosing one metric to be the objective metric tells the tuner (the instance that runs the hyperparameters tuning jobs) that you will evaluate the training job based on this specific metric. The tuner returns the best combination based on the best value for this objective metric, meaning the best combination that minimizes the best root mean square error (RMSE).</p>\n<pre><code class=\"lang-\">objective_metric_name = "validation:rmse"\n\nhyperparameter_ranges = {\n "lambda": ContinuousParameter(0.01, 10, scaling_type="Logarithmic")\n}\n\ntuner = HyperparameterTuner(estimator,\n objective_metric_name,\n hyperparameter_ranges,\n objective_type=objective_type,\n strategy="Bayesian",\n max_jobs=10,\n max_parallel_jobs=3)\n\ntune_step = TuningStep(\n name="HPTuning",\n tuner=tuner_log,\n inputs={\n "train": TrainingInput(\n s3_data=process_step.properties.ProcessingOutputConfig.Outputs[\n "train"\n ].S3Output.S3Uri,\n content_type="text/csv",\n ),\n "validation": TrainingInput(\n s3_data=process_step.properties.ProcessingOutputConfig.Outputs[\n "validation"\n ].S3Output.S3Uri,\n content_type="text/csv",\n ),\n } \n)\n</code></pre>\n<p>The tuning step runs multiple trials with the goal of determining the best model among the parameter ranges tested. With the<code> method get_top_model_s3_uri</code>, we rank the top 50 performing versions of the model artifact S3 URI and only extract the best performing version (we specify <code>k=0</code> for the best) to create a SageMaker model.</p>\n<pre><code class=\"lang-\">model_bucket_key = f"{default_bucket}/{base_job_prefix}/ca-housing-experiment-pipeline"\nmodel_candidate = Model(\n image_uri=image_uri,\n model_data=tune_step.get_top_model_s3_uri(top_k=0, s3_bucket=model_bucket_key),\n sagemaker_session=sagemaker_session,\n role=role,\n predictor_cls=XGBoostPredictor,\n)\n\ncreate_model_step = CreateModelStep(\n name="CreateTopModel",\n model=model_candidate,\n inputs=sagemaker.inputs.CreateModelInput(instance_type="ml.m4.large"),\n)\n\n</code></pre>\n<p>When the pipeline runs, it creates trial components for each hyperparameter tuning job and each SageMaker job created by the pipeline steps.</p>\n<p>You can further configure the integration of pipelines with Experiments by creating a <code>PipelineExperimentConfig</code> object and pass it to the pipeline object. The two parameters define the name of the experiment that will be created, and the trial that will refer to the whole run of the pipeline.</p>\n<p>If you want to associate a pipeline run to an existing experiment, you can pass its name, and Pipelines will associate the new trial to it. You can prevent the creation of an experiment and trial for a pipeline run by setting <code>pipeline_experiment_config </code>to <code>None</code>.</p>\n<pre><code class=\"lang-\">#Pipeline experiment config\nca_housing_experiment_config = PipelineExperimentConfig(\n experiment_name,\n Join(\n on="-",\n values=[\n "pipeline-execution",\n ExecutionVariables.PIPELINE_EXECUTION_ID\n ],\n )\n)\n</code></pre>\n<p>We pass on the instance types and counts as parameters, and chain the preceding steps in order as follows. The pipeline workflow is implicitly defined by the outputs of a step being the inputs of another step.</p>\n<pre><code class=\"lang-\">pipeline_name = f"CAHousingExperimentsPipeline"\n\npipeline = Pipeline(\n name=pipeline_name,\n pipeline_experiment_config=ca_housing_experiment_config,\n parameters=[\n processing_instance_count,\n processing_instance_type,\n training_instance_count,\n training_instance_type\n ],\n steps=[process_step,tune_step,create_model_step],\n)\n</code></pre>\n<p>The full-fledged pipeline is now created and ready to go. We add an execution role to the pipeline and start it. From here, we can go to the SageMaker Studio Pipelines console and visually track every step. You can also access the linked logs from the console to debug a pipeline.</p>\n<pre><code class=\"lang-\">pipeline.upsert(role_arn=sagemaker.get_execution_role())\nexecution = pipeline.start()\n</code></pre>\n<p><img src=\"https://dev-media.amazoncloud.cn/319dda8226f24da0a06dfcce64178e49_image.png\" alt=\"image.png\" /></p>\n<p>The preceding screenshot shows in green a successfully run pipeline. We obtain the metrics of one trial from a run of the pipeline with the following code:</p>\n<pre><code class=\"lang-\"># SM Pipeline injects the Execution ID into trial component names\nexecution_id = execution.describe()['PipelineExecutionArn'].split('/')[-1]\nsource_arn_filter = Filter(\n name="TrialComponentName", operator=Operator.CONTAINS, value=execution_id\n)\n\nsource_type_filter = Filter(\n name="Source.SourceType", operator=Operator.EQUALS, value="SageMakerTrainingJob"\n)\n\nsearch_expression = SearchExpression(\n filters=[source_arn_filter, source_type_filter]\n)\n\ntrial_component_analytics = ExperimentAnalytics(\n sagemaker_session=sagemaker_session,\n experiment_name=experiment_name,\n search_expression=search_expression.to_boto()\n)\n\nanalytic_table = trial_component_analytics.dataframe()\nanalytic_table.head()\n</code></pre>\n<h3><a id=\"Compare_the_metrics_for_each_trial_component_297\"></a><strong>Compare the metrics for each trial component</strong></h3>\n<p>You can plot the results of hyperparameter tuning in Studio or via other Python plotting libraries. We show both ways of doing this.</p>\n<h5><a id=\"Explore_the_training_and_evaluation_metrics_in_Studio_301\"></a><strong>Explore the training and evaluation metrics in Studio</strong></h5>\n<p>Studio provides an interactive user interface where you can generate interactive plots. The steps are as follows:</p>\n<ol>\n<li>Choose <strong>Experiments and Trials</strong> from the <strong>SageMaker resources</strong> icon on the left sidebar.</li>\n<li>Choose your experiment to open it.</li>\n<li>Choose (right-click) the trial of interest.</li>\n<li>Choose <strong>Open in trial component list</strong>.</li>\n<li>Press <strong>Shift</strong> to select the trial components representing the training jobs.</li>\n<li>Choose <strong>Add chart</strong>.</li>\n<li>Choose <strong>New chart</strong> and customize it to plot the collected metrics that you want to analyze. For our use case, choose the following:<br />\na. For <strong>Data type</strong>¸ select <strong>Summary Statistics</strong>.<br />\nb. For <strong>Chart type</strong>¸ select <strong>Scatter Plot</strong>.<br />\nc. For <strong>X-axis</strong>, choose <code>lambda</code>.<br />\nd. For <strong>Y-axis</strong>, choose <code>validation:rmse_last</code>.</li>\n</ol>\n<p>The new chart appears at the bottom of the window, labeled as ‘8’.</p>\n<p>You can include more or fewer training jobs by pressing Shift and choosing the eye icon for a more interactive experience.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/7114a0146bf64a0ca74f6805b7b1684f_image.png\" alt=\"image.png\" /></p>\n<h4><a id=\"Analytics_with_SageMaker_Experiments_325\"></a><strong>Analytics with SageMaker Experiments</strong></h4>\n<p>When the pipeline run is complete, we can quickly visualize how different variations of the model compare in terms of the metrics collected during training. Earlier, we exported all trial metrics to a <a href=\"https://pandas.pydata.org/\" target=\"_blank\">Pandas</a> <code>DataFrame</code> using <code>ExperimentAnalytics</code>. We can reproduce the plot obtained in Studio by using the Matplotlib library.</p>\n<pre><code class=\"lang-\">analytic_table.plot.scatter("lambda", "validation:rmse - Last", grid=True)\n\n</code></pre>\n<h3><a id=\"Conclusion_333\"></a><strong>Conclusion</strong></h3>\n<p>The native integration between SageMaker Pipelines and SageMaker Experiments allows data scientists to automatically organize, track, and visualize experiments during model development activities. You can create experiments to organize all your model development work, such as the following:</p>\n<ul>\n<li>A business use case you’re addressing, such as creating an experiment to predict customer churn</li>\n<li>An experiment owned by the data science team regarding marketing analytics, for example</li>\n<li>A specific data science and ML project</li>\n</ul>\n<p>In this post, we dove into Pipelines to show how you can use it in tandem with Experiments to organize a fully automated end-to-end workflow.</p>\n<p>As a next step, you can use these three SageMaker features – Studio, Experiments and Pipelines – for your next ML project.</p>\n<h4><a id=\"Suggested_readings_345\"></a><strong>Suggested readings</strong></h4>\n<ul>\n<li><a href=\"https://aws.amazon.com/about-aws/whats-new/2021/12/amazon-sagemaker-cross-account-lineage-tracking-query/\" target=\"_blank\">Amazon SageMaker now supports cross-account lineage tracking and multi-hop lineage querying</a></li>\n<li><a href=\"https://aws.amazon.com/blogs/aws/announcing-amazon-sagemaker-inference-recommender/\" target=\"_blank\">Announcing Amazon SageMaker Inference Recommender</a></li>\n<li><a href=\"https://aws.amazon.com/blogs/architecture/introducing-the-well-architected-framework-for-machine-learning/\" target=\"_blank\">Introducing the Well-Architected Framework for Machine Learning</a></li>\n<li><a href=\"https://docs.aws.amazon.com/wellarchitected/latest/machine-learning-lens/machine-learning-lens.html\" target=\"_blank\">Machine Learning Lens: AWS Well-Architected Framework</a></li>\n<li><a href=\"https://aws.amazon.com/blogs/machine-learning/roundup-of-reinvent-2021-amazon-sagemaker-announcements/?nc1=b_nrp\" target=\"_blank\">Roundup of re:Invent 2021 Amazon SageMaker announcements</a></li>\n</ul>\n<h5><a id=\"About_the_authors_353\"></a><strong>About the authors</strong></h5>\n<p><img src=\"https://dev-media.amazoncloud.cn/8a82ec52fc8b40b1a99b609f9752e4a1_image.png\" alt=\"image.png\" /></p>\n<p><strong>Paolo Di Francesco</strong> is a solutions architect at AWS. He has experience in the telecommunications and software engineering. He is passionate about machine learning and is currently focusing on using his experience to help customers reach their goals on AWS, in particular in discussions around MLOps. Outside of work, he enjoys playing football and reading.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/33e05f44d39c4995885ef6a4fde4e1a6_image.png\" alt=\"image.png\" /></p>\n<p><strong>Mario Bourgoin</strong> is a Senior Partner Solutions Architect for AWS, an AI/ML specialist, and the global tech lead for MLOps. He works with enterprise customers and partners deploying AI solutions in the cloud. He has more than 30 years of experience doing machine learning and AI at startups and in enterprises, starting with creating one of the first commercial machine learning systems for big data. Mario spends his free time playing with his three Belgian Tervurens, cooking dinner for his family, and learning about mathematics and cosmology.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/2d7ff21302e6474781cc5db93dee45f3_image.png\" alt=\"image.png\" /></p>\n<p><strong>Ganapathi Krishnamoorthi</strong> is a Senior ML Solutions Architect at AWS. Ganapathi provides prescriptive guidance to startup and enterprise customers helping them to design and deploy cloud applications at scale. He is specialized in machine learning and is focused on helping customers leverage AI/ML for their business outcomes. When not at work, he enjoys exploring outdoors and listening to music.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/4f0bd1567c9d476d94a4f29935fd2cc7_image.png\" alt=\"image.png\" /></p>\n<p><strong>Valerie Sounthakith</strong> is a Solutions Architect for AWS, working in the Gaming Industry and with Partners deploying AI solutions. She is aiming to build her career around Computer Vision. During her free time, Valerie spends it to travel, discover new food spots and change her house interiors.</p>\n"}
Organize your machine learning journey with Amazon SageMaker Experiments and Amazon SageMaker Pipelines
海外精选

海外精选的内容汇集了全球优质的亚马逊云科技相关技术内容。同时,内容中提到的“AWS”
是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。

 0
0 0
0亚马逊云科技解决方案 基于行业客户应用场景及技术领域的解决方案
联系亚马逊云科技专家
亚马逊云科技解决方案
基于行业客户应用场景及技术领域的解决方案
联系专家

0
目录

 分享
分享 点赞
点赞 收藏
收藏 目录
目录立即注册,开启您的免费套餐
立即关注

亚马逊云开发者
公众号

User Group
公众号

亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
关于我们 
更多资源
开发者工具
更多支持
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
