{"value":"Many customers prefer to use Docker images with [AWS Batch ](https://aws.amazon.com/cn/batch/?trk=cndc-detail)and AWS Cloudformation for cost-effective and faster processing of complex jobs. To run batch workloads in the cloud, customers have to consider various orchestration needs, such as queueing workloads, submitting to a compute resource, prioritizing jobs, handling dependencies and retries, scaling compute, and tracking utilization and resource management. While [AWS Batch ](https://aws.amazon.com/cn/batch/?trk=cndc-detail)simplifies all the queuing, scheduling, and lifecycle management for customers, and even provisions and manages compute in the customer account, customers continue to look for even more time-efficient and simpler workflows to get their application jobs up and running in minutes.\n\nIn a previous version of this [blog](https://aws.amazon.com/blogs/compute/orchestrating-an-application-process-with-aws-batch-using-aws-cloudformation/), we showed how to spin up the [AWS Batch ](https://aws.amazon.com/cn/batch/?trk=cndc-detail)infrastructure with Managed EC2 compute environment. With fully serverless batch computing with [AWS Batch ](https://aws.amazon.com/cn/batch/?trk=cndc-detail)Support for [AWS Fargate](https://aws.amazon.com/cn/fargate/?trk=cndc-detail) introduced last year, [AWS Fargate](https://aws.amazon.com/cn/fargate/?trk=cndc-detail) can be used with [AWS Batch ](https://aws.amazon.com/cn/batch/?trk=cndc-detail)to run containers without having to manage servers or clusters of [Amazon EC2 ](https://aws.amazon.com/cn/ec2/?trk=cndc-detail)instances. This post provides a file processing implementation using Docker images and [Amazon S3](https://aws.amazon.com/cn/s3/?trk=cndc-detail), [AWS Lambda](https://aws.amazon.com/cn/lambda/?trk=cndc-detail), [Amazon DynamoDB](https://aws.amazon.com/dynamodb/), and [AWS Batch](https://aws.amazon.com/batch/). In the example used, the user uploads a CSV file into an [Amazon S3](https://aws.amazon.com/cn/s3/?trk=cndc-detail) bucket, which is processed by [AWS Batch ](https://aws.amazon.com/cn/batch/?trk=cndc-detail)as a job. These jobs can be packaged as Docker containers and executed on [Amazon EC2](https://aws.amazon.com/ec2/) and [Amazon ECS](https://aws.amazon.com/ecs/).\n\nThe following steps provide an overview of this implementation:\n\n1. [AWS CloudFormation](https://aws.amazon.com/cn/cloudformation/?trk=cndc-detail) template launches the S3 bucket that stores the CSV files along with other necessary infrastructure.\n2. The [Amazon S3](https://aws.amazon.com/cn/s3/?trk=cndc-detail) file event notification executes an [AWS Lambda](https://aws.amazon.com/cn/lambda/?trk=cndc-detail) function that starts an [AWS Batch ](https://aws.amazon.com/cn/batch/?trk=cndc-detail)job.\n3. [AWS Batch ](https://aws.amazon.com/cn/batch/?trk=cndc-detail)executes the job as a Docker container.\n4. A Python-based program reads the contents in the [Amazon S3](https://aws.amazon.com/cn/s3/?trk=cndc-detail) bucket, parses each row, and updates an [Amazon DynamoDB](https://aws.amazon.com/cn/dynamodb/?trk=cndc-detail) table.\n5. DynamoDB stores each processed row from the CSV.\n\n### **Prerequisites**\n\n- Make sure to have Docker installed and running on your machine. Use Docker Desktop and Desktop Enterprise to install and configure Docker.\n- Set up your AWS CLI. For steps, see [Getting Started](https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-install.html) (AWS CLI).\n\n### **Walkthrough**\n\nBelow steps explains how to download, build the code and deploying the infrastructure.\n\n1. Deploying the [AWS CloudFormation](https://aws.amazon.com/cn/cloudformation/?trk=cndc-detail) template – Run the CloudFormation template (command provided) to create the necessary infrastructure.\n2. Docker Build and Push – Set up the Docker image for the job:\n3. Build a Docker image.\n4. Tag the build and push the image to the repository.\n5. Testing – Drop the CSV into the S3 bucket (copy paste the contents and create them as a ```[sample file csv]```). CLI provided to upload the S3 to the created bucket\n6. Validation – Confirm that the job runs and performs the operation based on the pushed container image. The job parses the CSV file and adds each row into the DynamoDB table.\n\n\n### **Points to consider**\n\n- The provided [AWS CloudFormation](https://aws.amazon.com/cn/cloudformation/?trk=cndc-detail) template has all the services (refer to upcoming diagram) needed for this walkthrough in one single template. In an ideal production scenario, you might split them into different templates for easier maintenance.\n- To handle a higher volume of CSV file contents, you can do multithreaded or multiprocessing programming to complement the [AWS Batch ](https://aws.amazon.com/cn/batch/?trk=cndc-detail)performance scale.\n- Solution provided here lets you build, tag, and push the docker image to the repository (created as part of the stack). We’ve provided both a consolidated script files ```— exec.sh``` and ```cleanup.sh```, as well as include individual commands, should you choose to manually run them to learn the workflow better. You can use the scripts included in this post with your existing CI/CD tooling, such as [AWS CodeBuild](https://aws.amazon.com/cn/codebuild/?trk=cndc-detail), or any other equivalent to build from repository and push to AWS ECR.\n- The example included in this blog post uses a simple [AWS Lambda](https://aws.amazon.com/cn/lambda/?trk=cndc-detail) function to run jobs in AWS Batch, and the Lambda function code is in Python. You can use any of the other programming languages supported by [AWS Lambda](https://aws.amazon.com/cn/lambda/?trk=cndc-detail), for your function code. As an alternative to Lambda function code, you can also use AWS StepFunctions a low-code, visual workflow alternative to initiate the [AWS Batch ](https://aws.amazon.com/cn/batch/?trk=cndc-detail)job.\n\n### **1. Deploying the [AWS CloudFormation](https://aws.amazon.com/cn/cloudformation/?trk=cndc-detail) template**\n\nWhen deployed, the [AWS CloudFormation](https://aws.amazon.com/cn/cloudformation/?trk=cndc-detail) template creates the following infrastructure.\n\n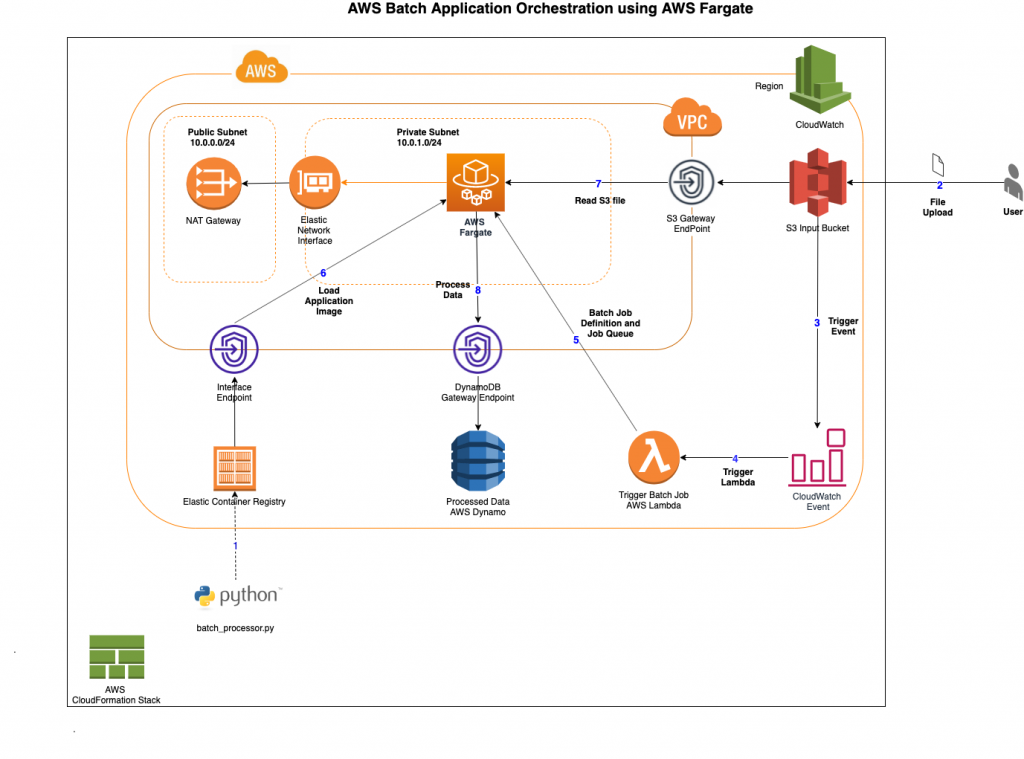\n\nDownload the source from the [GitHub location](https://github.com/aws-samples/aws-batch-processing-job-repo). Follow the steps below to use the downloaded code. The ```exec.sh``` script included in the repo will execute the CloudFormation template spinning up the infrastructure, a Python application (.py file) and a sample CSV file.\n\nNote: ```exec_ec2.sh``` is also provided for reference. This has the implementation done using Managed EC2 instances as mentioned in the previous blog.\n\n```\\n\$ git clone https://github.com/aws-samples/aws-batch-processing-job-repo\\n```\n\n```\\n\$ cd aws-batch-processing-job-repo\\n```\n\n```\\n\$ ./exec.sh\\n```\n\n\nAlternatively, you can also run individual commands manually as provided below to setup the infrastructure, push the docker image to ECR, and add sample files to S3 for testing.\n\n\n### **Step 1: Setup the infrastructure**\n\n```\\n\$ STACK_NAME=fargate-batch-job\\n```\n```\\n\$ aws cloudformation create-stack --stack-name \$STACK_NAME --parameters ParameterKey=StackName,ParameterValue=\$STACK_NAME --template-body file://template/template.yaml --capabilities CAPABILITY_NAMED_IAM\\n```\nAfter downloading the code, take a moment to review the “templates.yaml” in the “src” folder. The snippets below provide an overview of how the compute environment and a job definition can be specified easily using the managed serverless compute options that were introduced. “[templates_ec2.yaml](https://github.com/aws-samples/aws-batch-processing-job-repo/blob/master/template/template_ec2.yaml)” has the older version of implementation done for EC2 as Compute Environment.\n\n```\\nComputeEnvironment:\\n Type: AWS::Batch::ComputeEnvironment\\n Properties:\\n Type: MANAGED\\n State: ENABLED\\n ComputeResources:\\n Type: FARGATE\\n MaxvCpus: 40\\n Subnets:\\n - Ref: PrivateSubnet\\n SecurityGroupIds:\\n - Ref: SecurityGroup\\n ...\\n```\n\n```\\nBatchProcessingJobDefinition:\\n Type: AWS::Batch::JobDefinition\\n Properties:\\n ....\\n ContainerProperties:\\n Image: \\n ...\\n FargatePlatformConfiguration:\\n PlatformVersion: LATEST\\n ResourceRequirements:\\n - Value: 0.25\\n Type: VCPU\\n - Value: 512\\n Type: MEMORY\\n JobRoleArn: !GetAtt 'BatchTaskExecutionRole.Arn'\\n ExecutionRoleArn: !GetAtt 'BatchTaskExecutionRole.Arn'\\n ...\\n ...\\n PlatformCapabilities:\\n - FARGATE\\n```\n\nWhen the preceding CloudFormation stack is created successfully, take a moment to identify the major components. The CloudFormation template spins up the following resources, which you can also view in the AWS Management Console.\n\n1. CloudFormation Stack Name – fargate-batch-job\n2. S3 Bucket Name – fargate-batch-job<YourAccountNumber>\\n 1.After the sample CSV file is dropped into this bucket, the process should kick start.\\n1. JobDefinition – BatchJobDefinition\\n2. JobQueue – fargate-batch-job-queue\\n3. Lambda – fargate-batch-job-lambda\\n4. DynamoDB – fargate-batch-job\\n5. Amazon CloudWatch Log – This is created when the first execution is made.\\n 1./aws/batch/job\\n 2./aws/lambda/LambdaInvokeFunction\\n1. CodeCommit – fargate-batch-jobrepo\\n2. CodeBuild – fargate-batch-jobbuild\\n\\nOnce the above CloudFormation stack creation is complete in your personal account, we need to containerize the sample Python application and push it to ECR. We will use command line execution shell script to deploy the application and the infrastructure. Note that AWS CodeCommit and CodeBuild infrastructure are also created as part of the above template. The template on AWS CodeBuild can also run similar commands to deploy the necessary infrastructure.\\n\\n### **2. Docker Build and Push**\\n\\nA simple Python application code is provided (in “src” folder). This is Docker containerized and pushed to the AWS Elastic Container Registry that was created with the CloudFormation template.\\n\\n```\\n\$ STACK_NAME=fargate-batch-job \\n\$ REGION=\$(aws ec2 describe-availability-zones --output text --query 'AvailabilityZones[0].[RegionName]')\\n\\n\$ ACCOUNT_NUMBER=\$(aws sts get-caller-identity --query 'Account' --output text)\\n\\n\$ SOURCE_REPOSITORY=\$PWD \\n\$ docker build -t batch_processor .\\n\\n\$ docker tag batch_processor \$(aws sts get-caller-identity --query 'Account' --output text).dkr.ecr.\$REGION.amazonaws.com/\$STACK_NAME-repository \\n\$ aws ecr get-login-password --region \$REGION | docker login --username AWS --password-stdin \$(aws sts get-caller-identity --query 'Account' --output text).dkr.ecr.\$REGION.amazonaws.com \\n\$ docker push \$(aws sts get-caller-identity --query 'Account' --output text).dkr.ecr.\$REGION.amazonaws.com/\$STACK_NAME-repository \\n```\\n### **3. Testing**\\n\\nIn this step we will go over testing with a ```sample.csv```, either uploaded manually or via the AWS CLI to the AWS S3 bucket. Make sure to complete the previous step of pushing the built image of the Python code to ECR, before testing. You can verify your build and push by going to the AWS Console > ECR – “fargate-batch-job” repository\\n\\n1. You will see AWS S3 bucket – fargate-batch-job- is created as part of the stack.\\n2. you will need to drop the provided ```sample.csv``` into this S3 bucket. Once you add the file to S3, the Lambda function will be triggered to start AWS Batch. To run the command manually, execute the following —\\n\\nBash\\n\\n```\\n\$ aws s3 --region \$REGION cp \$SOURCE_REPOSITORY/sample/sample.csv s3://\$STACK_NAME-\$ACCOUNT_NUMBER\\n```\\n3. In AWS Console > Batch, notice that the Job runs and performs the operation based on the pushed container image. The job parses the CSV file and adds each row into DynamoDB.\\n\\n### **4. Validation**\\n\\n1. In AWS Console > DynamoDB, look for “fargate-batch-job” table. Note sample products provided as part of the CSV is added by the batch\\n\\n### **Code cleanup**\\n\\nUse the ```cleanup.sh``` script to remove the Amazon S3 files, Amazon ECR repository images and the AWS CloudFormation stack that was spun up as part of previous steps.\\n\\n```\\n\\n\$ ./cleanup.sh\\n```\\nAlternatively, you can follow the steps below to manually clean up the built environment\\n\\n1. AWS Console > S3 bucket – fargate-batch-job- – Delete the contents of the file\\n2. AWS Console > ECR – fargate-batch-job-repository – delete the image(s) that are pushed to the repository\\n3. Run the below command to delete the stack.\\n\\n```\\n\$ aws cloudformation delete-stack --stack-name fargate-batch-job\\n\\n```\\n\\n1. To perform all the above steps in CLI\\n\\n```\\n\$ SOURCE_REPOSITORY=\$PWD \\n\$ STACK_NAME=fargate-batch-job \\n\$ REGION=\$(aws ec2 describe-availability-zones --output text —query 'AvailabilityZones[0].[RegionName]')\\n\\n\$ ACCOUNT_NUMBER=\$(aws sts get-caller-identity --query 'Account' —output text)\\n\\n\$ aws ecr batch-delete-image --repository-name \$STACK_NAME-repository --image-ids imageTag=latest \\n\$ aws ecr batch-delete-image --repository-name \$STACK_NAME-repository --image-ids imageTag=untagged \\n\$ aws s3 --region \$REGION rm s3://\$STACK_NAME-\$ACCOUNT_NUMBER —recursive \\n\$ aws cloudformation delete-stack --stack-name \$STACK_NAME\\n\\n```\\n### **References**\\n\\n1. [New – Fully Serverless Batch Computing with AWS Batch Support for AWS Fargate](https://aws.amazon.com/blogs/aws/new-fully-serverless-batch-computing-with-aws-batch-support-for-aws-fargate/)\\n2. [AWS Batch on AWS Fargate](https://docs.aws.amazon.com/batch/latest/userguide/fargate.html)\\n3. [Manage AWS Batch with Step Functions](https://docs.aws.amazon.com/step-functions/latest/dg/connect-batch.html)\\n\\n\\n### **Conclusion**\\n\\nFollowing the solution in the post, you will be able to launch an application workflow using AWS Batch integrating with various AWS services. You also have access to the Python script, CloudFormation template, and the sample CSV file in the corresponding GitHub repo that takes care of all the preceding CLI arguments for you to build out the job definitions.\\n\\nAs stated in the post, with AWS Fargate, you no longer have to provision, configure, or scale clusters of virtual machines to run containers. This removes the need to choose server types, decide when to scale your clusters, or optimize cluster packing. With Fargate or Fargate Spot, you don’t need to worry about Amazon EC2 instances or Amazon Machine Images. Just set Fargate or Fargate Spot, your subnets, and the maximum total vCPU of the jobs running in the compute environment, and you have a ready-to-go Fargate computing environment. With Fargate Spot, you can take advantage of up to 70% discount for your fault-tolerant, time-flexible jobs.\\n\\nI encourage you to test this example and see for yourself how this overall orchestration works with AWS Batch. Then, it is just a matter of replacing your Python (or any other programming language framework) code, packaging it as a Docker container, and letting the AWS Batch handle the process efficiently.\\n\\nIf you decide to give it a try, have any doubt, or want to let me know what you think about the post, please leave a comment!\\n\\n#### **About the Author**\\n\\n\\n\\nSivasubramanian Ramani (Siva Ramani) is a Sr Cloud Application Architect at AWS. His expertise is in application optimization, serverless solutions with AWS.","render":"<p>Many customers prefer to use Docker images with AWS Batch and AWS Cloudformation for cost-effective and faster processing of complex jobs. To run batch workloads in the cloud, customers have to consider various orchestration needs, such as queueing workloads, submitting to a compute resource, prioritizing jobs, handling dependencies and retries, scaling compute, and tracking utilization and resource management. While AWS Batch simplifies all the queuing, scheduling, and lifecycle management for customers, and even provisions and manages compute in the customer account, customers continue to look for even more time-efficient and simpler workflows to get their application jobs up and running in minutes.</p>\n<p>In a previous version of this <a href=\\"https://aws.amazon.com/blogs/compute/orchestrating-an-application-process-with-aws-batch-using-aws-cloudformation/\\" target=\\"_blank\\">blog</a>, we showed how to spin up the [AWS Batch ](https://aws.amazon.com/cn/batch/?trk=cndc-detail)infrastructure with Managed EC2 compute environment. With fully serverless batch computing with [AWS Batch ](https://aws.amazon.com/cn/batch/?trk=cndc-detail)Support for [AWS Fargate](https://aws.amazon.com/cn/fargate/?trk=cndc-detail) introduced last year, [AWS Fargate](https://aws.amazon.com/cn/fargate/?trk=cndc-detail) can be used with [AWS Batch ](https://aws.amazon.com/cn/batch/?trk=cndc-detail)to run containers without having to manage servers or clusters of [Amazon EC2 ](https://aws.amazon.com/cn/ec2/?trk=cndc-detail)instances. This post provides a file processing implementation using Docker images and [Amazon S3](https://aws.amazon.com/cn/s3/?trk=cndc-detail), [AWS Lambda](https://aws.amazon.com/cn/lambda/?trk=cndc-detail), <a href=\\"https://aws.amazon.com/dynamodb/\\" target=\\"_blank\\">Amazon DynamoDB</a>, and <a href=\\"https://aws.amazon.com/batch/\\" target=\\"_blank\\">AWS Batch</a>. In the example used, the user uploads a CSV file into an [Amazon S3](https://aws.amazon.com/cn/s3/?trk=cndc-detail) bucket, which is processed by [AWS Batch ](https://aws.amazon.com/cn/batch/?trk=cndc-detail)as a job. These jobs can be packaged as Docker containers and executed on <a href=\\"https://aws.amazon.com/ec2/\\" target=\\"_blank\\">Amazon EC2</a> and <a href=\\"https://aws.amazon.com/ecs/\\" target=\\"_blank\\">Amazon ECS</a>.</p>\\n<p>The following steps provide an overview of this implementation:</p>\n<ol>\\n<li>AWS CloudFormation template launches the S3 bucket that stores the CSV files along with other necessary infrastructure.</li>\n<li>The Amazon S3 file event notification executes an AWS Lambda function that starts an AWS Batch job.</li>\n<li>AWS Batch executes the job as a Docker container.</li>\n<li>A Python-based program reads the contents in the Amazon S3 bucket, parses each row, and updates an Amazon DynamoDB table.</li>\n<li>DynamoDB stores each processed row from the CSV.</li>\n</ol>\\n<h3><a id=\\"Prerequisites_12\\"></a><strong>Prerequisites</strong></h3>\\n<ul>\\n<li>Make sure to have Docker installed and running on your machine. Use Docker Desktop and Desktop Enterprise to install and configure Docker.</li>\n<li>Set up your AWS CLI. For steps, see <a href=\\"https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-install.html\\" target=\\"_blank\\">Getting Started</a> (AWS CLI).</li>\\n</ul>\n<h3><a id=\\"Walkthrough_17\\"></a><strong>Walkthrough</strong></h3>\\n<p>Below steps explains how to download, build the code and deploying the infrastructure.</p>\n<ol>\\n<li>Deploying the AWS CloudFormation template – Run the CloudFormation template (command provided) to create the necessary infrastructure.</li>\n<li>Docker Build and Push – Set up the Docker image for the job:</li>\n<li>Build a Docker image.</li>\n<li>Tag the build and push the image to the repository.</li>\n<li>Testing – Drop the CSV into the S3 bucket (copy paste the contents and create them as a <code>[sample file csv]</code>). CLI provided to upload the S3 to the created bucket</li>\\n<li>Validation – Confirm that the job runs and performs the operation based on the pushed container image. The job parses the CSV file and adds each row into the DynamoDB table.</li>\n</ol>\\n<h3><a id=\\"Points_to_consider_29\\"></a><strong>Points to consider</strong></h3>\\n<ul>\\n<li>The provided AWS CloudFormation template has all the services (refer to upcoming diagram) needed for this walkthrough in one single template. In an ideal production scenario, you might split them into different templates for easier maintenance.</li>\n<li>To handle a higher volume of CSV file contents, you can do multithreaded or multiprocessing programming to complement the AWS Batch performance scale.</li>\n<li>Solution provided here lets you build, tag, and push the docker image to the repository (created as part of the stack). We’ve provided both a consolidated script files <code>— exec.sh</code> and <code>cleanup.sh</code>, as well as include individual commands, should you choose to manually run them to learn the workflow better. You can use the scripts included in this post with your existing CI/CD tooling, such as [AWS CodeBuild](https://aws.amazon.com/cn/codebuild/?trk=cndc-detail), or any other equivalent to build from repository and push to AWS ECR.</li>\\n<li>The example included in this blog post uses a simple AWS Lambda function to run jobs in AWS Batch, and the Lambda function code is in Python. You can use any of the other programming languages supported by AWS Lambda, for your function code. As an alternative to Lambda function code, you can also use AWS StepFunctions a low-code, visual workflow alternative to initiate the AWS Batch job.</li>\n</ul>\\n<h3><a id=\\"1_Deploying_the_AWS_CloudFormation_template_36\\"></a><strong>1. Deploying the AWS CloudFormation template</strong></h3>\\n<p>When deployed, the AWS CloudFormation template creates the following infrastructure.</p>\n<p><img src=\\"https://dev-media.amazoncloud.cn/bcb7699b9b5b4a7fb070bec392123278_image.png\\" alt=\\"image.png\\" /></p>\n<p>Download the source from the <a href=\\"https://github.com/aws-samples/aws-batch-processing-job-repo\\" target=\\"_blank\\">GitHub location</a>. Follow the steps below to use the downloaded code. The <code>exec.sh</code> script included in the repo will execute the CloudFormation template spinning up the infrastructure, a Python application (.py file) and a sample CSV file.</p>\\n<p>Note: <code>exec_ec2.sh</code> is also provided for reference. This has the implementation done using Managed EC2 instances as mentioned in the previous blog.</p>\\n<pre><code class=\\"lang-\\">\$ git clone https://github.com/aws-samples/aws-batch-processing-job-repo\\n</code></pre>\\n<pre><code class=\\"lang-\\">\$ cd aws-batch-processing-job-repo\\n</code></pre>\\n<pre><code class=\\"lang-\\">\$ ./exec.sh\\n</code></pre>\\n<p>Alternatively, you can also run individual commands manually as provided below to setup the infrastructure, push the docker image to ECR, and add sample files to S3 for testing.</p>\n<h3><a id=\\"Step_1_Setup_the_infrastructure_62\\"></a><strong>Step 1: Setup the infrastructure</strong></h3>\\n<pre><code class=\\"lang-\\">\$ STACK_NAME=fargate-batch-job\\n</code></pre>\\n<pre><code class=\\"lang-\\">\$ aws cloudformation create-stack --stack-name \$STACK_NAME --parameters ParameterKey=StackName,ParameterValue=\$STACK_NAME --template-body file://template/template.yaml --capabilities CAPABILITY_NAMED_IAM\\n</code></pre>\\n<p>After downloading the code, take a moment to review the “templates.yaml” in the “src” folder. The snippets below provide an overview of how the compute environment and a job definition can be specified easily using the managed serverless compute options that were introduced. “<a href=\\"https://github.com/aws-samples/aws-batch-processing-job-repo/blob/master/template/template_ec2.yaml\\" target=\\"_blank\\">templates_ec2.yaml</a>” has the older version of implementation done for EC2 as Compute Environment.</p>\\n<pre><code class=\\"lang-\\">ComputeEnvironment:\\n Type: AWS::Batch::ComputeEnvironment\\n Properties:\\n Type: MANAGED\\n State: ENABLED\\n ComputeResources:\\n Type: FARGATE\\n MaxvCpus: 40\\n Subnets:\\n - Ref: PrivateSubnet\\n SecurityGroupIds:\\n - Ref: SecurityGroup\\n ...\\n</code></pre>\\n<pre><code class=\\"lang-\\">BatchProcessingJobDefinition:\\n Type: AWS::Batch::JobDefinition\\n Properties:\\n ....\\n ContainerProperties:\\n Image: \\n ...\\n FargatePlatformConfiguration:\\n PlatformVersion: LATEST\\n ResourceRequirements:\\n - Value: 0.25\\n Type: VCPU\\n - Value: 512\\n Type: MEMORY\\n JobRoleArn: !GetAtt 'BatchTaskExecutionRole.Arn'\\n ExecutionRoleArn: !GetAtt 'BatchTaskExecutionRole.Arn'\\n ...\\n ...\\n PlatformCapabilities:\\n - FARGATE\\n</code></pre>\\n<p>When the preceding CloudFormation stack is created successfully, take a moment to identify the major components. The CloudFormation template spins up the following resources, which you can also view in the AWS Management Console.</p>\n<ol>\\n<li>CloudFormation Stack Name – fargate-batch-job</li>\n<li>S3 Bucket Name – fargate-batch-job<YourAccountNumber><br />\\n1.After the sample CSV file is dropped into this bucket, the process should kick start.</li>\n<li>JobDefinition – BatchJobDefinition</li>\n<li>JobQueue – fargate-batch-job-queue</li>\n<li>Lambda – fargate-batch-job-lambda</li>\n<li>DynamoDB – fargate-batch-job</li>\n<li>Amazon CloudWatch Log – This is created when the first execution is made.<br />\\n1./aws/batch/job<br />\\n2./aws/lambda/LambdaInvokeFunction</li>\n<li>CodeCommit – fargate-batch-jobrepo</li>\n<li>CodeBuild – fargate-batch-jobbuild</li>\n</ol>\\n<p>Once the above CloudFormation stack creation is complete in your personal account, we need to containerize the sample Python application and push it to ECR. We will use command line execution shell script to deploy the application and the infrastructure. Note that AWS CodeCommit and CodeBuild infrastructure are also created as part of the above template. The template on AWS CodeBuild can also run similar commands to deploy the necessary infrastructure.</p>\n<h3><a id=\\"2_Docker_Build_and_Push_128\\"></a><strong>2. Docker Build and Push</strong></h3>\\n<p>A simple Python application code is provided (in “src” folder). This is Docker containerized and pushed to the AWS Elastic Container Registry that was created with the CloudFormation template.</p>\n<pre><code class=\\"lang-\\">\$ STACK_NAME=fargate-batch-job \\n\$ REGION=\$(aws ec2 describe-availability-zones --output text --query 'AvailabilityZones[0].[RegionName]')\\n\\n\$ ACCOUNT_NUMBER=\$(aws sts get-caller-identity --query 'Account' --output text)\\n\\n\$ SOURCE_REPOSITORY=\$PWD \\n\$ docker build -t batch_processor .\\n\\n\$ docker tag batch_processor \$(aws sts get-caller-identity --query 'Account' --output text).dkr.ecr.\$REGION.amazonaws.com/\$STACK_NAME-repository \\n\$ aws ecr get-login-password --region \$REGION | docker login --username AWS --password-stdin \$(aws sts get-caller-identity --query 'Account' --output text).dkr.ecr.\$REGION.amazonaws.com \\n\$ docker push \$(aws sts get-caller-identity --query 'Account' --output text).dkr.ecr.\$REGION.amazonaws.com/\$STACK_NAME-repository \\n</code></pre>\\n<h3><a id=\\"3_Testing_145\\"></a><strong>3. Testing</strong></h3>\\n<p>In this step we will go over testing with a <code>sample.csv</code>, either uploaded manually or via the AWS CLI to the AWS S3 bucket. Make sure to complete the previous step of pushing the built image of the Python code to ECR, before testing. You can verify your build and push by going to the AWS Console > ECR – “fargate-batch-job” repository</p>\\n<ol>\\n<li>You will see AWS S3 bucket – fargate-batch-job- is created as part of the stack.</li>\n<li>you will need to drop the provided <code>sample.csv</code> into this S3 bucket. Once you add the file to S3, the Lambda function will be triggered to start AWS Batch. To run the command manually, execute the following —</li>\\n</ol>\n<p>Bash</p>\n<pre><code class=\\"lang-\\">\$ aws s3 --region \$REGION cp \$SOURCE_REPOSITORY/sample/sample.csv s3://\$STACK_NAME-\$ACCOUNT_NUMBER\\n</code></pre>\\n<ol start=\\"3\\">\\n<li>In AWS Console > Batch, notice that the Job runs and performs the operation based on the pushed container image. The job parses the CSV file and adds each row into DynamoDB.</li>\n</ol>\\n<h3><a id=\\"4_Validation_159\\"></a><strong>4. Validation</strong></h3>\\n<ol>\\n<li>In AWS Console > DynamoDB, look for “fargate-batch-job” table. Note sample products provided as part of the CSV is added by the batch</li>\n</ol>\\n<h3><a id=\\"Code_cleanup_163\\"></a><strong>Code cleanup</strong></h3>\\n<p>Use the <code>cleanup.sh</code> script to remove the [Amazon S3](https://aws.amazon.com/cn/s3/?trk=cndc-detail) files, Amazon ECR repository images and the [AWS CloudFormation](https://aws.amazon.com/cn/cloudformation/?trk=cndc-detail) stack that was spun up as part of previous steps.</p>\\n<pre><code class=\\"lang-\\">\\n\$ ./cleanup.sh\\n</code></pre>\\n<p>Alternatively, you can follow the steps below to manually clean up the built environment</p>\n<ol>\\n<li>AWS Console > S3 bucket – fargate-batch-job- – Delete the contents of the file</li>\n<li>AWS Console > ECR – fargate-batch-job-repository – delete the image(s) that are pushed to the repository</li>\n<li>Run the below command to delete the stack.</li>\n</ol>\\n<pre><code class=\\"lang-\\">\$ aws cloudformation delete-stack --stack-name fargate-batch-job\\n\\n</code></pre>\\n<ol>\\n<li>To perform all the above steps in CLI</li>\n</ol>\\n<pre><code class=\\"lang-\\">\$ SOURCE_REPOSITORY=\$PWD \\n\$ STACK_NAME=fargate-batch-job \\n\$ REGION=\$(aws ec2 describe-availability-zones --output text —query 'AvailabilityZones[0].[RegionName]')\\n\\n\$ ACCOUNT_NUMBER=\$(aws sts get-caller-identity --query 'Account' —output text)\\n\\n\$ aws ecr batch-delete-image --repository-name \$STACK_NAME-repository --image-ids imageTag=latest \\n\$ aws ecr batch-delete-image --repository-name \$STACK_NAME-repository --image-ids imageTag=untagged \\n\$ aws s3 --region \$REGION rm s3://\$STACK_NAME-\$ACCOUNT_NUMBER —recursive \\n\$ aws cloudformation delete-stack --stack-name \$STACK_NAME\\n\\n</code></pre>\\n<h3><a id=\\"References_197\\"></a><strong>References</strong></h3>\\n<ol>\\n<li><a href=\\"https://aws.amazon.com/blogs/aws/new-fully-serverless-batch-computing-with-aws-batch-support-for-aws-fargate/\\" target=\\"_blank\\">New – Fully Serverless Batch Computing with AWS Batch Support for AWS Fargate</a></li>\\n<li><a href=\\"https://docs.aws.amazon.com/batch/latest/userguide/fargate.html\\" target=\\"_blank\\">AWS Batch on AWS Fargate</a></li>\\n<li><a href=\\"https://docs.aws.amazon.com/step-functions/latest/dg/connect-batch.html\\" target=\\"_blank\\">Manage AWS Batch with Step Functions</a></li>\\n</ol>\n<h3><a id=\\"Conclusion_204\\"></a><strong>Conclusion</strong></h3>\\n<p>Following the solution in the post, you will be able to launch an application workflow using AWS Batch integrating with various AWS services. You also have access to the Python script, CloudFormation template, and the sample CSV file in the corresponding GitHub repo that takes care of all the preceding CLI arguments for you to build out the job definitions.</p>\n<p>As stated in the post, with AWS Fargate, you no longer have to provision, configure, or scale clusters of virtual machines to run containers. This removes the need to choose server types, decide when to scale your clusters, or optimize cluster packing. With Fargate or Fargate Spot, you don’t need to worry about Amazon EC2 instances or Amazon Machine Images. Just set Fargate or Fargate Spot, your subnets, and the maximum total vCPU of the jobs running in the compute environment, and you have a ready-to-go Fargate computing environment. With Fargate Spot, you can take advantage of up to 70% discount for your fault-tolerant, time-flexible jobs.</p>\n<p>I encourage you to test this example and see for yourself how this overall orchestration works with AWS Batch. Then, it is just a matter of replacing your Python (or any other programming language framework) code, packaging it as a Docker container, and letting the AWS Batch handle the process efficiently.</p>\n<p>If you decide to give it a try, have any doubt, or want to let me know what you think about the post, please leave a comment!</p>\n<h4><a id=\\"About_the_Author_214\\"></a><strong>About the Author</strong></h4>\\n<p><img src=\\"https://dev-media.amazoncloud.cn/8ce213aafd554cae923306d12317b151_image.png\\" alt=\\"image.png\\" /></p>\n<p>Sivasubramanian Ramani (Siva Ramani) is a Sr Cloud Application Architect at AWS. His expertise is in application optimization, serverless solutions with AWS.</p>\n"}
Amazon Batch Application Orchestration using Amazon Fargate
海外精选

海外精选的内容汇集了全球优质的亚马逊云科技相关技术内容。同时,内容中提到的“AWS”
是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。

 0
0 0
0亚马逊云科技解决方案 基于行业客户应用场景及技术领域的解决方案
联系亚马逊云科技专家
亚马逊云科技解决方案
基于行业客户应用场景及技术领域的解决方案
联系专家

0
目录

 分享
分享 点赞
点赞 收藏
收藏 目录
目录立即注册,开启您的免费套餐
立即关注

亚马逊云开发者
公众号

User Group
公众号

亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
关于我们 
更多资源
开发者工具
更多支持
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
