{"value":"### **数据湖的挑战**\n伴随着云服务的流行,数据湖技术渐渐兴起,越来越多的企业开始搭建自己的数据湖。但传统数据湖基于文件,一般都是以追加的形式修改数据。当有数据需要改变时,经常需要读取全部内容重新写回到平台。基于 HDFS、S3 等传统数据湖方案,只能增加文件不方便修改文件中的内容。想要实现某条记录的 UPSERT(UPDATE 和 INSERT 的混合)变更,工程师需要构建复杂的 Pipeline 来读取整个分区或表,需要读取对应的文件并进行重写,这种Pipeline 效率很低,而且难以维护。另外,数据工程师经常遇到这样的问题:不安全地写入数据湖,这会导致如果读取数据过程中同时又有数据写入,那么将会产生垃圾数据。那么必须构建其他额外的方法,来保证数据同时读写情况的数据一致性。\n\n而在日常数据运维过程当中,往往又会遇到过多小文件的问题,特别是在流数据入湖的场景里,原始数据注入通常都会以 kilobytes 甚至是 bytes 级别大小的文件保存,这在后续当业务需要去 query 这些历史数据时,会极大的影响 query 的性能。所以运维数据湖平台时需要面对的一个最常见的场景就是需要在不影响业务的情况下,去清理合并那些小文件来提高 query 数据湖的性能。另外,如果具体业务场景对时延要求没有非常高,比如下游报表可以允许分钟甚至小时级别数据展示,那么就没有必要持续运行流式作业,针对这种成本敏感型的需求,应该有一种方式允许空闲计算资源自动停机。而针对这些场景,我们也会在这篇博客中给出一个合理的解决方法。\n\n本篇博客会使用开源 Delta Lake 结合 Amazon Glue, 简化构建数据湖的方式去解决上述问题。我们会带您一步一步地在 Amazon 上部署近实时的流式数据入湖的方案。包括从 Amazon MSK 当中读取流式数据,核对数据schema,使用 Amazon Glue 实现无服务器流式 ETL 作业,并且实现像关系型数据库一样的增删查改,保证 ACID。与此同时,我们还会使用 MWAA (Managed Workflow for Apache Airflow)来实现数据湖上运维自动化,包括性能的优化。最终在数据湖上实现海量数据 UPSERT 以及事务的管理能力,即事务型的数据湖。\n\n我们会使用一些模拟的业务库发过来的订单和会员信息作为流式数据的来源,使用MSK对接,然后通过 Glue Job 读取并向下游拥有UPSERT能力的数据湖(Delta Lake)进行同步并将这种有变更状态的数据存储于 Amazon S3,并通过 Amazon Athena 来提供实时数仓查询并通过 QuickSight 进行 Dashboard 展示。整套方案大部分是基于 Amazon 的托管服务,具有开箱即用,自动扩展,内置高可用性和按使用付费的计费模式,可提高敏捷性,优化成本同时减少数据运维的工作。\n\n### **开源 Delta Lake 简介**\n开源 Delta Lake 是基于 Apache Spark 的下一代数据湖存储引擎,也是目前市面上主流的数据湖存储引擎之一。支持MERGE命令,可以高效的完成 UPSERT 语义。同时 Delta Lake 将 ACID 事务带入数据湖,提供了可序列化性,最强的隔离级别。Delta Lake 就是既能解决更新效率低下,又能进行并发读写控制,还支持时间回溯,查看历史任意时间的数据快照。也正是这些优越的特性,所以我们决定以开源 Delta Lake 为核心搭建数据湖。\n\n以下是 Dela Lake 的基本能力的一个总结:\n\n1. 支持 UPSERT/DELETE:Delta Lake 将支持 MERGE、UPDATE 和 DELETE 的 DML 命令。可以轻松地在数据湖中插入和删除记录,并简化他们的变更数据捕获和满足GDPR。\n2. ACID 事务性:Delta Lake 在多个写操作之间提供 ACID 事务性。每一次写操作都是一个事务操作,事务日志(Transaction Log)中记录的写操作都有一个顺序序列。\n3. Schema 管理:Delta Lake 会自动验证正在写入的 Spark DataFrame 的 Schema 是否与表的 Schema 兼容。\n4. 数据版本控制和时间旅行:Delta Lake 允许用户读取表或目录的历史版本快照。当文件在写入过程中被修改时,Delta Lake 会创建文件的新的版本并保留旧版本。当用户想要读取表或目录的较旧版本时,他们可以向 Apache Spark 的 read API 提供时间戳或版本号。\n5. 可伸缩的元数据(Metadata)处理:Delta Lake 将表或目录的元数据信息存储在事务日志(Transaction Log)中,而不是元数据 Metastore 中。这使得 Delta Lake 够在固定时间内列出大目录中的文件,并且在读取数据时效率更高。\n### **解决方案架构**\n由于篇幅有限,本篇博客主要是在验证使用开源 Delta Lake 在 Amazon 上构建事务型数据湖的可行性,而对于数据湖上跟事务不直接相关的特征,包括数据血缘,数据权限等,会暂时忽略。而本篇博客的实验环境会基于下图的架构搭建。其中,数据源方面,我们会使用 Python 的 Faker 库产生一些 dummy data,并将这些 dummy data注入到 Amazon MSK (托管型的Kafka集群),然后会使用带有 delta jar 包的 Glue ETL streaming job 来将数据从 Kafka 集群中取出,并做去重处理,存储在核心数据湖存储(S3)中,而在这里核心验证的概念就是当新的数据是去更新已有的数据列时,Delta Lake 会保证已经存储在数据湖中的数据得到相应的更新而不是简单的 append only。这种持续更新的数据最终我们也会通过Athena(托管的presto服务)query 来做一个展示,以证明数据持续的更新能够可靠的以近实时的效率在 BI 报表中展示。\n\n\n\n在这里还需要说明的是目前这个架构虽然是实时流式处理。但 glue streaming 本身就是基于 spark structured streaming 的引擎,其对于流的处理实际上是以微批的形式,那么这也就意味着截取微批的时间窗口会对数据的延迟性产生较大的影响,并且我们在第三个 Job 做 UPSERT 处理时,如果在同一个微批内出现多条反复更改同一条数据的事务,那么将只有那个微批内的最新的更改会出现在 processed 的表内,也意味着每个微批实际上只会记录下最新的更改。这也是为什么我们会主张在数据湖上分多个层级来收纳流式数据入湖。\n\n架构上 Job1 负责从 MSK 读取原始数据并且把数据以 Delta 的格式写入原始数据层(raw layer),同时我们会按 processing time 以年、月、天、小时来分区。数据在进入这一层前没有做数据清洗和处理,并允许重复订单和会员数据直接以 append only 的方式全量的录入数据湖保证 Single source of truth。我们为了模拟一个更加接近真实的业务景,Job2 从原始数据层读取数据,做了一些业务处理的逻辑和数据清洗,例如我们实现了 Stream-Stream Join (流关联)和字段的处理。最后通过 Job3 基于 Append Only 产生的 Delta table 做 MERGE 处理,实现 UPSERT 逻辑然后写入处理层(processed layer)的 ODS 表供下游消费端查询,这一层类似 ODS 层, 可以做进一步数据清洗和去重等业务逻辑。Job4 主要是用 Delta API 来生成 Manifest 文件便于 Athena 可以查询到 Delta table。\n\n### **环境搭建**\n本博客使用东京区域进行搭建,但读者可自由选择区域,架构中所用到的组件已经在 Amazon 的大多数区域上线。\n\n#### **前提条件**\n1. 具有管理员权限的 Amazon 账号\n2. 本地安装有 [Amazon CLI](https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html),以及 [terraform](https://www.terraform.io/downloads)\n3. 配置好 Amazon profile 的 access key, secret key (详细可参看[link](https://docs.aws.amazon.com/cli/latest/userguide/cli-configure-files.html))\n\n\n本博客假定读者都具备有基础的 Amazon 知识,并且熟悉 Amazon 服务的基本概念,有使用 Amazon 的经验。整个架构的实现代码可以参考[link](https://github.com/wei-zhong90/deltalake-aws-poc-demo)\n\n#### **步骤 1: 网络环境**\n由于架构中使用了 Amazon MSK (Managed Streaming for Apache Kafka),我们需要搭建一个 VPC 环境。而这里的VPC的网络选择可以根据自己的需要来,我们在这个实验环境里用到的 Kafka 由于不需要接收来自于 VPC 外部的流量,所以我们的 VPC 并不需要任何互联网访问的途径。整个 VPC 搭建比较简单,在这里也不再过多的赘述。为方便大家搭建起整个实验环境,我们也已将整个环境写成了 terraform code 来实现一键化部署。\n\n首先将代码下载至本地:\n\n```\ngit clone git@github.com:wei-zhong90/deltalake-aws-poc-demo.git\ncd deltalake-aws-poc-demo/infrastructure\n```\n\n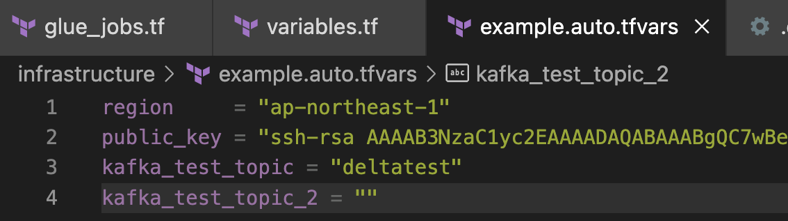\n\n然后修改相应的参数:\n\n其中这四个参数分别代表:\n\n- region: 环境部署的区域\n- public_key: 之后会用来登录测试实例用的密钥对的公钥\n- kafka_test_topic, kafka_test_topic_2分别代表着 Kafka 集群用来接收数据的两个 topic 的名字,可自定义这两个topic的名字\n\n\n在修改好相应参数后,便可执行以下代码进行部署:\n\n```\nterraform init\nterraform apply\n```\n\n这一部分的 terraform 代码会直接部署好一个 vpc,一个msk集群,一个测试用 linux 实例,以及三个后面会详细介绍的 glue streaming job。整个过程可能会需要花35分钟,主要是 MSK 的部署会需要消耗大量的时间。\n\n#### **步骤 2: 启动订单和会员数据生成程序**\n在整个部署完成以后,可以进入到 ec2 的控制台界面查看新生成的名为“msk-dev-workspace”的实例,如下图。\n\n\n\n使用之前部署时配置的密匙对 ssh 进入该实例,在 HOME 路径下会看见一个 kafka 的 dir,这个实际上是 Kafka 的官方安装包,我们之后也会用这个安装包里面的工具来查看 MSK 集群里的数据。\n\n\n\n接下来,我们需要启动订单数据生成程序,执行以下命令:\n\n```\ncd deltalake-aws-poc-demo\npython3 -m virtualenv .venv\nsource .venv/bin/activate\npython3 -m pip install -r requirements.txt\nvi .env\n```\n\n\n\n这个时候会进入到以下界面:\n\n在这里我们需要将这几个变量换成我们自己设定的几个值。首先,BOOTSTRAP_SERVERS 的值来自于之前部署好的 MSK 集群,我们可以进入到 MSK 的控制台进行查看,如下。\n\n\n\n我们会在 MSK 的控制台下看到一个新的 MSK 集群,名为 app;然后点进这个集群后就可以在右上角点击‘View client information’,就可以看到几种节点的连接链接,在这里我们需要复制 TLS 的链接,然后填到 BOOTSTRAP_SERVERS 的变量下面。而后面的几个变量, TOPIC, SECOND_TOPIC 则是我们之前在部署 terraform 代码时更改的那两个 topic 的变量名称,请务必注意保持一致。最后两个变量是用来控制订单数据生成的量和频率的,在这里可以不做更改。\n\n在完成更改以后,保存更改,即可执行一下指令,开始自动生成订单数据,并发送至 Kafka 集群。\n\n```python3 generator.py```\n\n在执行完这条指令后,一个简单的 python 程序就会开始向定义的那两个 topic 里面发送两种数据,一种是订单数据,一种则是会员等级变更数据,我们在之后的 glue 中就会对这两种数据进行收集和处理。\n\n在这里需要说明的是,这里生成的订单数据实际上只有六种订单,在下图中可以看到这六种订单实际上就是分属于6个不同的 order_id 及 order_owner,而不断生成的订单数据则是不断的更新这六种订单的 order_value 和 timestamp。另外一种会员等级变更数据则是针对这六个 order_owner 不断的更改他们的 membership 的等级。在实际场景中,订单数据并不会如此频繁的更改,会员等级更不会频繁变动,但在这个实验环境下,我们为了展示 Delta lake 的 Upsert 特性,就模拟了这种极端的情况。\n\n\n\n#### **步骤 3: 配置 Glue 作业**\nAmazon Glue 是一项完全托管,无服务器架构的 ETL 服务。客户无需预置基础设置,仅需由 Glue 负责预置、扩展 Spark 运行环境,客户只需要专注开发 ETL 代码,并且使用 Amazon Glue 时,只需为 ETL 作业运行时间付费。另外,Glue Streaming 基于开源 Spark Structured Streaming 构建,面向微批处理,继承了 Spark 的所有特性可以完全集成 Delta Lake。\n\n本步骤阐述了用 Amazon Glue 来搭建三个流式 ETL 作业的业务逻辑,具体 Glue 任务和代码都会通过 Terraform 来自动部署, 我们主要重点介绍Job的功能实现而不是 Job 的具体配置,Terraform 会创建如下三个Job:\n\n- raw_process\n- join_process\n- upsert_process\n\n3.1 第一个 Job 负责从 MSK 读取原始数据并且把数据以 Delta 的格式写入原始数据层(raw layer),同时我们会按 processing time 以年、月、天、小时来分区。数据在进入这一层前没有做数据清洗和处理,并允许重复订单和会员数据,在实际生产中这一层也可以根据业务命名为 Staging Layer/Ingestion Layer/Landing Area。\n\n```\nimport sys\nfrom awsglue.transforms import *\nfrom awsglue.utils import getResolvedOptions\nfrom pyspark.context import SparkContext\nfrom awsglue.context import GlueContext\nfrom pyspark.context import SparkConf\nfrom awsglue.job import Job\n# Import the packages\nfrom delta import *\nfrom pyspark.sql.session import SparkSession\nfrom datetime import datetime\n\nfrom pyspark.sql.types import StructType, StructField, StringType, IntegerType, TimestampType\nfrom pyspark.sql.functions import col, from_json, lit\n\nargs = getResolvedOptions(sys.argv, ['JOB_NAME', 'bucket_name', 'bootstrap_servers', 'topic1', 'topic2'])\ndata_bucket = args['bucket_name']\nbootstrap_servers = args['bootstrap_servers']\ntopic1 = args['topic1']\ntopic2 = args['topic2']\ncheckpoint_bucket1 = f\"s3://{data_bucket}/checkpoint/\"\ncheckpoint_bucket2 = f\"s3://{data_bucket}/membership_checkpoint/\"\n \nschema1 = StructType([ \\\n StructField(\"order_id\", IntegerType(), True), \\\n StructField(\"order_owner\", StringType(), True), \\\n StructField(\"order_value\", IntegerType(), True), \\\n StructField(\"timestamp\", TimestampType(), True), ])\n\nschema2 = StructType([ \\\n StructField(\"order_owner\", StringType(), True), \\\n StructField(\"membership\", StringType(), True), \\\n StructField(\"timestamp\", TimestampType(), True), ])\n\ndef insertToDelta1(microBatch, batchId): \n date = datetime.today()\n year = date.strftime(\"%y\")\n month = date.strftime(\"%m\")\n day = date.strftime(\"%d\")\n hour = date.strftime(\"%H\")\n if microBatch.count() > 0:\n df = microBatch.withColumn(\"year\", lit(year)).withColumn(\"month\", lit(month)).withColumn(\"day\", lit(day)).withColumn(\"hour\", lit(hour))\n df.write.partitionBy(\"year\", \"month\", \"day\", \"hour\").mode(\"append\").format(\"delta\").save(f\"s3://{data_bucket}/raw/order/\")\n\ndef insertToDelta2(microBatch, batchId):\n if microBatch.count() > 0:\n microBatch.write.partitionBy(\"order_owner\").mode(\"append\").format(\"delta\").save(f\"s3://{data_bucket}/raw/member/\")\n\nclass JobBase(object):\n fair_scheduler_config_file= \"fairscheduler.xml\"\n def get_options(self, bootstrap_servers, topic):\n return {\n \"kafka.bootstrap.servers\": bootstrap_servers,\n \"subscribe\": topic,\n \"kafka.security.protocol\": \"SASL_SSL\",\n \"kafka.sasl.mechanism\": \"AWS_MSK_IAM\",\n \"kafka.sasl.jaas.config\": \"software.amazon.msk.auth.iam.IAMLoginModule required;\",\n \"kafka.sasl.client.callback.handler.class\": \"software.amazon.msk.auth.iam.IAMClientCallbackHandler\",\n \"startingOffsets\": \"earliest\",\n \"maxOffsetsPerTrigger\": 1000,\n \"failOnDataLoss\": \"false\"\n }\n def __start_spark_glue_context(self):\n conf = SparkConf().setAppName(\"python_thread\").set('spark.scheduler.mode', 'FAIR').set(\"spark.scheduler.allocation.file\", self.fair_scheduler_config_file)\n self.sc = SparkContext(conf=conf)\n self.glue_context = GlueContext(self.sc)\n self.spark = self.glue_context.spark_session\n def execute(self):\n self.__start_spark_glue_context()\n self.logger = self.glue_context.get_logger()\n self.logger.info(\"Starting Glue Threading job \")\n import concurrent.futures\n executor = concurrent.futures.ThreadPoolExecutor(max_workers=2)\n executor.submit(self.workflow, topic1, schema1, insertToDelta1, checkpoint_bucket1, 1)\n executor.submit(self.workflow, topic2, schema2, insertToDelta2, checkpoint_bucket2, 2)\n self.logger.info(\"Completed Threading job\")\n \n \n def workflow(self, topic, schema, insertToDelta, checkpoint_bucket, poolname):\n \n self.sc.setLocalProperty(\"spark.scheduler.pool\", str(poolname))\n # Read Source\n df = self.spark \\\n .readStream \\\n .format(\"kafka\") \\\n .options(**self.get_options(bootstrap_servers, topic)) \\\n .load().select(col(\"value\").cast(\"STRING\"))\n\n df2 = df.select(from_json(\"value\", schema).alias(\"data\")).select(\"data.*\")\n\n\n # Write data as a DELTA TABLE\n df3 = df2.writeStream \\\n .foreachBatch(insertToDelta) \\\n .option(\"checkpointLocation\", checkpoint_bucket) \\\n .trigger(processingTime=\"60 seconds\") \\\n .start()\n\n df3.awaitTermination()\n\ndef main():\n job = JobBase()\n job.execute()\n\n\nif __name__ == '__main__':\n main()\n```\n\n3.1.1 在代码里,由于订单及会员数据被分别发送至 kafka stream 里面的两个 topic,所以第一个用于收集原始订单和会员数据的 glue job 需要能够同时从两个 kafka topic 里面读取数据,然后并发分别写入两张 Delta 表,我们使用了 Python 多线程模块 concurrent.futures 和 ThreadPoolExecutor 类来并发调用两次 workflow function,在 workflow function 内首先读取 Kafka 的 Topic 并通过 IAM 认证方式读取流式加密的数据并转化数据为 STRING 格式:\n\n```\n def workflow(self, topic, schema, insertToDelta, checkpoint_bucket, poolname):\n \n self.sc.setLocalProperty(\"spark.scheduler.pool\", str(poolname))\n # Read Source\n df = self.spark \\\n .readStream \\\n .format(\"kafka\") \\\n .options(**self.get_options(bootstrap_servers, topic)) \\\n .load().select(col(\"value\").cast(\"STRING\"))\n```\n\n3.1.2 通过 from_json 把 JSON string 转化为事先定义好的DataFrame StructType:\n\n```\ndf2 = df.select(from_json(\"value\", schema).alias(\"data\")).select(\"data.*\")\n```\n\n3.1.3 通过 Spark 资源调度 Fair Scheduler 的self.sc.setLocalProperty(“spark.scheduler.pool”, str(poolname)),我们可以提交 Job 到指定的 pool ,从而实现在一个 Glue Job 里资源的平等分配, 我们用到 foreachbatch API 去触发一个传入的insertToDelta function 参数,具体逻辑通过insertToDelta1 和 insertToDelta2 函数里按照每60秒的窗口把数据按照类似 Hive 分区方式,以 Processing time 的年、月、日、小时来写入到 S3上,例如InsertToDelta1:\n\n```\ndef insertToDelta1(microBatch, batchId): \n date = datetime.today()\n year = date.strftime(\"%y\")\n month = date.strftime(\"%m\")\n day = date.strftime(\"%d\")\n hour = date.strftime(\"%H\")\n if microBatch.count() > 0:\n df = microBatch.withColumn(\"year\", lit(year)).withColumn(\"month\", lit(month)).withColumn(\"day\", lit(day)).withColumn(\"hour\", lit(hour))\n df.write.partitionBy(\"year\", \"month\", \"day\", \"hour\").mode(\"append\").format(\"delta\").save(f\"s3://{data_bucket}/raw/order/\")\n```\n\n3.2 第二个作业,主要是用来实现一个订单和对应会员数据的流关联,我们假设想实时分析一个会员状态和下单之间的关系,就需要将两个流按用户名字进行 Join。流和流的关联目前不支持 update 模式, 所以我们还是以追加的形式把关联后的数据写入 curated 层。\n\n```\nimport com.amazonaws.services.glue.{DynamicFrame, GlueContext}\nimport com.amazonaws.services.glue.errors.CallSite\nimport com.amazonaws.services.glue.util.{GlueArgParser, Job, JsonOptions}\nimport org.apache.spark.{SparkContext, SparkConf}\nimport org.apache.spark.sql.{Dataset, Row, SaveMode, SparkSession, DataFrame}\nimport org.apache.spark.sql.functions._\nimport org.apache.spark.sql.streaming.Trigger\nimport org.apache.spark.sql.types.{StructType, StructField, StringType, IntegerType, DoubleType, BooleanType, TimestampType}\nimport org.apache.spark.sql.streaming.{StreamingQuery, Trigger}\nimport scala.collection.JavaConverters._\nimport io.delta.tables.DeltaTable\nimport org.apache.spark.sql.expressions.Window\n\nimport scala.collection.JavaConverters._\n\n\nobject GlueApp {\n def main(sysArgs: Array[String]): Unit = {\n \n val spark: SparkContext = new SparkContext()\n val glueContext: GlueContext = new GlueContext(spark)\n val sparkSession: SparkSession = glueContext.getSparkSession\n import sparkSession.implicits._\n // @params: [JOB_NAME]\n val args = GlueArgParser.getResolvedOptions(sysArgs, Seq(\"JOB_NAME\", \"bucket_name\").toArray)\n Job.init(args(\"JOB_NAME\"), glueContext, args.asJava)\n\n val CheckpointDir = s\"s3://${args(\"bucket_name\")}/checkpoint2\"\n\n val raworder = sparkSession.readStream.format(\"delta\").load(s\"s3://${args(\"bucket_name\")}/raw/order/\").withWatermark(\"timestamp\", \"3 hours\")\n val rawmember= sparkSession.readStream.format(\"delta\").load(s\"s3://${args(\"bucket_name\")}/raw/member/\").withWatermark(\"timestamp\", \"2 hours\")\n\n val joinedorder = raworder.alias(\"order\").join(\n rawmember.alias(\"member\"),\n expr(\"\"\"\n order.order_owner = member.order_owner AND\n order.timestamp >= member.timestamp AND\n order.timestamp <= member.timestamp + interval 1 hour\n \"\"\")\n ).select($\"order.order_id\", $\"order.order_owner\", $\"order.order_value\", $\"order.timestamp\", $\"member.membership\", $\"order.year\", $\"order.month\", $\"order.day\", $\"order.hour\")\n\n\n val query = joinedorder\n .writeStream\n .format(\"delta\")\n .option(\"checkpointLocation\", CheckpointDir)\n .trigger(Trigger.ProcessingTime(\"60 seconds\"))\n .outputMode(\"append\")\n .partitionBy(\"year\", \"month\", \"day\", \"hour\")\n .start(s\"s3://${args(\"bucket_name\")}/curated/\")\n\n query.awaitTermination() \n \n Job.commit()\n\n }\n\n}\n```\n\n3.2.1 流之间关联和静态数据之间的关联有一个不同,对流来说任何时候关联双方的数据都是没有边界的,也叫无界流,当前流上的任何一行数据都有可能和另一条流上未来的一行数据关联上,所以我们需要制定一个时间范围。首先我们分别给订单和会员流设定 Watermark(水位线),用来抛弃超过约定时间到达的输入数据,订单最多允许迟到三小时,会员最多允许迟到两小时。\n\n```\nval raworder = sparkSession.readStream.format(\"delta\").load(s\"s3://${args(\"bucket_name\")}/raw/order/\").withWatermark(\"timestamp\", \"3 hours\")\n val rawmember = sparkSession.readStream.format(\"delta\").load(s\"s3://${args(\"bucket_name\")}/raw/member/\").withWatermark(\"timestamp\", \"2 hours\")\n```\n\n3.2.2 另外,我们定义跨两个流的 event time 约束,以便可以确定何时不需要一个输入流与另一个输入流匹配。我们用时间范围关联条件(join condition)定义此约束。比如说,在我们场景里假设会员的状态变化可以转化为订单的生成,所以订单可以在相应的会员状态变化后 0 秒到 1 小时的时间范围内发生。如下是约束的逻辑:\n```\nval joinedorder = raworder.alias(\"order\").join(\n rawmember.alias(\"member\"),\n expr(\"\"\"\n order.order_owner = member.order_owner AND\n order.timestamp >= member.timestamp AND\n order.timestamp <= member.timestamp + interval 1 hour\n \"\"\")\n```\n\n3.3 第三个作业从原始数据层读取数据,然后进行数据清洗,实现 UPSERT 逻辑然后写入处理层(processed layer),这一层类似 ODS 层, 可以做数据清洗和去从等业务逻辑。同时,我们使用 Spark 原生的trigger.once mode 实现一次性的流式处理,这样的配置能够允许 glue streaming job 在 kafka stream 里面的新增数据处理完之后自动停止,以避免了24*7运行成本。另外,本篇博客以主要以介绍实现 UPSERT 场景为主,在实际生产中,后面还会有类似 EDW、DM 或 DWD、DWS、ADS 等数据湖上的分层和一些 Delta Lake 高级功能例如窗口聚合, 流批一体等。\n\n```\nimport com.amazonaws.services.glue.{DynamicFrame, GlueContext}\nimport com.amazonaws.services.glue.errors.CallSite\nimport com.amazonaws.services.glue.util.{GlueArgParser, Job, JsonOptions}\nimport org.apache.spark.{SparkContext, SparkConf}\nimport org.apache.spark.sql.{Dataset, Row, SaveMode, SparkSession, DataFrame}\nimport org.apache.spark.sql.functions._\nimport org.apache.spark.sql.streaming.Trigger\nimport org.apache.spark.sql.types.{StructType, StructField, StringType, IntegerType, DoubleType, BooleanType, TimestampType}\nimport org.apache.spark.sql.streaming.{StreamingQuery, Trigger}\nimport scala.collection.JavaConverters._\nimport io.delta.tables.DeltaTable\nimport org.apache.spark.sql.expressions.Window\n\nimport scala.collection.JavaConverters._\n\n\nobject GlueApp {\n def main(sysArgs: Array[String]): Unit = {\n \n val spark: SparkContext = new SparkContext()\n val glueContext: GlueContext = new GlueContext(spark)\n val sparkSession: SparkSession = glueContext.getSparkSession\n import sparkSession.implicits._\n // @params: [JOB_NAME]\n val args = GlueArgParser.getResolvedOptions(sysArgs, Seq(\"JOB_NAME\", \"bucket_name\").toArray)\n Job.init(args(\"JOB_NAME\"), glueContext, args.asJava)\n \n //read base\n val BasePath = s\"s3://${args(\"bucket_name\")}/processed\"\n val Basetable = DeltaTable.forPath(sparkSession, BasePath)\n val CheckpointDir = s\"s3://${args(\"bucket_name\")}/checkpoint3\"\n //read from upstream joined stream\n val raw = sparkSession.readStream.format(\"delta\").load(s\"s3://${args(\"bucket_name\")}/curated/\")\n \n def upsertIntoDeltaTable(updatedDf: DataFrame, batchId: Long): Unit = {\n \n val w = Window.partitionBy($\"order_id\").orderBy($\"timestamp\".desc)\n val Resultdf = updatedDf.withColumn(\"rownum\", row_number.over(w)).where($\"rownum\" === 1).drop(\"rownum\")\n \n // Merge from base with source\n Basetable.alias(\"b\").merge(\n Resultdf.alias(\"s\"),\n \"s.order_id = b.order_id\")\n .whenMatched.updateAll()\n .whenNotMatched.insertAll()\n .execute()\n }\n\n\n val query = raw\n .writeStream\n .format(\"delta\")\n .foreachBatch(upsertIntoDeltaTable _)\n .option(\"checkpointLocation\", CheckpointDir)\n .trigger(Trigger.Once())\n .outputMode(\"update\")\n .start(s\"s3://${args(\"bucket_name\")}/processed/\")\n\n query.awaitTermination() \n \n \n Job.commit()\n\n }\n\n}\n```\n\n3.3.1 在代码里,作业会消费从上次工作完成后的新增订单和会员关联后的数据,Trigger.Once()会把所有数据处理完后自动停止Glue作业,非常经济高效。另外,这里由于我们订单和会员是源源不断的写入到 raw 层,会产生非常多的重复订单号, 所以我们需要在每个foreachbatch 里通过一个机制去拿到 Streaming DataFrame,即传给 upsertIntoDeltaTable 函数每一批updatedDF DataFrame 里最新的那个关联后的记录。首先,我们是通过 **SQL PARTITION BY** 配合 **OVER** 的方式,通过给 order_id 分组并给 timestamp 排序拿到最新的时间戳, 也就是 rownum = 1的那条订单记录。然后,通过 Delta Merge API 来实现 Resultdf 和 Basetable 的 UPSERT 操作,注意 Basetable 是从 curated 层读取的 Delta 表,第一次需要手动建一个空表,后面3.3会提到。最后通过 trigger(Trigger.Once())的方式通过 delta API 写入到S3的 processed 层更新 Delta 表。\n\n ```\n def upsertIntoDeltaTable(updatedDf: DataFrame, batchId: Long): Unit = {\n val w = Window.partitionBy($\"order_id\").orderBy($\"timestamp\".desc)\n val Resultdf = updatedDf.withColumn(\"rownum\", row_number.over(w)).where($\"rownum\" === 1).drop(\"rownum\")\n // Merge from base with source\n Basetable.alias(\"b\").merge(\n Resultdf.alias(\"s\"), \n \"s.order_id = b.order_id\")\n .whenMatched.updateAll()\n .whenNotMatched.insertAll()\n .execute()\n }\n```\n\n3.3.2 最后我们还需要在 processed 层创建一个的初始表,里面没有数据。因为第一次跑作业时必须有一个Basetable 来和新增数据做 MERGE 操作。\n\n```\n#Create processed table first time as base table\nschema = StructType([ \\\n StructField(\"order_id\", IntegerType(), True), \\\n StructField(\"order_owner\", StringType(), True), \\\n StructField(\"order_value\", IntegerType(), True), \\\n StructField(\"timestamp\", TimestampType(), True), \\\n StructField(\"membership\", StringType(), True), \\\n StructField(\"year\", StringType(), True), \\\n StructField(\"month\", StringType(), True), \\\n StructField(\"day\", StringType(), True), \\\n StructField(\"hour\", StringType(), True) \\\n ])\n\nrdd = spark.sparkContext.emptyRDD()\n\ndf = spark.createDataFrame(rdd,schema)\n\ndf.write.partitionBy(\"year\", \"month\", \"day\", \"hour\").format(\"delta\").mode(\"overwrite\").save(\"s3://xxx-lake-streaming-demo/processed/\")\n```\n\n3.4 我们可以发送数据给到 Kafka order topic, 然后手动开启第一个作业,大概60秒后可以看到以数据已经成功写到了如下路径:s3://xxx-lake-streaming-demo/raw/year=22/month=04/day=04/。并且格式是 Delta format。我们可以看到 _delta_log 目录下面的json和parquet文件,这是 Delta Lake 实现 ACID 的事务日志目录。在创建新表时,Delta 将数据保存在一系列的 Parquet 文件中,并会在表的根目录创建 _delta_log 文件夹,其中包含 Delta Lake 的事务日志,ACID 事务日志里面记录了对应表的每次更改。具体原理可以参考:[https://databricks.com/blog/2019/08/21/diving-into-delta-lake-unpacking-the-transaction-log.html](https://databricks.com/blog/2019/08/21/diving-into-delta-lake-unpacking-the-transaction-log.html)\n\n\n\n\n\n在s3://xxx-lake-streaming-demo/raw/order/year=22/month=04/day=04/,可以看到以parquet格式的数据文件。\n\n\n\n3.5 紧接着启动第二个任务,这里的数据仍然是按照第一个raw_process job接收数据的时间做分区,看到关联数据被写入到 s3://xxx-lake-streaming-demo/curated/year=22/month=04/day=04/。\n\n当然实际场景我们可以通过even time或这个job本身的processing time根据业务需求来做分区。\n\n\n\n3.6 最后启动第三个任务,过了一会我们最新的订单会员数据被成功写到了如下目录:s3://delta-lake-streaming-demo/processed/year=22/month=04/day=04/。这里的数据是经过MERGE后的数据。现在我们停止给 Kafka topic 发送数据,过一会这个作业处理完所有订单后会自动停止,这也是 Spark 原生 trigger.once mode 特性实现一次性的流式处理,然后停止集群,避免了24*7运行成本。\n\n\n\n#### **步骤 4: Athena的配置**\n4.1 Athena支持以外部表的方式读取 Delta 表,我们需要生成manifest文件。具体步骤请参考:[https://docs.delta.io/latest/presto-integration.html](https://docs.delta.io/latest/presto-integration.html), 运行以下代码:\n\n```\ndeltaTable = DeltaTable.forPath(spark, \"s3://delta-lake-streaming-demo/processed/\")\ndeltaTable.generate(\"symlink_format_manifest\")\n\nspark.conf.set(\"delta.compatibility.symlinkFormatManifest.enabled\", \"true\")\n```\n\n可以看到生成了_symlink_format_manifest文件目录\n\n\n\n4.2 创建 Athena 表\n\n```\nCREATE EXTERNAL TABLE `processed`(\n `order_id` int,\n `order_owner` string,\n `order_value` int,\n `timestamp` timestamp,\n `membership` string)\nPARTITIONED BY (\n `year` string,\n `month` string,\n `day` string,\n `hour` string)\nROW FORMAT SERDE\n 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'\nSTORED AS INPUTFORMAT\n 'org.apache.hadoop.hive.ql.io.SymlinkTextInputFormat'\nOUTPUTFORMAT\n 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'\nLOCATION\n 's3://delta-lake-streaming-demo/processed/_symlink_format_manifest'\nTBLPROPERTIES (\n```\n\n4.3 查询processed这张 Delta 表, 成功返回 UPSERT 后的实时订单会员数据。\n\n\n\n#### **步骤 5: 数据湖上的编排和运维自动化**\nAmazon Managed Workflows of Apache Airflow (MWAA) 是一项托管编排服务 [Apache Airflow](https://airflow.apache.org/)。借助 Amazon MWAA,您可以使用 Airflow 和 Python 创建工作流程,而无需管理底层基础设施以实现可扩展性、可用性和安全性。亚马逊 MWAA 自动扩展其工作流程执行能力以满足您的需求,并与 Amazon 安全服务,帮助您快速安全地访问您的数据。\n\n5.1 MWAA 的部署可以参考具体文[link](https://docs.aws.amazon.com/zh_cn/mwaa/latest/userguide/create-environment.html)\n\n5.2 通过 MWAA 编排主要实现已下自动化功能\n\n- 每小时触发一次 job-stage3 流式作业;\n- 每小时从新生成 manifest 文件作业;\n- 每小时在 Athena 运行 MSCK REPAIR TABLE 作业以便从 Athena 查询新分区中的数据。应为在添加物理分区时,目录中的元数据将变得与文件系统中的数据布局不一致,需要将有关新分区的信息添加到目录中,要更新元数据;\n\n具体代码请参照[link](https://github.com/wei-zhong90/lego-poc-demo/blob/main/airflow/delta_optimization_pipeline.py)\n\n可以看到通过部署以上代码到 MWAA,通过 Airflow Web UI 我们的 Data Pipeline 会定时按小时运行以上三步作业:\n\n\n\n5.3 开源Delta Lake不提供Optimize功能,我们需要定时清理合并数据湖上小文件来提高query数据湖的性能。比如以下脚本我们会把小文件合并成10个最终文件,我们我们也可以灵活的选择优化整个表或优化某个分区。但由于Compaction对计算资源和下游操作有一定影响,建议用airflow来定时每月或周执行一次。\n\n```\n#### Compact the small files ####\npath = \"s3://xxx-poc-glue-wei/raw/\"\nnumFiles = 10\n\n(spark.read\n .format(\"delta\")\n .load(path)\n .repartition(numFiles)\n .write\n .option(\"dataChange\", \"false\")\n .format(\"delta\")\n .mode(\"overwrite\")\n .save(path))\n\n\n#### Compact a partition ####\npath = \"s3://xxx-poc-glue-wei/raw/\"\npartition = \"year = '22'\"\nnumFilesPerPartition = 10\n\n(spark.read\n .format(\"delta\")\n .load(path)\n .where(partition)\n .repartition(numFilesPerPartition)\n .write\n .option(\"dataChange\", \"false\")\n .format(\"delta\")\n .mode(\"overwrite\")\n .option(\"replaceWhere\", partition)\n .save(path))\n```\n\n5.4 我们还可以运行 Vacuum() 命令来删除旧的数据文件,因此您无需付费存储未压缩的数据。\n\n```\nfrom delta.tables import *\n\nBasetable = DeltaTable.forPath(sparkSession, BasePath) # path-based tables,\n\nBasetable.vacuum() # vacuum files not required by versions older than the default retention period\n\nBasetable.vacuum(100) # vacuum files not required by versions more than 100 hours old\n```\n\n步骤 6: QuickSight 展示\n\nAmazon QuickSight 是一项云规模的商业智能 (BI) 服务, 客户可以连接到各种数据源、设计或修改数据集和设计可视化分析、向同事发送通知以组合分析,以及发布报告和仪表板。在我们的Demo里,我们可以建立一个到Athena上的processed table的Dataset,然后可以快速的生成一些用户订单和会员的信息。\n\n\n\n### **总结**\n我们在这篇博客里谈及了关于利用 Delta Lake 和 Glue Streaming Job 来构建流式数据入湖的很多方面,其中包括如何通过 Terraform 集成 Delta Lake 和 Glue job, 利用 Spark 的 fair scheduler 让 Glue Job 同时处理两个 DAG, 应用 Stream-Stream Join 的功能关联流式数据,使用 Delta Lake 的 MERGE 命令允许我们实现 UPSERT 语义,使用 Spark 原生 trigger.once mode 特性实现一次性的流式处。与此同时,也系统的介绍了利用 MWAA 实现多个 glue job 的编排和定时触发,以及利用 Amazon Athena 和 Quicksight对delta table 里面的数据做交互式查询和可视化处理。\n\n由于篇幅的原因有很多细节我们也无法进行更进一步的探讨,但我们验证了在不直接依赖 Hadoop 集群或者 Databricks 的情况下,glue 的环境是能够定制化的实现 delta lake 以及原生 spark 里面的诸多功能,并且与此同时由于 glue 的 serverless 的特性,也使得这个方案天然具备了低管理运维成本的优势。一个完整的事务型数据湖需要具备的功能远不止于这篇博客里面介绍的内容,不过我们确实希望通过本文的介绍,能够让更多的人了解 Glue Streaming Job 的功能特性以及对 Delta Lake 的友好集成,并基于此完善出更多有意思的数据湖架构。\n\n### **参考资料**\n[https://spark.apache.org/docs/latest/job-scheduling.html](https://spark.apache.org/docs/latest/job-scheduling.html)\n\n[https://www.sigmoid.com/blogs/spark-streaming-internals/](https://www.sigmoid.com/blogs/spark-streaming-internals/)\n\n[https://aws.amazon.com/blogs/big-data/crafting-serverless-streaming-etl-jobs-with-aws-glue/](https://aws.amazon.com/blogs/big-data/crafting-serverless-streaming-etl-jobs-with-aws-glue/)\n\n[https://www.teradata.com/Blogs/Streaming-Data-Into-Teradata-Vantage-Using-Amazon-Managed-Kafka-MSK-Data-Streams-and-AWS-Glue-Stre](https://www.teradata.com/Blogs/Streaming-Data-Into-Teradata-Vantage-Using-Amazon-Managed-Kafka-MSK-Data-Streams-and-AWS-Glue-Stre)\n\n[https://docs.databricks.com/delta/delta-intro.html](https://docs.databricks.com/delta/delta-intro.html)\n\n[https://docs.delta.io/latest/presto-integration.html](https://docs.delta.io/latest/presto-integration.html)\n\n#### **本篇作者**\n\n\n\n**胡晓度**\nAmazon 解决方案架构师,负责跨国企业级客户基于 Amazon 的技术架构设计、咨询和设计优化工作。在加入 Amazon 之前曾就职于电商 Farfetch,海外政府 IT 部门和咨询相关企业,积累了丰富的大数据开发和数据库管理的实践经验。目前主要专注于大数据技术领域研究和 Amazon 云服务在国内和全球的应用和推广。\n\n\n\n**钟威**\n Amazon 解决方案架构师,负责跨国企业级客户基于 Amazon 的技术架构设计、咨询和设计优化工作。在加入 Amazon 之前曾就职于 Continental AG 和 Vitesco Technologies 汽车企业,积累了丰富的基础设施搭建和CICD pipeline 的实践经验。\n\n","render":"<h3><a id=\"_0\"></a><strong>数据湖的挑战</strong></h3>\n<p>伴随着云服务的流行,数据湖技术渐渐兴起,越来越多的企业开始搭建自己的数据湖。但传统数据湖基于文件,一般都是以追加的形式修改数据。当有数据需要改变时,经常需要读取全部内容重新写回到平台。基于 HDFS、S3 等传统数据湖方案,只能增加文件不方便修改文件中的内容。想要实现某条记录的 UPSERT(UPDATE 和 INSERT 的混合)变更,工程师需要构建复杂的 Pipeline 来读取整个分区或表,需要读取对应的文件并进行重写,这种Pipeline 效率很低,而且难以维护。另外,数据工程师经常遇到这样的问题:不安全地写入数据湖,这会导致如果读取数据过程中同时又有数据写入,那么将会产生垃圾数据。那么必须构建其他额外的方法,来保证数据同时读写情况的数据一致性。</p>\n<p>而在日常数据运维过程当中,往往又会遇到过多小文件的问题,特别是在流数据入湖的场景里,原始数据注入通常都会以 kilobytes 甚至是 bytes 级别大小的文件保存,这在后续当业务需要去 query 这些历史数据时,会极大的影响 query 的性能。所以运维数据湖平台时需要面对的一个最常见的场景就是需要在不影响业务的情况下,去清理合并那些小文件来提高 query 数据湖的性能。另外,如果具体业务场景对时延要求没有非常高,比如下游报表可以允许分钟甚至小时级别数据展示,那么就没有必要持续运行流式作业,针对这种成本敏感型的需求,应该有一种方式允许空闲计算资源自动停机。而针对这些场景,我们也会在这篇博客中给出一个合理的解决方法。</p>\n<p>本篇博客会使用开源 Delta Lake 结合 Amazon Glue, 简化构建数据湖的方式去解决上述问题。我们会带您一步一步地在 Amazon 上部署近实时的流式数据入湖的方案。包括从 Amazon MSK 当中读取流式数据,核对数据schema,使用 Amazon Glue 实现无服务器流式 ETL 作业,并且实现像关系型数据库一样的增删查改,保证 ACID。与此同时,我们还会使用 MWAA (Managed Workflow for Apache Airflow)来实现数据湖上运维自动化,包括性能的优化。最终在数据湖上实现海量数据 UPSERT 以及事务的管理能力,即事务型的数据湖。</p>\n<p>我们会使用一些模拟的业务库发过来的订单和会员信息作为流式数据的来源,使用MSK对接,然后通过 Glue Job 读取并向下游拥有UPSERT能力的数据湖(Delta Lake)进行同步并将这种有变更状态的数据存储于 Amazon S3,并通过 Amazon Athena 来提供实时数仓查询并通过 QuickSight 进行 Dashboard 展示。整套方案大部分是基于 Amazon 的托管服务,具有开箱即用,自动扩展,内置高可用性和按使用付费的计费模式,可提高敏捷性,优化成本同时减少数据运维的工作。</p>\n<h3><a id=\"_Delta_Lake__9\"></a><strong>开源 Delta Lake 简介</strong></h3>\n<p>开源 Delta Lake 是基于 Apache Spark 的下一代数据湖存储引擎,也是目前市面上主流的数据湖存储引擎之一。支持MERGE命令,可以高效的完成 UPSERT 语义。同时 Delta Lake 将 ACID 事务带入数据湖,提供了可序列化性,最强的隔离级别。Delta Lake 就是既能解决更新效率低下,又能进行并发读写控制,还支持时间回溯,查看历史任意时间的数据快照。也正是这些优越的特性,所以我们决定以开源 Delta Lake 为核心搭建数据湖。</p>\n<p>以下是 Dela Lake 的基本能力的一个总结:</p>\n<ol>\n<li>支持 UPSERT/DELETE:Delta Lake 将支持 MERGE、UPDATE 和 DELETE 的 DML 命令。可以轻松地在数据湖中插入和删除记录,并简化他们的变更数据捕获和满足GDPR。</li>\n<li>ACID 事务性:Delta Lake 在多个写操作之间提供 ACID 事务性。每一次写操作都是一个事务操作,事务日志(Transaction Log)中记录的写操作都有一个顺序序列。</li>\n<li>Schema 管理:Delta Lake 会自动验证正在写入的 Spark DataFrame 的 Schema 是否与表的 Schema 兼容。</li>\n<li>数据版本控制和时间旅行:Delta Lake 允许用户读取表或目录的历史版本快照。当文件在写入过程中被修改时,Delta Lake 会创建文件的新的版本并保留旧版本。当用户想要读取表或目录的较旧版本时,他们可以向 Apache Spark 的 read API 提供时间戳或版本号。</li>\n<li>可伸缩的元数据(Metadata)处理:Delta Lake 将表或目录的元数据信息存储在事务日志(Transaction Log)中,而不是元数据 Metastore 中。这使得 Delta Lake 够在固定时间内列出大目录中的文件,并且在读取数据时效率更高。</li>\n</ol>\n<h3><a id=\"_19\"></a><strong>解决方案架构</strong></h3>\n<p>由于篇幅有限,本篇博客主要是在验证使用开源 Delta Lake 在 Amazon 上构建事务型数据湖的可行性,而对于数据湖上跟事务不直接相关的特征,包括数据血缘,数据权限等,会暂时忽略。而本篇博客的实验环境会基于下图的架构搭建。其中,数据源方面,我们会使用 Python 的 Faker 库产生一些 dummy data,并将这些 dummy data注入到 Amazon MSK (托管型的Kafka集群),然后会使用带有 delta jar 包的 Glue ETL streaming job 来将数据从 Kafka 集群中取出,并做去重处理,存储在核心数据湖存储(S3)中,而在这里核心验证的概念就是当新的数据是去更新已有的数据列时,Delta Lake 会保证已经存储在数据湖中的数据得到相应的更新而不是简单的 append only。这种持续更新的数据最终我们也会通过Athena(托管的presto服务)query 来做一个展示,以证明数据持续的更新能够可靠的以近实时的效率在 BI 报表中展示。</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/b55ef35b0edc499aa34f2fb707d393f8_image.png\" alt=\"image.png\" /></p>\n<p>在这里还需要说明的是目前这个架构虽然是实时流式处理。但 glue streaming 本身就是基于 spark structured streaming 的引擎,其对于流的处理实际上是以微批的形式,那么这也就意味着截取微批的时间窗口会对数据的延迟性产生较大的影响,并且我们在第三个 Job 做 UPSERT 处理时,如果在同一个微批内出现多条反复更改同一条数据的事务,那么将只有那个微批内的最新的更改会出现在 processed 的表内,也意味着每个微批实际上只会记录下最新的更改。这也是为什么我们会主张在数据湖上分多个层级来收纳流式数据入湖。</p>\n<p>架构上 Job1 负责从 MSK 读取原始数据并且把数据以 Delta 的格式写入原始数据层(raw layer),同时我们会按 processing time 以年、月、天、小时来分区。数据在进入这一层前没有做数据清洗和处理,并允许重复订单和会员数据直接以 append only 的方式全量的录入数据湖保证 Single source of truth。我们为了模拟一个更加接近真实的业务景,Job2 从原始数据层读取数据,做了一些业务处理的逻辑和数据清洗,例如我们实现了 Stream-Stream Join (流关联)和字段的处理。最后通过 Job3 基于 Append Only 产生的 Delta table 做 MERGE 处理,实现 UPSERT 逻辑然后写入处理层(processed layer)的 ODS 表供下游消费端查询,这一层类似 ODS 层, 可以做进一步数据清洗和去重等业务逻辑。Job4 主要是用 Delta API 来生成 Manifest 文件便于 Athena 可以查询到 Delta table。</p>\n<h3><a id=\"_28\"></a><strong>环境搭建</strong></h3>\n<p>本博客使用东京区域进行搭建,但读者可自由选择区域,架构中所用到的组件已经在 Amazon 的大多数区域上线。</p>\n<h4><a id=\"_31\"></a><strong>前提条件</strong></h4>\n<ol>\n<li>具有管理员权限的 Amazon 账号</li>\n<li>本地安装有 <a href=\"https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html\" target=\"_blank\">Amazon CLI</a>,以及 <a href=\"https://www.terraform.io/downloads\" target=\"_blank\">terraform</a></li>\n<li>配置好 Amazon profile 的 access key, secret key (详细可参看<a href=\"https://docs.aws.amazon.com/cli/latest/userguide/cli-configure-files.html\" target=\"_blank\">link</a>)</li>\n</ol>\n<p>本博客假定读者都具备有基础的 Amazon 知识,并且熟悉 Amazon 服务的基本概念,有使用 Amazon 的经验。整个架构的实现代码可以参考<a href=\"https://github.com/wei-zhong90/deltalake-aws-poc-demo\" target=\"_blank\">link</a></p>\n<h4><a id=\"_1__39\"></a><strong>步骤 1: 网络环境</strong></h4>\n<p>由于架构中使用了 Amazon MSK (Managed Streaming for Apache Kafka),我们需要搭建一个 VPC 环境。而这里的VPC的网络选择可以根据自己的需要来,我们在这个实验环境里用到的 Kafka 由于不需要接收来自于 VPC 外部的流量,所以我们的 VPC 并不需要任何互联网访问的途径。整个 VPC 搭建比较简单,在这里也不再过多的赘述。为方便大家搭建起整个实验环境,我们也已将整个环境写成了 terraform code 来实现一键化部署。</p>\n<p>首先将代码下载至本地:</p>\n<pre><code class=\"lang-\">git clone git@github.com:wei-zhong90/deltalake-aws-poc-demo.git\ncd deltalake-aws-poc-demo/infrastructure\n</code></pre>\n<p><img src=\"https://dev-media.amazoncloud.cn/0e97bd7f77514b529713a103ac7aff7c_image.png\" alt=\"image.png\" /></p>\n<p>然后修改相应的参数:</p>\n<p>其中这四个参数分别代表:</p>\n<ul>\n<li>region: 环境部署的区域</li>\n<li>public_key: 之后会用来登录测试实例用的密钥对的公钥</li>\n<li>kafka_test_topic, kafka_test_topic_2分别代表着 Kafka 集群用来接收数据的两个 topic 的名字,可自定义这两个topic的名字</li>\n</ul>\n<p>在修改好相应参数后,便可执行以下代码进行部署:</p>\n<pre><code class=\"lang-\">terraform init\nterraform apply\n</code></pre>\n<p>这一部分的 terraform 代码会直接部署好一个 vpc,一个msk集群,一个测试用 linux 实例,以及三个后面会详细介绍的 glue streaming job。整个过程可能会需要花35分钟,主要是 MSK 的部署会需要消耗大量的时间。</p>\n<h4><a id=\"_2__69\"></a><strong>步骤 2: 启动订单和会员数据生成程序</strong></h4>\n<p>在整个部署完成以后,可以进入到 ec2 的控制台界面查看新生成的名为“msk-dev-workspace”的实例,如下图。</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/fbde0c9706764e4e9f543e7c753ad9b7_image.png\" alt=\"image.png\" /></p>\n<p>使用之前部署时配置的密匙对 ssh 进入该实例,在 HOME 路径下会看见一个 kafka 的 dir,这个实际上是 Kafka 的官方安装包,我们之后也会用这个安装包里面的工具来查看 MSK 集群里的数据。</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/76c93b01f4194ed4a1593bfb50be728c_image.png\" alt=\"image.png\" /></p>\n<p>接下来,我们需要启动订单数据生成程序,执行以下命令:</p>\n<pre><code class=\"lang-\">cd deltalake-aws-poc-demo\npython3 -m virtualenv .venv\nsource .venv/bin/activate\npython3 -m pip install -r requirements.txt\nvi .env\n</code></pre>\n<p><img src=\"https://dev-media.amazoncloud.cn/9f7956bc3c72447180e610a0f3ff2504_image.png\" alt=\"image.png\" /></p>\n<p>这个时候会进入到以下界面:</p>\n<p>在这里我们需要将这几个变量换成我们自己设定的几个值。首先,BOOTSTRAP_SERVERS 的值来自于之前部署好的 MSK 集群,我们可以进入到 MSK 的控制台进行查看,如下。</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/43e0d519d05e4f9daf1814d15486d5c5_image.png\" alt=\"image.png\" /></p>\n<p>我们会在 MSK 的控制台下看到一个新的 MSK 集群,名为 app;然后点进这个集群后就可以在右上角点击‘View client information’,就可以看到几种节点的连接链接,在这里我们需要复制 TLS 的链接,然后填到 BOOTSTRAP_SERVERS 的变量下面。而后面的几个变量, TOPIC, SECOND_TOPIC 则是我们之前在部署 terraform 代码时更改的那两个 topic 的变量名称,请务必注意保持一致。最后两个变量是用来控制订单数据生成的量和频率的,在这里可以不做更改。</p>\n<p>在完成更改以后,保存更改,即可执行一下指令,开始自动生成订单数据,并发送至 Kafka 集群。</p>\n<p><code>python3 generator.py</code></p>\n<p>在执行完这条指令后,一个简单的 python 程序就会开始向定义的那两个 topic 里面发送两种数据,一种是订单数据,一种则是会员等级变更数据,我们在之后的 glue 中就会对这两种数据进行收集和处理。</p>\n<p>在这里需要说明的是,这里生成的订单数据实际上只有六种订单,在下图中可以看到这六种订单实际上就是分属于6个不同的 order_id 及 order_owner,而不断生成的订单数据则是不断的更新这六种订单的 order_value 和 timestamp。另外一种会员等级变更数据则是针对这六个 order_owner 不断的更改他们的 membership 的等级。在实际场景中,订单数据并不会如此频繁的更改,会员等级更不会频繁变动,但在这个实验环境下,我们为了展示 Delta lake 的 Upsert 特性,就模拟了这种极端的情况。</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/1cc74f120da74074befafd67ab27741e_image.png\" alt=\"image.png\" /></p>\n<h4><a id=\"_3__Glue__108\"></a><strong>步骤 3: 配置 Glue 作业</strong></h4>\n<p>Amazon Glue 是一项完全托管,无服务器架构的 ETL 服务。客户无需预置基础设置,仅需由 Glue 负责预置、扩展 Spark 运行环境,客户只需要专注开发 ETL 代码,并且使用 Amazon Glue 时,只需为 ETL 作业运行时间付费。另外,Glue Streaming 基于开源 Spark Structured Streaming 构建,面向微批处理,继承了 Spark 的所有特性可以完全集成 Delta Lake。</p>\n<p>本步骤阐述了用 Amazon Glue 来搭建三个流式 ETL 作业的业务逻辑,具体 Glue 任务和代码都会通过 Terraform 来自动部署, 我们主要重点介绍Job的功能实现而不是 Job 的具体配置,Terraform 会创建如下三个Job:</p>\n<ul>\n<li>raw_process</li>\n<li>join_process</li>\n<li>upsert_process</li>\n</ul>\n<p>3.1 第一个 Job 负责从 MSK 读取原始数据并且把数据以 Delta 的格式写入原始数据层(raw layer),同时我们会按 processing time 以年、月、天、小时来分区。数据在进入这一层前没有做数据清洗和处理,并允许重复订单和会员数据,在实际生产中这一层也可以根据业务命名为 Staging Layer/Ingestion Layer/Landing Area。</p>\n<pre><code class=\"lang-\">import sys\nfrom awsglue.transforms import *\nfrom awsglue.utils import getResolvedOptions\nfrom pyspark.context import SparkContext\nfrom awsglue.context import GlueContext\nfrom pyspark.context import SparkConf\nfrom awsglue.job import Job\n# Import the packages\nfrom delta import *\nfrom pyspark.sql.session import SparkSession\nfrom datetime import datetime\n\nfrom pyspark.sql.types import StructType, StructField, StringType, IntegerType, TimestampType\nfrom pyspark.sql.functions import col, from_json, lit\n\nargs = getResolvedOptions(sys.argv, ['JOB_NAME', 'bucket_name', 'bootstrap_servers', 'topic1', 'topic2'])\ndata_bucket = args['bucket_name']\nbootstrap_servers = args['bootstrap_servers']\ntopic1 = args['topic1']\ntopic2 = args['topic2']\ncheckpoint_bucket1 = f"s3://{data_bucket}/checkpoint/"\ncheckpoint_bucket2 = f"s3://{data_bucket}/membership_checkpoint/"\n \nschema1 = StructType([ \\\n StructField("order_id", IntegerType(), True), \\\n StructField("order_owner", StringType(), True), \\\n StructField("order_value", IntegerType(), True), \\\n StructField("timestamp", TimestampType(), True), ])\n\nschema2 = StructType([ \\\n StructField("order_owner", StringType(), True), \\\n StructField("membership", StringType(), True), \\\n StructField("timestamp", TimestampType(), True), ])\n\ndef insertToDelta1(microBatch, batchId): \n date = datetime.today()\n year = date.strftime("%y")\n month = date.strftime("%m")\n day = date.strftime("%d")\n hour = date.strftime("%H")\n if microBatch.count() > 0:\n df = microBatch.withColumn("year", lit(year)).withColumn("month", lit(month)).withColumn("day", lit(day)).withColumn("hour", lit(hour))\n df.write.partitionBy("year", "month", "day", "hour").mode("append").format("delta").save(f"s3://{data_bucket}/raw/order/")\n\ndef insertToDelta2(microBatch, batchId):\n if microBatch.count() > 0:\n microBatch.write.partitionBy("order_owner").mode("append").format("delta").save(f"s3://{data_bucket}/raw/member/")\n\nclass JobBase(object):\n fair_scheduler_config_file= "fairscheduler.xml"\n def get_options(self, bootstrap_servers, topic):\n return {\n "kafka.bootstrap.servers": bootstrap_servers,\n "subscribe": topic,\n "kafka.security.protocol": "SASL_SSL",\n "kafka.sasl.mechanism": "AWS_MSK_IAM",\n "kafka.sasl.jaas.config": "software.amazon.msk.auth.iam.IAMLoginModule required;",\n "kafka.sasl.client.callback.handler.class": "software.amazon.msk.auth.iam.IAMClientCallbackHandler",\n "startingOffsets": "earliest",\n "maxOffsetsPerTrigger": 1000,\n "failOnDataLoss": "false"\n }\n def __start_spark_glue_context(self):\n conf = SparkConf().setAppName("python_thread").set('spark.scheduler.mode', 'FAIR').set("spark.scheduler.allocation.file", self.fair_scheduler_config_file)\n self.sc = SparkContext(conf=conf)\n self.glue_context = GlueContext(self.sc)\n self.spark = self.glue_context.spark_session\n def execute(self):\n self.__start_spark_glue_context()\n self.logger = self.glue_context.get_logger()\n self.logger.info("Starting Glue Threading job ")\n import concurrent.futures\n executor = concurrent.futures.ThreadPoolExecutor(max_workers=2)\n executor.submit(self.workflow, topic1, schema1, insertToDelta1, checkpoint_bucket1, 1)\n executor.submit(self.workflow, topic2, schema2, insertToDelta2, checkpoint_bucket2, 2)\n self.logger.info("Completed Threading job")\n \n \n def workflow(self, topic, schema, insertToDelta, checkpoint_bucket, poolname):\n \n self.sc.setLocalProperty("spark.scheduler.pool", str(poolname))\n # Read Source\n df = self.spark \\\n .readStream \\\n .format("kafka") \\\n .options(**self.get_options(bootstrap_servers, topic)) \\\n .load().select(col("value").cast("STRING"))\n\n df2 = df.select(from_json("value", schema).alias("data")).select("data.*")\n\n\n # Write data as a DELTA TABLE\n df3 = df2.writeStream \\\n .foreachBatch(insertToDelta) \\\n .option("checkpointLocation", checkpoint_bucket) \\\n .trigger(processingTime="60 seconds") \\\n .start()\n\n df3.awaitTermination()\n\ndef main():\n job = JobBase()\n job.execute()\n\n\nif __name__ == '__main__':\n main()\n</code></pre>\n<p>3.1.1 在代码里,由于订单及会员数据被分别发送至 kafka stream 里面的两个 topic,所以第一个用于收集原始订单和会员数据的 glue job 需要能够同时从两个 kafka topic 里面读取数据,然后并发分别写入两张 Delta 表,我们使用了 Python 多线程模块 concurrent.futures 和 ThreadPoolExecutor 类来并发调用两次 workflow function,在 workflow function 内首先读取 Kafka 的 Topic 并通过 IAM 认证方式读取流式加密的数据并转化数据为 STRING 格式:</p>\n<pre><code class=\"lang-\"> def workflow(self, topic, schema, insertToDelta, checkpoint_bucket, poolname):\n \n self.sc.setLocalProperty("spark.scheduler.pool", str(poolname))\n # Read Source\n df = self.spark \\\n .readStream \\\n .format("kafka") \\\n .options(**self.get_options(bootstrap_servers, topic)) \\\n .load().select(col("value").cast("STRING"))\n</code></pre>\n<p>3.1.2 通过 from_json 把 JSON string 转化为事先定义好的DataFrame StructType:</p>\n<pre><code class=\"lang-\">df2 = df.select(from_json("value", schema).alias("data")).select("data.*")\n</code></pre>\n<p>3.1.3 通过 Spark 资源调度 Fair Scheduler 的self.sc.setLocalProperty(“spark.scheduler.pool”, str(poolname)),我们可以提交 Job 到指定的 pool ,从而实现在一个 Glue Job 里资源的平等分配, 我们用到 foreachbatch API 去触发一个传入的insertToDelta function 参数,具体逻辑通过insertToDelta1 和 insertToDelta2 函数里按照每60秒的窗口把数据按照类似 Hive 分区方式,以 Processing time 的年、月、日、小时来写入到 S3上,例如InsertToDelta1:</p>\n<pre><code class=\"lang-\">def insertToDelta1(microBatch, batchId): \n date = datetime.today()\n year = date.strftime("%y")\n month = date.strftime("%m")\n day = date.strftime("%d")\n hour = date.strftime("%H")\n if microBatch.count() > 0:\n df = microBatch.withColumn("year", lit(year)).withColumn("month", lit(month)).withColumn("day", lit(day)).withColumn("hour", lit(hour))\n df.write.partitionBy("year", "month", "day", "hour").mode("append").format("delta").save(f"s3://{data_bucket}/raw/order/")\n</code></pre>\n<p>3.2 第二个作业,主要是用来实现一个订单和对应会员数据的流关联,我们假设想实时分析一个会员状态和下单之间的关系,就需要将两个流按用户名字进行 Join。流和流的关联目前不支持 update 模式, 所以我们还是以追加的形式把关联后的数据写入 curated 层。</p>\n<pre><code class=\"lang-\">import com.amazonaws.services.glue.{DynamicFrame, GlueContext}\nimport com.amazonaws.services.glue.errors.CallSite\nimport com.amazonaws.services.glue.util.{GlueArgParser, Job, JsonOptions}\nimport org.apache.spark.{SparkContext, SparkConf}\nimport org.apache.spark.sql.{Dataset, Row, SaveMode, SparkSession, DataFrame}\nimport org.apache.spark.sql.functions._\nimport org.apache.spark.sql.streaming.Trigger\nimport org.apache.spark.sql.types.{StructType, StructField, StringType, IntegerType, DoubleType, BooleanType, TimestampType}\nimport org.apache.spark.sql.streaming.{StreamingQuery, Trigger}\nimport scala.collection.JavaConverters._\nimport io.delta.tables.DeltaTable\nimport org.apache.spark.sql.expressions.Window\n\nimport scala.collection.JavaConverters._\n\n\nobject GlueApp {\n def main(sysArgs: Array[String]): Unit = {\n \n val spark: SparkContext = new SparkContext()\n val glueContext: GlueContext = new GlueContext(spark)\n val sparkSession: SparkSession = glueContext.getSparkSession\n import sparkSession.implicits._\n // @params: [JOB_NAME]\n val args = GlueArgParser.getResolvedOptions(sysArgs, Seq("JOB_NAME", "bucket_name").toArray)\n Job.init(args("JOB_NAME"), glueContext, args.asJava)\n\n val CheckpointDir = s"s3://${args("bucket_name")}/checkpoint2"\n\n val raworder = sparkSession.readStream.format("delta").load(s"s3://${args("bucket_name")}/raw/order/").withWatermark("timestamp", "3 hours")\n val rawmember= sparkSession.readStream.format("delta").load(s"s3://${args("bucket_name")}/raw/member/").withWatermark("timestamp", "2 hours")\n\n val joinedorder = raworder.alias("order").join(\n rawmember.alias("member"),\n expr("""\n order.order_owner = member.order_owner AND\n order.timestamp >= member.timestamp AND\n order.timestamp <= member.timestamp + interval 1 hour\n """)\n ).select($"order.order_id", $"order.order_owner", $"order.order_value", $"order.timestamp", $"member.membership", $"order.year", $"order.month", $"order.day", $"order.hour")\n\n\n val query = joinedorder\n .writeStream\n .format("delta")\n .option("checkpointLocation", CheckpointDir)\n .trigger(Trigger.ProcessingTime("60 seconds"))\n .outputMode("append")\n .partitionBy("year", "month", "day", "hour")\n .start(s"s3://${args("bucket_name")}/curated/")\n\n query.awaitTermination() \n \n Job.commit()\n\n }\n\n}\n</code></pre>\n<p>3.2.1 流之间关联和静态数据之间的关联有一个不同,对流来说任何时候关联双方的数据都是没有边界的,也叫无界流,当前流上的任何一行数据都有可能和另一条流上未来的一行数据关联上,所以我们需要制定一个时间范围。首先我们分别给订单和会员流设定 Watermark(水位线),用来抛弃超过约定时间到达的输入数据,订单最多允许迟到三小时,会员最多允许迟到两小时。</p>\n<pre><code class=\"lang-\">val raworder = sparkSession.readStream.format("delta").load(s"s3://${args("bucket_name")}/raw/order/").withWatermark("timestamp", "3 hours")\n val rawmember = sparkSession.readStream.format("delta").load(s"s3://${args("bucket_name")}/raw/member/").withWatermark("timestamp", "2 hours")\n</code></pre>\n<p>3.2.2 另外,我们定义跨两个流的 event time 约束,以便可以确定何时不需要一个输入流与另一个输入流匹配。我们用时间范围关联条件(join condition)定义此约束。比如说,在我们场景里假设会员的状态变化可以转化为订单的生成,所以订单可以在相应的会员状态变化后 0 秒到 1 小时的时间范围内发生。如下是约束的逻辑:</p>\n<pre><code class=\"lang-\">val joinedorder = raworder.alias("order").join(\n rawmember.alias("member"),\n expr("""\n order.order_owner = member.order_owner AND\n order.timestamp >= member.timestamp AND\n order.timestamp <= member.timestamp + interval 1 hour\n """)\n</code></pre>\n<p>3.3 第三个作业从原始数据层读取数据,然后进行数据清洗,实现 UPSERT 逻辑然后写入处理层(processed layer),这一层类似 ODS 层, 可以做数据清洗和去从等业务逻辑。同时,我们使用 Spark 原生的trigger.once mode 实现一次性的流式处理,这样的配置能够允许 glue streaming job 在 kafka stream 里面的新增数据处理完之后自动停止,以避免了24*7运行成本。另外,本篇博客以主要以介绍实现 UPSERT 场景为主,在实际生产中,后面还会有类似 EDW、DM 或 DWD、DWS、ADS 等数据湖上的分层和一些 Delta Lake 高级功能例如窗口聚合, 流批一体等。</p>\n<pre><code class=\"lang-\">import com.amazonaws.services.glue.{DynamicFrame, GlueContext}\nimport com.amazonaws.services.glue.errors.CallSite\nimport com.amazonaws.services.glue.util.{GlueArgParser, Job, JsonOptions}\nimport org.apache.spark.{SparkContext, SparkConf}\nimport org.apache.spark.sql.{Dataset, Row, SaveMode, SparkSession, DataFrame}\nimport org.apache.spark.sql.functions._\nimport org.apache.spark.sql.streaming.Trigger\nimport org.apache.spark.sql.types.{StructType, StructField, StringType, IntegerType, DoubleType, BooleanType, TimestampType}\nimport org.apache.spark.sql.streaming.{StreamingQuery, Trigger}\nimport scala.collection.JavaConverters._\nimport io.delta.tables.DeltaTable\nimport org.apache.spark.sql.expressions.Window\n\nimport scala.collection.JavaConverters._\n\n\nobject GlueApp {\n def main(sysArgs: Array[String]): Unit = {\n \n val spark: SparkContext = new SparkContext()\n val glueContext: GlueContext = new GlueContext(spark)\n val sparkSession: SparkSession = glueContext.getSparkSession\n import sparkSession.implicits._\n // @params: [JOB_NAME]\n val args = GlueArgParser.getResolvedOptions(sysArgs, Seq("JOB_NAME", "bucket_name").toArray)\n Job.init(args("JOB_NAME"), glueContext, args.asJava)\n \n //read base\n val BasePath = s"s3://${args("bucket_name")}/processed"\n val Basetable = DeltaTable.forPath(sparkSession, BasePath)\n val CheckpointDir = s"s3://${args("bucket_name")}/checkpoint3"\n //read from upstream joined stream\n val raw = sparkSession.readStream.format("delta").load(s"s3://${args("bucket_name")}/curated/")\n \n def upsertIntoDeltaTable(updatedDf: DataFrame, batchId: Long): Unit = {\n \n val w = Window.partitionBy($"order_id").orderBy($"timestamp".desc)\n val Resultdf = updatedDf.withColumn("rownum", row_number.over(w)).where($"rownum" === 1).drop("rownum")\n \n // Merge from base with source\n Basetable.alias("b").merge(\n Resultdf.alias("s"),\n "s.order_id = b.order_id")\n .whenMatched.updateAll()\n .whenNotMatched.insertAll()\n .execute()\n }\n\n\n val query = raw\n .writeStream\n .format("delta")\n .foreachBatch(upsertIntoDeltaTable _)\n .option("checkpointLocation", CheckpointDir)\n .trigger(Trigger.Once())\n .outputMode("update")\n .start(s"s3://${args("bucket_name")}/processed/")\n\n query.awaitTermination() \n \n \n Job.commit()\n\n }\n\n}\n</code></pre>\n<p>3.3.1 在代码里,作业会消费从上次工作完成后的新增订单和会员关联后的数据,Trigger.Once()会把所有数据处理完后自动停止Glue作业,非常经济高效。另外,这里由于我们订单和会员是源源不断的写入到 raw 层,会产生非常多的重复订单号, 所以我们需要在每个foreachbatch 里通过一个机制去拿到 Streaming DataFrame,即传给 upsertIntoDeltaTable 函数每一批updatedDF DataFrame 里最新的那个关联后的记录。首先,我们是通过 <strong>SQL PARTITION BY</strong> 配合 <strong>OVER</strong> 的方式,通过给 order_id 分组并给 timestamp 排序拿到最新的时间戳, 也就是 rownum = 1的那条订单记录。然后,通过 Delta Merge API 来实现 Resultdf 和 Basetable 的 UPSERT 操作,注意 Basetable 是从 curated 层读取的 Delta 表,第一次需要手动建一个空表,后面3.3会提到。最后通过 trigger(Trigger.Once())的方式通过 delta API 写入到S3的 processed 层更新 Delta 表。</p>\n<pre><code class=\"lang-\">def upsertIntoDeltaTable(updatedDf: DataFrame, batchId: Long): Unit = {\n val w = Window.partitionBy($"order_id").orderBy($"timestamp".desc)\n val Resultdf = updatedDf.withColumn("rownum", row_number.over(w)).where($"rownum" === 1).drop("rownum")\n // Merge from base with source\n Basetable.alias("b").merge(\n Resultdf.alias("s"), \n "s.order_id = b.order_id")\n .whenMatched.updateAll()\n .whenNotMatched.insertAll()\n .execute()\n }\n</code></pre>\n<p>3.3.2 最后我们还需要在 processed 层创建一个的初始表,里面没有数据。因为第一次跑作业时必须有一个Basetable 来和新增数据做 MERGE 操作。</p>\n<pre><code class=\"lang-\">#Create processed table first time as base table\nschema = StructType([ \\\n StructField("order_id", IntegerType(), True), \\\n StructField("order_owner", StringType(), True), \\\n StructField("order_value", IntegerType(), True), \\\n StructField("timestamp", TimestampType(), True), \\\n StructField("membership", StringType(), True), \\\n StructField("year", StringType(), True), \\\n StructField("month", StringType(), True), \\\n StructField("day", StringType(), True), \\\n StructField("hour", StringType(), True) \\\n ])\n\nrdd = spark.sparkContext.emptyRDD()\n\ndf = spark.createDataFrame(rdd,schema)\n\ndf.write.partitionBy("year", "month", "day", "hour").format("delta").mode("overwrite").save("s3://xxx-lake-streaming-demo/processed/")\n</code></pre>\n<p>3.4 我们可以发送数据给到 Kafka order topic, 然后手动开启第一个作业,大概60秒后可以看到以数据已经成功写到了如下路径:s3://xxx-lake-streaming-demo/raw/year=22/month=04/day=04/。并且格式是 Delta format。我们可以看到 _delta_log 目录下面的json和parquet文件,这是 Delta Lake 实现 ACID 的事务日志目录。在创建新表时,Delta 将数据保存在一系列的 Parquet 文件中,并会在表的根目录创建 _delta_log 文件夹,其中包含 Delta Lake 的事务日志,ACID 事务日志里面记录了对应表的每次更改。具体原理可以参考:<a href=\"https://databricks.com/blog/2019/08/21/diving-into-delta-lake-unpacking-the-transaction-log.html\" target=\"_blank\">https://databricks.com/blog/2019/08/21/diving-into-delta-lake-unpacking-the-transaction-log.html</a></p>\n<p><img src=\"https://dev-media.amazoncloud.cn/9bc1e3bf1b364e468542956a57928f75_image.png\" alt=\"image.png\" /></p>\n<p>在s3://xxx-lake-streaming-demo/raw/order/year=22/month=04/day=04/,可以看到以parquet格式的数据文件。</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/3ace6fdd47674f48b2f18c61ccee29cb_image.png\" alt=\"image.png\" /></p>\n<p>3.5 紧接着启动第二个任务,这里的数据仍然是按照第一个raw_process job接收数据的时间做分区,看到关联数据被写入到 s3://xxx-lake-streaming-demo/curated/year=22/month=04/day=04/。</p>\n<p>当然实际场景我们可以通过even time或这个job本身的processing time根据业务需求来做分区。</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/5291ca0288244458a5bc64408b87f71f_image.png\" alt=\"image.png\" /></p>\n<p>3.6 最后启动第三个任务,过了一会我们最新的订单会员数据被成功写到了如下目录:s3://delta-lake-streaming-demo/processed/year=22/month=04/day=04/。这里的数据是经过MERGE后的数据。现在我们停止给 Kafka topic 发送数据,过一会这个作业处理完所有订单后会自动停止,这也是 Spark 原生 trigger.once mode 特性实现一次性的流式处理,然后停止集群,避免了24*7运行成本。</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/50a14aa4df754f758e271b0441b8bdd5_image.png\" alt=\"image.png\" /></p>\n<h4><a id=\"_4_Athena_474\"></a><strong>步骤 4: Athena的配置</strong></h4>\n<p>4.1 Athena支持以外部表的方式读取 Delta 表,我们需要生成manifest文件。具体步骤请参考:<a href=\"https://docs.delta.io/latest/presto-integration.html\" target=\"_blank\">https://docs.delta.io/latest/presto-integration.html</a>, 运行以下代码:</p>\n<pre><code class=\"lang-\">deltaTable = DeltaTable.forPath(spark, "s3://delta-lake-streaming-demo/processed/")\ndeltaTable.generate("symlink_format_manifest")\n\nspark.conf.set("delta.compatibility.symlinkFormatManifest.enabled", "true")\n</code></pre>\n<p>可以看到生成了_symlink_format_manifest文件目录</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/b5090b33488540fabdc4f7d37aec7b51_image.png\" alt=\"image.png\" /></p>\n<p>4.2 创建 Athena 表</p>\n<pre><code class=\"lang-\">CREATE EXTERNAL TABLE `processed`(\n `order_id` int,\n `order_owner` string,\n `order_value` int,\n `timestamp` timestamp,\n `membership` string)\nPARTITIONED BY (\n `year` string,\n `month` string,\n `day` string,\n `hour` string)\nROW FORMAT SERDE\n 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'\nSTORED AS INPUTFORMAT\n 'org.apache.hadoop.hive.ql.io.SymlinkTextInputFormat'\nOUTPUTFORMAT\n 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'\nLOCATION\n 's3://delta-lake-streaming-demo/processed/_symlink_format_manifest'\nTBLPROPERTIES (\n</code></pre>\n<p>4.3 查询processed这张 Delta 表, 成功返回 UPSERT 后的实时订单会员数据。</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/a791436d529343728374b1cae88efd81_image.png\" alt=\"image.png\" /></p>\n<h4><a id=\"_5__517\"></a><strong>步骤 5: 数据湖上的编排和运维自动化</strong></h4>\n<p>Amazon Managed Workflows of Apache Airflow (MWAA) 是一项托管编排服务 <a href=\"https://airflow.apache.org/\" target=\"_blank\">Apache Airflow</a>。借助 Amazon MWAA,您可以使用 Airflow 和 Python 创建工作流程,而无需管理底层基础设施以实现可扩展性、可用性和安全性。亚马逊 MWAA 自动扩展其工作流程执行能力以满足您的需求,并与 Amazon 安全服务,帮助您快速安全地访问您的数据。</p>\n<p>5.1 MWAA 的部署可以参考具体文<a href=\"https://docs.aws.amazon.com/zh_cn/mwaa/latest/userguide/create-environment.html\" target=\"_blank\">link</a></p>\n<p>5.2 通过 MWAA 编排主要实现已下自动化功能</p>\n<ul>\n<li>每小时触发一次 job-stage3 流式作业;</li>\n<li>每小时从新生成 manifest 文件作业;</li>\n<li>每小时在 Athena 运行 MSCK REPAIR TABLE 作业以便从 Athena 查询新分区中的数据。应为在添加物理分区时,目录中的元数据将变得与文件系统中的数据布局不一致,需要将有关新分区的信息添加到目录中,要更新元数据;</li>\n</ul>\n<p>具体代码请参照<a href=\"https://github.com/wei-zhong90/lego-poc-demo/blob/main/airflow/delta_optimization_pipeline.py\" target=\"_blank\">link</a></p>\n<p>可以看到通过部署以上代码到 MWAA,通过 Airflow Web UI 我们的 Data Pipeline 会定时按小时运行以上三步作业:</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/ab6ae180510e4bedbc7a96c751b4734c_image.png\" alt=\"image.png\" /></p>\n<p>5.3 开源Delta Lake不提供Optimize功能,我们需要定时清理合并数据湖上小文件来提高query数据湖的性能。比如以下脚本我们会把小文件合并成10个最终文件,我们我们也可以灵活的选择优化整个表或优化某个分区。但由于Compaction对计算资源和下游操作有一定影响,建议用airflow来定时每月或周执行一次。</p>\n<pre><code class=\"lang-\">#### Compact the small files ####\npath = "s3://xxx-poc-glue-wei/raw/"\nnumFiles = 10\n\n(spark.read\n .format("delta")\n .load(path)\n .repartition(numFiles)\n .write\n .option("dataChange", "false")\n .format("delta")\n .mode("overwrite")\n .save(path))\n\n\n#### Compact a partition ####\npath = "s3://xxx-poc-glue-wei/raw/"\npartition = "year = '22'"\nnumFilesPerPartition = 10\n\n(spark.read\n .format("delta")\n .load(path)\n .where(partition)\n .repartition(numFilesPerPartition)\n .write\n .option("dataChange", "false")\n .format("delta")\n .mode("overwrite")\n .option("replaceWhere", partition)\n .save(path))\n</code></pre>\n<p>5.4 我们还可以运行 Vacuum() 命令来删除旧的数据文件,因此您无需付费存储未压缩的数据。</p>\n<pre><code class=\"lang-\">from delta.tables import *\n\nBasetable = DeltaTable.forPath(sparkSession, BasePath) # path-based tables,\n\nBasetable.vacuum() # vacuum files not required by versions older than the default retention period\n\nBasetable.vacuum(100) # vacuum files not required by versions more than 100 hours old\n</code></pre>\n<p>步骤 6: QuickSight 展示</p>\n<p>Amazon QuickSight 是一项云规模的商业智能 (BI) 服务, 客户可以连接到各种数据源、设计或修改数据集和设计可视化分析、向同事发送通知以组合分析,以及发布报告和仪表板。在我们的Demo里,我们可以建立一个到Athena上的processed table的Dataset,然后可以快速的生成一些用户订单和会员的信息。</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/71ee9f7f1bbe495791a07ddfd14e8e6a_image.png\" alt=\"image.png\" /></p>\n<h3><a id=\"_588\"></a><strong>总结</strong></h3>\n<p>我们在这篇博客里谈及了关于利用 Delta Lake 和 Glue Streaming Job 来构建流式数据入湖的很多方面,其中包括如何通过 Terraform 集成 Delta Lake 和 Glue job, 利用 Spark 的 fair scheduler 让 Glue Job 同时处理两个 DAG, 应用 Stream-Stream Join 的功能关联流式数据,使用 Delta Lake 的 MERGE 命令允许我们实现 UPSERT 语义,使用 Spark 原生 trigger.once mode 特性实现一次性的流式处。与此同时,也系统的介绍了利用 MWAA 实现多个 glue job 的编排和定时触发,以及利用 Amazon Athena 和 Quicksight对delta table 里面的数据做交互式查询和可视化处理。</p>\n<p>由于篇幅的原因有很多细节我们也无法进行更进一步的探讨,但我们验证了在不直接依赖 Hadoop 集群或者 Databricks 的情况下,glue 的环境是能够定制化的实现 delta lake 以及原生 spark 里面的诸多功能,并且与此同时由于 glue 的 serverless 的特性,也使得这个方案天然具备了低管理运维成本的优势。一个完整的事务型数据湖需要具备的功能远不止于这篇博客里面介绍的内容,不过我们确实希望通过本文的介绍,能够让更多的人了解 Glue Streaming Job 的功能特性以及对 Delta Lake 的友好集成,并基于此完善出更多有意思的数据湖架构。</p>\n<h3><a id=\"_593\"></a><strong>参考资料</strong></h3>\n<p><a href=\"https://spark.apache.org/docs/latest/job-scheduling.html\" target=\"_blank\">https://spark.apache.org/docs/latest/job-scheduling.html</a></p>\n<p><a href=\"https://www.sigmoid.com/blogs/spark-streaming-internals/\" target=\"_blank\">https://www.sigmoid.com/blogs/spark-streaming-internals/</a></p>\n<p><a href=\"https://aws.amazon.com/blogs/big-data/crafting-serverless-streaming-etl-jobs-with-aws-glue/\" target=\"_blank\">https://aws.amazon.com/blogs/big-data/crafting-serverless-streaming-etl-jobs-with-aws-glue/</a></p>\n<p><a href=\"https://www.teradata.com/Blogs/Streaming-Data-Into-Teradata-Vantage-Using-Amazon-Managed-Kafka-MSK-Data-Streams-and-AWS-Glue-Stre\" target=\"_blank\">https://www.teradata.com/Blogs/Streaming-Data-Into-Teradata-Vantage-Using-Amazon-Managed-Kafka-MSK-Data-Streams-and-AWS-Glue-Stre</a></p>\n<p><a href=\"https://docs.databricks.com/delta/delta-intro.html\" target=\"_blank\">https://docs.databricks.com/delta/delta-intro.html</a></p>\n<p><a href=\"https://docs.delta.io/latest/presto-integration.html\" target=\"_blank\">https://docs.delta.io/latest/presto-integration.html</a></p>\n<h4><a id=\"_606\"></a><strong>本篇作者</strong></h4>\n<p><img src=\"https://dev-media.amazoncloud.cn/2d0a71c7deb64439a2607163f38a68f1_image.png\" alt=\"image.png\" /></p>\n<p><strong>胡晓度</strong><br />\nAmazon 解决方案架构师,负责跨国企业级客户基于 Amazon 的技术架构设计、咨询和设计优化工作。在加入 Amazon 之前曾就职于电商 Farfetch,海外政府 IT 部门和咨询相关企业,积累了丰富的大数据开发和数据库管理的实践经验。目前主要专注于大数据技术领域研究和 Amazon 云服务在国内和全球的应用和推广。</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/769f948776dc4d1e9a786cf4b2c0b761_image.png\" alt=\"image.png\" /></p>\n<p><strong>钟威</strong><br />\nAmazon 解决方案架构师,负责跨国企业级客户基于 Amazon 的技术架构设计、咨询和设计优化工作。在加入 Amazon 之前曾就职于 Continental AG 和 Vitesco Technologies 汽车企业,积累了丰富的基础设施搭建和CICD pipeline 的实践经验。</p>\n"}
Amazon Glue 集成 Delta Lake 构建事务型数据湖上的流式处理

 0
0 0
0亚马逊云科技解决方案 基于行业客户应用场景及技术领域的解决方案
联系亚马逊云科技专家
亚马逊云科技解决方案
基于行业客户应用场景及技术领域的解决方案
联系专家

0
目录

 分享
分享 点赞
点赞 收藏
收藏 目录
目录立即注册,开启您的免费套餐
立即关注

亚马逊云开发者
公众号

User Group
公众号

亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
关于我们 
更多资源
开发者工具
更多支持
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
