{"value":"#### **Tuning Apache Kafka and Confluent Platform for Graviton2 using [Amazon Corretto](https://aws.amazon.com/corretto)**\n*By Guest Blogger [Liz Fong-Jones, Principal Developer Advocate, Honeycomb.io](https://www.honeycomb.io/teammember/liz-fong-jones/)*\n\n##### **Background**\nHoneycomb is a leading observability platform used by high-performance engineering teams to quickly visualize, analyze, and improve cloud application quality and performance. We utilize the OpenTelemetry standard to ingest data from our clients, including those hosted on AWS and using the AWS Distribution of OpenTelemetry. Once data is optionally pre-sampled within client [Amazon Virtual Private Clouds (Amazon VPC)](https://aws.amazon.com/vpc/), it flows to Honeycomb for analysis, resulting in a data volume of millions of trace spans per second passing through our systems.\n\nTo make sure of the durability and reliability of processing across software upgrades, spot instance retirements, and other continuous chaos, we utilize Application Load Balancers (ALBs) to route traffic to stateless ingest workers which publish the data into a pub-sub or message queuing system. Then, we read from this system to consume any telemetry added since the last checkpoint, decoupling the ingest process and allowing for indexing to be paused and restarted. For the entire history of Honeycomb dating back to 2016, we have used variants of the Apache Kafka software to perform this crucial pub-sub role.\n\n##### **Factors in Kafka performance**\nAfter having [chosen im4gn.4xlarge instances](https://www.honeycomb.io/blog/scaling-kafka-observability-pipelines/) for our Kafka brokers, we were curious how much further we could push the already excellent performance that we were seeing. Although it’s true that Kafka and other JVM workloads “just work” on ARM without modification in a majority of cases, a little bit of fine-tuning and polish can really pay off.\n\nTo understand the critical factors underlying the performance of our Kafka brokers, let’s recap what Kafka brokers do in general, as well as what additional features our specific Kafka distribution contains.\n\nApache Kafka is written in a mix of Scala and Java, with some JNI-wrapped C libraries for performance-sensitive code, such as ZSTD compression. A Kafka broker serializes and batches incoming data coming from producers or replicated from its peers, serves data to its peers to allow for replication, and responds to requests to consume recently produced data. Furthermore, it manages the data lifecycle and ages out expired segments, tracks consumer group offsets, and manages metadata in collaboration with a fleet of Zookeeper nodes.\n\nAs explained in the im4gn post, we use Confluent Enterprise Platform (a distribution of Apache Kafka customized by Confluent) to tier older data to [Amazon Simple Storage Service (Amazon S3)](https://aws.amazon.com/s3/) to free up space on the local NVMe SSDs. This additional workload introduces the overhead of high-throughput HTTPS streams, rather than just the Kafka internal protocols and disk serialization.\n\n##### **Profiling the Kafka broker**\nImmediately after switching to im4gn instances from i3en, we saw 40% peak CPU utilization, 15% off-peak CPU utilization, and utilized 30% of disk at peak (15% off-peak). We were hoping to keep these two utilization numbers roughly in line with each other to maximize the usage of our instances and keep cost economics under control. By using [Async Profiler](https://github.com/jvm-profiling-tools/async-profiler) for short runs, and later [Pyroscope](https://github.com/pyroscope-io/pyroscope-java) to continuously verify our results, we could see where in the broker’s code CPU time was being spent and identify wasteful usage.\n\nThe first thing that jumped out at us was the 20% of time being spent doing [zstd in JNI](https://github.com/luben/zstd-jni).\n\nWe hypothesized that we could obtain modest improvements from updating the ZSTD JNI JAR from the 1.5.0-x bundled with Confluent’s distro to a more recent 1.5.2-x version.\n\nHowever, our most significant finding from profiling was the significant time (12% of consumed CPU) being spent in com/sun/crypto/provider/GaloisCounterMode.encryptFinal, as part of the kafka/tier/store/S3TierObjectStore.putFile Confluent Tiered Storage process (28.4% of total broker consumed CPU in total). This was surprising, as we hadn’t seen this high of an overhead on the i3en instances, and others who ran vanilla Kafka on ARM had seen comparable CPU profiles to x86.\n\nAt this point, we began our collaboration with the Corretto team at AWS, which has been working to improve the performance of JVM applications on Graviton. Yishai reached out and asked if we were interested in trying the Corretto team’s branch that supplies ARM AES CTR intrinsic, because it’s a hot codepath used by TLS.\n\nAfter upgrading to the branch build of the JDK, and enabling\n```\n-XX:+UnlockDiagnosticVMOptions -XX:+UseAESCTRIntrinsics\n```\n\nin our extra JVM flags, we saw a significant performance improvement with profiling showing that com/sun/crypto/provider/GaloisCounterMode.encryptFinal is only taking 0.4% of time (with an additional 1% each in ghash_processBlocks_wide and counterMode_AESCrypt attributed to unknown_Java). This makes the total cost of the kafka/tier/store/S3TierObjectStore.putFile workload now only 16.4% — a reduction of 12% of total broker consumed CPU for tiering.\n\nWe don’t currently use TLS between Kafka brokers or clients, otherwise the savings would likely have been even greater. Speculating, this almost certainly lowers to ~1% overhead of the performance cost of enabling TLS between brokers, which we otherwise might have been hesitant to do due to the large penalty.\n\n#### **Show me the pictures and graphs!**\nBefore any experimentation:\n\n\n\nAfter applying UseAESCTRIntrinsics:\n\n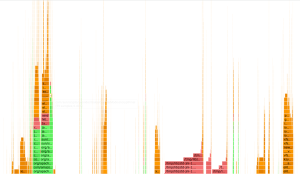\n\n\n\t\nThis result was clearly better. However, running a bleeding edge JVM build was not a great long-term approach for our production workload, and it wouldn’t necessarily make sense to ask all of the Confluent customers or all of the JVM or Kafka workloads to switch to using the latest Corretto JVM to generalize our results in the future. Furthermore, there was another problem not solved by the\n```\nUseAESCTRIntrinsics\n```\n\npatch: MD5 checksum time.\n\n##### **Enter [AWS Corretto](https://aws.amazon.com/corretto) Crypto Provider**\nAfter addressing TLS/AES overhead, the remaining work left to do was fix the 9.5% of CPU time being spent calculating MD5 (which is also part of the process of doing an Amazon S3 upload). The best solution here would be to not perform the MD5 digest at all (since Amazon S3 removed the requirement for Content-MD5 header). Today, TLS already includes HMAC stream check summing, and if bits are changing on the disk, then we have bigger problems regardless of whether tiering is happening. The Confluent team is working on allowing for MD5 opt-out. Meanwhile, we wanted something that could address both TLS/AES overhead and MD5 overhead, all without having to patch the JVM.\n\nThe [AWS Corretto Crypto Provider](https://github.com/corretto/amazon-corretto-crypto-provider) is a Java security API provider that implements digest and encryption algorithms with compiled C/JNI wrapped code. Although official binaries aren’t yet supplied for ARM, it was easy to grab a spare Graviton2 instance and compile a build, then set it as the -Djava.security.properties provider in the Kafka startup scripts. With ACCP enabled, only 1.8% of time is spent in AESGCM (better than the 0.4%+1%+1% = 2.4% seen with\n```UseAESCTRIntrinsics```), and only 4.7% of time is spent in MD5 (better than the 9.5% we previously saw).\n\n\n\nThis means that the total overhead of Kafka/tier/store/S3TierObjectStore.putFile is now 12-14% rather than 28% (about half what it was before).\n\nWe felt ready to fully deploy this result across all of our production workloads and leave it live, knowing that we could still benefit from future rolling Corretto official releases with JVM flags set to production, non-experimental values.\n\n##### **The future of Kafka and ARM at Honeycomb**\nAlthough we’re satisfied after tuning with the behavior of our fleet of six im4gn.2xlarge instances for serving our workload of 2M messages per second, we decided to preemptively scale up our fleet to nine brokers. The rationale had nothing to do with CPU performance. Instead, we were concerned after repeated weekly broker termination chaos engineering experiments about the network throughput required during peak hours to survive the loss of a single broker and re-replicate all of the data in a timely fashion\n\nBy spreading the 3x duplicated data across nine brokers, only one third of all of the data, rather than half of all of the data, would need to be re-replicated in the event of broker loss, and the replacement broker would have eight healthy peers to read from, rather than five. Increasing capacity by 50% halved the time required to fully restore in-service replica quorum at peak weekday traffic from north of six hours to less than three hours.\n\nThis change is just one of a series of many small changes that we’ve made to optimize and tune our AWS workload at Honeycomb. In the coming weeks, we hope to share how, without any impact on customer-visible performance, we decommissioned 100% of our Intel EC2 instances and 85% of our Intel [AWS Lambda](https://aws.amazon.com/lambda/) functions in our fleet for a net cost and energy savings.\n\n\n\n**Liz Fong-Jones**\nLiz Fong-Jones is a developer advocate, labor and ethics organizer, and Site Reliability Engineer (SRE) with 16+ years of experience. She is an advocate at Honeycomb.io for the SRE and Observability communities, and previously was an SRE working on products ranging from the Google Cloud Load Balancer to Google Flights.","render":"<h4><a id=\"Tuning_Apache_Kafka_and_Confluent_Platform_for_Graviton2_using_Amazon_Correttohttpsawsamazoncomcorretto_0\"></a><strong>Tuning Apache Kafka and Confluent Platform for Graviton2 using <a href=\"https://aws.amazon.com/corretto\" target=\"_blank\">Amazon Corretto</a></strong></h4>\n<p><em>By Guest Blogger <a href=\"https://www.honeycomb.io/teammember/liz-fong-jones/\" target=\"_blank\">Liz Fong-Jones, Principal Developer Advocate, Honeycomb.io</a></em></p>\n<h5><a id=\"Background_3\"></a><strong>Background</strong></h5>\n<p>Honeycomb is a leading observability platform used by high-performance engineering teams to quickly visualize, analyze, and improve cloud application quality and performance. We utilize the OpenTelemetry standard to ingest data from our clients, including those hosted on AWS and using the AWS Distribution of OpenTelemetry. Once data is optionally pre-sampled within client <a href=\"https://aws.amazon.com/vpc/\" target=\"_blank\">Amazon Virtual Private Clouds (Amazon VPC)</a>, it flows to Honeycomb for analysis, resulting in a data volume of millions of trace spans per second passing through our systems.</p>\n<p>To make sure of the durability and reliability of processing across software upgrades, spot instance retirements, and other continuous chaos, we utilize Application Load Balancers (ALBs) to route traffic to stateless ingest workers which publish the data into a pub-sub or message queuing system. Then, we read from this system to consume any telemetry added since the last checkpoint, decoupling the ingest process and allowing for indexing to be paused and restarted. For the entire history of Honeycomb dating back to 2016, we have used variants of the Apache Kafka software to perform this crucial pub-sub role.</p>\n<h5><a id=\"Factors_in_Kafka_performance_8\"></a><strong>Factors in Kafka performance</strong></h5>\n<p>After having <a href=\"https://www.honeycomb.io/blog/scaling-kafka-observability-pipelines/\" target=\"_blank\">chosen im4gn.4xlarge instances</a> for our Kafka brokers, we were curious how much further we could push the already excellent performance that we were seeing. Although it’s true that Kafka and other JVM workloads “just work” on ARM without modification in a majority of cases, a little bit of fine-tuning and polish can really pay off.</p>\n<p>To understand the critical factors underlying the performance of our Kafka brokers, let’s recap what Kafka brokers do in general, as well as what additional features our specific Kafka distribution contains.</p>\n<p>Apache Kafka is written in a mix of Scala and Java, with some JNI-wrapped C libraries for performance-sensitive code, such as ZSTD compression. A Kafka broker serializes and batches incoming data coming from producers or replicated from its peers, serves data to its peers to allow for replication, and responds to requests to consume recently produced data. Furthermore, it manages the data lifecycle and ages out expired segments, tracks consumer group offsets, and manages metadata in collaboration with a fleet of Zookeeper nodes.</p>\n<p>As explained in the im4gn post, we use Confluent Enterprise Platform (a distribution of Apache Kafka customized by Confluent) to tier older data to <a href=\"https://aws.amazon.com/s3/\" target=\"_blank\">Amazon Simple Storage Service (Amazon S3)</a> to free up space on the local NVMe SSDs. This additional workload introduces the overhead of high-throughput HTTPS streams, rather than just the Kafka internal protocols and disk serialization.</p>\n<h5><a id=\"Profiling_the_Kafka_broker_17\"></a><strong>Profiling the Kafka broker</strong></h5>\n<p>Immediately after switching to im4gn instances from i3en, we saw 40% peak CPU utilization, 15% off-peak CPU utilization, and utilized 30% of disk at peak (15% off-peak). We were hoping to keep these two utilization numbers roughly in line with each other to maximize the usage of our instances and keep cost economics under control. By using <a href=\"https://github.com/jvm-profiling-tools/async-profiler\" target=\"_blank\">Async Profiler</a> for short runs, and later <a href=\"https://github.com/pyroscope-io/pyroscope-java\" target=\"_blank\">Pyroscope</a> to continuously verify our results, we could see where in the broker’s code CPU time was being spent and identify wasteful usage.</p>\n<p>The first thing that jumped out at us was the 20% of time being spent doing <a href=\"https://github.com/luben/zstd-jni\" target=\"_blank\">zstd in JNI</a>.</p>\n<p>We hypothesized that we could obtain modest improvements from updating the ZSTD JNI JAR from the 1.5.0-x bundled with Confluent’s distro to a more recent 1.5.2-x version.</p>\n<p>However, our most significant finding from profiling was the significant time (12% of consumed CPU) being spent in com/sun/crypto/provider/GaloisCounterMode.encryptFinal, as part of the kafka/tier/store/S3TierObjectStore.putFile Confluent Tiered Storage process (28.4% of total broker consumed CPU in total). This was surprising, as we hadn’t seen this high of an overhead on the i3en instances, and others who ran vanilla Kafka on ARM had seen comparable CPU profiles to x86.</p>\n<p>At this point, we began our collaboration with the Corretto team at AWS, which has been working to improve the performance of JVM applications on Graviton. Yishai reached out and asked if we were interested in trying the Corretto team’s branch that supplies ARM AES CTR intrinsic, because it’s a hot codepath used by TLS.</p>\n<p>After upgrading to the branch build of the JDK, and enabling</p>\n<pre><code class=\"lang-\">-XX:+UnlockDiagnosticVMOptions -XX:+UseAESCTRIntrinsics\n</code></pre>\n<p>in our extra JVM flags, we saw a significant performance improvement with profiling showing that com/sun/crypto/provider/GaloisCounterMode.encryptFinal is only taking 0.4% of time (with an additional 1% each in ghash_processBlocks_wide and counterMode_AESCrypt attributed to unknown_Java). This makes the total cost of the kafka/tier/store/S3TierObjectStore.putFile workload now only 16.4% — a reduction of 12% of total broker consumed CPU for tiering.</p>\n<p>We don’t currently use TLS between Kafka brokers or clients, otherwise the savings would likely have been even greater. Speculating, this almost certainly lowers to ~1% overhead of the performance cost of enabling TLS between brokers, which we otherwise might have been hesitant to do due to the large penalty.</p>\n<h4><a id=\"Show_me_the_pictures_and_graphs_37\"></a><strong>Show me the pictures and graphs!</strong></h4>\n<p>Before any experimentation:</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/8af90718b29347d4b1249bf273449be0_image.png\" alt=\"image.png\" /></p>\n<p>After applying UseAESCTRIntrinsics:</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/bbfe36b791344dac8d716a9809c89c23_image.png\" alt=\"image.png\" /><br />\n<img src=\"https://dev-media.amazoncloud.cn/c2279964e575480f886647e6d814961d_image.png\" alt=\"image.png\" /><br />\n<img src=\"https://dev-media.amazoncloud.cn/301a2fd939f1405aa80727ee3bdb901c_image.png\" alt=\"image.png\" /></p>\n<p>This result was clearly better. However, running a bleeding edge JVM build was not a great long-term approach for our production workload, and it wouldn’t necessarily make sense to ask all of the Confluent customers or all of the JVM or Kafka workloads to switch to using the latest Corretto JVM to generalize our results in the future. Furthermore, there was another problem not solved by the</p>\n<pre><code class=\"lang-\">UseAESCTRIntrinsics\n</code></pre>\n<p>patch: MD5 checksum time.</p>\n<h5><a id=\"Enter_AWS_Correttohttpsawsamazoncomcorretto_Crypto_Provider_55\"></a><strong>Enter <a href=\"https://aws.amazon.com/corretto\" target=\"_blank\">AWS Corretto</a> Crypto Provider</strong></h5>\n<p>After addressing TLS/AES overhead, the remaining work left to do was fix the 9.5% of CPU time being spent calculating MD5 (which is also part of the process of doing an Amazon S3 upload). The best solution here would be to not perform the MD5 digest at all (since Amazon S3 removed the requirement for Content-MD5 header). Today, TLS already includes HMAC stream check summing, and if bits are changing on the disk, then we have bigger problems regardless of whether tiering is happening. The Confluent team is working on allowing for MD5 opt-out. Meanwhile, we wanted something that could address both TLS/AES overhead and MD5 overhead, all without having to patch the JVM.</p>\n<p>The <a href=\"https://github.com/corretto/amazon-corretto-crypto-provider\" target=\"_blank\">AWS Corretto Crypto Provider</a> is a Java security API provider that implements digest and encryption algorithms with compiled C/JNI wrapped code. Although official binaries aren’t yet supplied for ARM, it was easy to grab a spare Graviton2 instance and compile a build, then set it as the -Djava.security.properties provider in the Kafka startup scripts. With ACCP enabled, only 1.8% of time is spent in AESGCM (better than the 0.4%+1%+1% = 2.4% seen with<br />\n<code>UseAESCTRIntrinsics</code>), and only 4.7% of time is spent in MD5 (better than the 9.5% we previously saw).</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/bc9ede35f14e4b50a98fe523e5ec223a_image.png\" alt=\"image.png\" /></p>\n<p>This means that the total overhead of Kafka/tier/store/S3TierObjectStore.putFile is now 12-14% rather than 28% (about half what it was before).</p>\n<p>We felt ready to fully deploy this result across all of our production workloads and leave it live, knowing that we could still benefit from future rolling Corretto official releases with JVM flags set to production, non-experimental values.</p>\n<h5><a id=\"The_future_of_Kafka_and_ARM_at_Honeycomb_67\"></a><strong>The future of Kafka and ARM at Honeycomb</strong></h5>\n<p>Although we’re satisfied after tuning with the behavior of our fleet of six im4gn.2xlarge instances for serving our workload of 2M messages per second, we decided to preemptively scale up our fleet to nine brokers. The rationale had nothing to do with CPU performance. Instead, we were concerned after repeated weekly broker termination chaos engineering experiments about the network throughput required during peak hours to survive the loss of a single broker and re-replicate all of the data in a timely fashion</p>\n<p>By spreading the 3x duplicated data across nine brokers, only one third of all of the data, rather than half of all of the data, would need to be re-replicated in the event of broker loss, and the replacement broker would have eight healthy peers to read from, rather than five. Increasing capacity by 50% halved the time required to fully restore in-service replica quorum at peak weekday traffic from north of six hours to less than three hours.</p>\n<p>This change is just one of a series of many small changes that we’ve made to optimize and tune our AWS workload at Honeycomb. In the coming weeks, we hope to share how, without any impact on customer-visible performance, we decommissioned 100% of our Intel EC2 instances and 85% of our Intel <a href=\"https://aws.amazon.com/lambda/\" target=\"_blank\">AWS Lambda</a> functions in our fleet for a net cost and energy savings.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/22d7fe09f92e42349d47a5e3890a2fd9_image.png\" alt=\"image.png\" /></p>\n<p><strong>Liz Fong-Jones</strong><br />\nLiz Fong-Jones is a developer advocate, labor and ethics organizer, and Site Reliability Engineer (SRE) with 16+ years of experience. She is an advocate at Honeycomb.io for the SRE and Observability communities, and previously was an SRE working on products ranging from the Google Cloud Load Balancer to Google Flights.</p>\n"}
Tuning Apache Kafka and Confluent Platform for Graviton2 using Amazon Corretto
海外精选

海外精选的内容汇集了全球优质的亚马逊云科技相关技术内容。同时,内容中提到的“AWS”
是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。

 0
0 0
0亚马逊云科技解决方案 基于行业客户应用场景及技术领域的解决方案
联系亚马逊云科技专家
亚马逊云科技解决方案
基于行业客户应用场景及技术领域的解决方案
联系专家

0
目录

 分享
分享 点赞
点赞 收藏
收藏 目录
目录立即注册,开启您的免费套餐
立即关注

亚马逊云开发者
公众号

User Group
公众号

亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
关于我们 
更多资源
开发者工具
更多支持
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
