{"value":"There are different strategies you can leverage to migrate an on-premises SQL Server workload to [Amazon Relational Database Service (Amazon RDS) Custom for SQL Server](https://aws.amazon.com/rds/custom/). All of them come with pros and cons.\n\nThe following are some high-level migration challenges that you may encounter during your analysis and implementation phase:\n\n- Lift and shift (backup and restore) is efficient for moving an on-premises workload ‘as is’ to Amazon Web Services, but has more downtime during the cutover.\n- [Amazon Web Services Database Migration Service](https://aws.amazon.com/dms/) (Amazon Web Services DMS) helps you migrate databases to Amazon Web Services quickly and securely. You can also continuously replicate data with low latency from [any supported source](https://docs.aws.amazon.com/dms/latest/userguide/CHAP_Source.html) to [any supported target](https://docs.aws.amazon.com/dms/latest/userguide/CHAP_Target.html). However, it has some limitations if you need to move the workload as is to the cloud. For more details , refer to [Limitations on using SQL Server as a source for Amazon Web Services DMS](https://docs.aws.amazon.com/dms/latest/userguide/CHAP_Source.SQLServer.html#CHAP_Source.SQLServer.Limitations).\n- [Amazon Web Services Snowball](https://aws.amazon.com/snowball/) moves terabytes of data in about a week. You can use it to move things like databases, backups, archives, healthcare records, analytics datasets, IoT sensor data, and media content, especially when network conditions prevent realistic timelines for transferring large amounts of data both into and out of Amazon Web Services. Amazon Web Services Snowball is designed to handle large volume workloads so if your requirement isn’t as large as multiple terabytes then one of the other solutions may be a better fit.\n\nIn this post, we provide you a database migration pattern solution for your on-premises SQL Server standalone workload to Amazon RDS Custom, using a domain-independent Always On availability group.\n\nAmazon RDS Custom is a managed database service for legacy, custom, and packaged applications that require access to the underlying OS and DB environment. Amazon RDS Custom for SQL Server automates the setup, operation, and scaling of databases in the cloud, while granting access to the database and underlying operating system to configure settings, install drivers, and enable native features to help you meet the dependent application’s requirements.\n\nThe [Always On availability group](https://docs.microsoft.com/en-us/sql/database-engine/availability-groups/windows/always-on-availability-groups-sql-server?view=sql-server-ver16) provides a high availability and disaster recovery solution with an enterprise-level alternative to database mirroring. An availability group supports a replicated environment for a discrete set of user databases, known as availability databases, that can fail over together.\n\n### **Solution overview**\n\nThis migration pattern typically involves source and destination replica servers. For this post, our source is the on-premises standalone or workgroup server as the primary replica (Node1). Our destination is an RDS Custom for SQL Server database instance as the secondary replica (Node2). DNS configuration is done within the server (hosts file). The following diagram illustrates the solution architecture.\n\n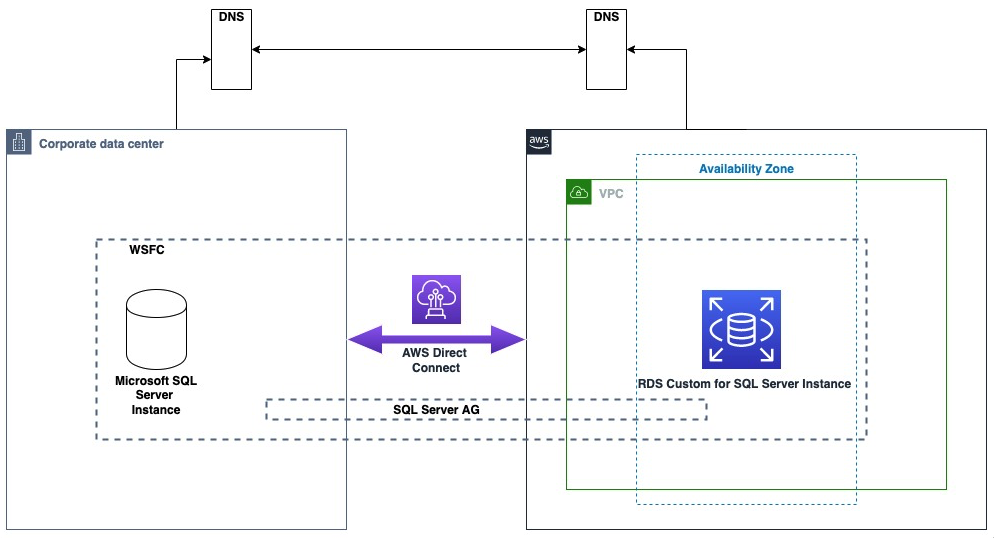\n\nThe following are the high-level steps for the solution:\n\n1. Create a primary and secondary replica\n2. Configure Windows firewall inbound rules/VPC security group rules\n3. Set up connectivity from on-premises to the Amazon Web Services Cloud\n4. Configure the domain-independent Windows failover cluster\n5. Set up the prerequisites for an Always On an availability group\n6. Create the Always On availability group\n7. Migrate the on-premises database to Amazon RDS Custom for SQL Server\n\n### **Prerequisites**\n\nWe assume that you have prior knowledge regarding [setting up Always On availability groups](https://docs.microsoft.com/en-us/sql/database-engine/availability-groups/windows/always-on-availability-groups-sql-server?view=sql-server-ver15).\nIn this post, we configure a domain-independent availability group to perform a migration. For additional information, refer to [What is an Always On availability group](https://docs.microsoft.com/en-us/sql/database-engine/availability-groups/windows/overview-of-always-on-availability-groups-sql-server?view=sql-server-ver15) and [Create a domain-independent availability group](https://docs.microsoft.com/en-us/sql/database-engine/availability-groups/windows/domain-independent-availability-groups?view=sql-server-ver15). We use SQL Server 2019 Enterprise Edition and Windows Server 2019.\n\nIn order to follow this post, the following prerequisites are required:\n\n- Install and configure [Amazon Web Services Command Line Interface](https://aws.amazon.com/cli/) (Amazon Web Services CLI)\n- An [Amazon Web Services account](https://portal.aws.amazon.com/billing/signup) and appropriate permissions to interact with resources in your Amazon Web Services account.\n- [Amazon Virtual Private Cloud](https://aws.amazon.com/quickstart/architecture/vpc) (Amazon VPC)\n\nThis solution can incur costs in your Amazon Web Services Account. Refer to the [RDS pricing page](https://aws.amazon.com/rds/sqlserver/pricing/) for more information. Make sure you remove the resources once you are done with the solution.\n\nWe strongly recommend that you set up Always On in a non-production instance and run end-to-end validations before you implement this solution in a production environment. It’s also recommended to follow the preceding high-level steps in the same order of sequence.\n\n### **Create a primary and secondary replica**\n\nFor this post, we create an [Amazon Elastic Compute Cloud](https://aws.amazon.com/ec2/) (Amazon EC2) SQL Server instance to represent the on-premises standalone primary replica (Node1).\n\nTake note of your source IP address. In our case, Node1 uses the private IP 10.0.23.99.\n\nLaunch Node2, using the following Amazon Web Services CLI script, and update the parameters accordingly. For more information about how to create an RDS Custom for SQL Server DB instance, refer to [Creating and connecting to a DB instance for Amazon RDS Custom for SQL Server](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/custom-creating-sqlserver.html).\n\n ```\naws rds create-db-instance \\\n --engine custom-sqlserver-ee \\\n --engine-version 15.00.4073.23.v1 \\\n --db-instance-identifier <XXXXX> \\\n --db-instance-class db.m5.xlarge \\\n --db-subnet-group rds-custom-secondary \\\n --master-username admin\\\n --master-user-password <XXXXX>\\\n --backup-retention-period 7 \\\n --port 1433 \\\n --kms-key-id <kms-key-id> \\\n --custom-iam-instance-profile RDSCustomIAMProfile \\\n --vpc-security-group-ids security-group \\\n --publicly-accessible \\\n --region us-east-2\n```\n\nTake note of your destination IP address. In our case, Node2 uses the private IP 172.31.154.104.\n\n### **Configure Windows firewall inbound rules and VPC security group rules**\n\nFor successful Windows failover cluster creation and communication to happen, you must open the following ports at the Windows operating system level and VPC security group level.\n\n- TCP ports 1433, 1434, 4022, 5022, 5023, and 135\n- UDP ports 3343 and 137. For more information about creating inbound port rules in Windows, refer to [Create an Inbound Port Rule](https://docs.microsoft.com/en-us/windows/security/threat-protection/windows-firewall/create-an-inbound-port-rule). To learn more about controlling traffic through security groups, refer to [Security group rules](https://docs.aws.amazon.com/vpc/latest/userguide/VPC_SecurityGroups.html#SecurityGroupRules).\n\n### **Set up connectivity from on-premises to the Amazon Web Services cloud**\n\nIt’s very important to establish a secure connection from on-premises to the Amazon Web Services cloud so both can communicate with each other. You can adopt different methodologies to achieve this, for example using [Amazon Web Services Transit Gateway](https://aws.amazon.com/transit-gateway/?whats-new-cards.sort-by=item.additionalFields.postDateTime&whats-new-cards.sort-order=desc), [Amazon Web Services Direct Connect](https://docs.aws.amazon.com/directconnect/latest/UserGuide/Welcome.html), or [Amazon Web Services VPN](https://aws.amazon.com/vpn/).\n\n### **Configure a domain-independent Windows failover cluster**\n\nNow let’s configure our domain-independent Windows failover cluster. Run the commands in this section in Windows PowerShell 64-bit as an administrator. Note that multiple server restarts will occur as a part of the setup process.\n\n#### **Install the failover clustering feature in all replica servers**\n\nRun the following command on both nodes to install the Windows failover clustering feature:\n\n```\nInstall-WindowsFeature -Name Failover-Clustering –IncludeManagementTools\n```\n\n#### **Assign a primary DNS suffix to all replica servers**\n\nRun the following command on Node1. For this example, we assign the DNS suffix as “OnPremSource.com”.\n\n```\nSet-ItemProperty \"HKLM:\\SYSTEM\\CurrentControlSet\\Services\\Tcpip\\Parameters\\\" -Name \"NV Domain\" -Value <OnPremSource.com>\n```\n\nRun the following command on Node2 . For this example, we assign the DNS suffix as “AWSDestination.com”.\n\n```\nSet-ItemProperty \"HKLM:\\SYSTEM\\CurrentControlSet\\Services\\Tcpip\\Parameters\\\" -Name \"NV Domain\" -Value <AWSDestination.com>\n```\n\n#### **Update the host file on each replica servers**\n\nOn both nodes, navigate to```C:\\Windows\\System32\\Drives\\etc\\hosts```Edit the Hosts file manually to add the IP address, host name, and FQDN entry at the end of the file. Restart the nodes for the changes to take effect.\n\n**The following table summarizes the parameter details.**\n\n\n\nUse the following format:\n\n- <IP address of node1> <node1domainname>\n- <IP address of node1> <node1hostname.domainname>\n- <IP address of node2> <node2domainname>\n- <IP address of node2> <node2hostname.domainname>\n\nThe following screenshot is an example from Node1.\n\n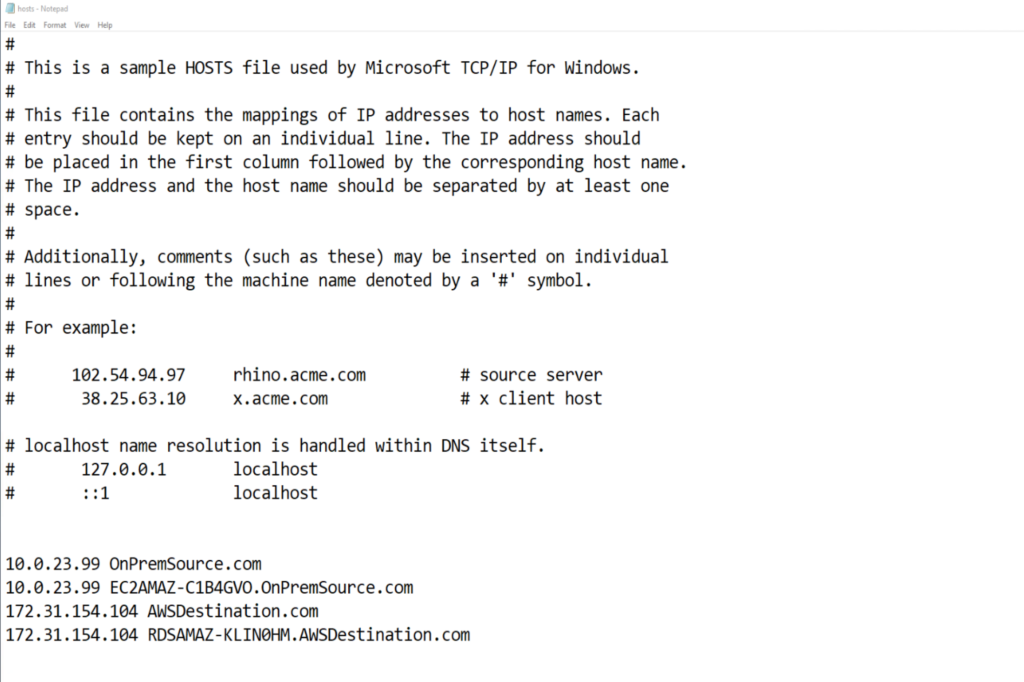\n\nAlternatively, run the following PowerShell (change the parameters accordingly) to perform the same actions:\n\n```\n$content= “\n<IP address of node1> <node1domainname> <IP address of node1> <node1hostname.domainname> <IP address of node2> <node2domainname> <IP address of node2> <node2hostname.domainname>\nAdd-Content -Path 'C:\\Windows\\System32\\drivers\\etc\\hosts' $content\n\nRestart-Computer\n```\n\nThe following is an example command using our Node1 and Node2 configuration.\n\n```\n$content= “\n10.0.23.99 OnPremSource.com\n10.0.23.99 EC2AMAZ-C1B4GVO.OnPremSource.com\n172.31.154.104 AWSDestination.com\n172.31.154.104 RDSAMAZ-KLIN0HM.AWSDestination.com“\nAdd-Content -Path 'C:\\Windows\\System32\\drivers\\etc\\hosts' $content\n\nRestart-Computer\n```\n\nNow try to [Test-NetConnection](https://docs.microsoft.com/en-us/powershell/module/nettcpip/test-netconnection?view=windowsserver2022-ps) between the nodes on port 1433 to make sure both servers have network connectivity. If you encounter an issue, open the Windows firewall’s inbound and outbound rules and review your configuration.\n\nRun the following command on Node1 to test port connectivity to Node2.\n\n```\nTest-NetConnection -port 1433 -ComputerName <AWSDestination.com>\n```\n\nRun the following command on Node2 to test port connectivity to Node1.\n\n```\nTest-NetConnection -port 1433 -ComputerName <on-premisessource.com>\n```\n\n#### **Set up local admin user account on all replica servers**\n\nCreate a local Windows user and add that user to the administrator’s group. Create a similar user on the other node with the same password. Run the following commands on both nodes:\n\n```\n$Password = Read-Host -AsSecureString\nNew-LocalUser <”user-name”> -Password $Password -FullName <”full-name”> -Description <\"description of username\">\nAdd-LocalGroupMember -Group \"Administrators\" -Member <”user-name”>\n```\n\n#### **Configure the LocalAccountTokenFilterPolicy registry setting**\n\nRun the following command on both nodes to configure the```LocalAccountTokenFilterPolicy```value to```1```This setting is required because we use a local user account during the failover cluster creation and not the domain account.\n\n```\nSet-ItemProperty -Path HKLM:\\SOFTWARE\\Microsoft\\Windows\\CurrentVersion\\Policies\\System -Name LocalAccountTokenFilterPolicy -Value 1\n```\n\n#### **Configure the DNS suffix list**\n\nRun the following commands on both the nodes to append the existing DNS suffix list.\n\n```\n$dnsCGSetting = Get-DnsClientGlobalSetting\n$dnsCGSetting.SuffixSearchList += \"<node1domainname>\",\"<node2domainname>\"\n\nset-DnsClientGlobalSetting -SuffixSearchList $dnsCGSetting.SuffixSearchList\n\n\nClear-DnsClientCache\n```\n#### **Configure a domain-independent Windows failover cluster**\n\nRun the following command on Node1 as the new user that you created to create a domain-independent Windows failover cluster. If possible, RDP as the new user and run the command.\n\nNew-Cluster -Name <clustername> -Node <ip address of node1>, <ip address of node2> -AdministrativeAccessPoint DNS -NoStorage -StaticAddress <ipaddress for on-premisessource.com,ipaddress for AWSDestination.com>\n\n### **Set up the prerequisites for an Always On availability group**\n\nLet’s configure our SQL Server Always On availability group, which is a robust high availability and disaster recovery solution in SQL Server.\n\n#### **Configure the SQL Server Log on as a service using a local admin user on both replica servers**\n\nChange the SQL Server service account’s log-on as a service to the local admin user you created in the preceding section on both nodes using the following PowerShell code (change the parameters accordingly). Note that this will restart the SQL services automatically. In this example, we use the testing user.\n\n```\n[System.Reflection.Assembly]::LoadWithPartialName('Microsoft.SqlServer.SqlWmiManagement')| Out-Null\n$smowmi = New-Object Microsoft.SqlServer.Management.Smo.Wmi.ManagedComputer \"<hostname>\"\n$wmisvc = $smowmi.Services | Where-Object {$_.Name -eq \"SQLSERVERAGENT\" -or $_.Name -eq \"MSSQLSERVER\"}\n$wmisvc.SetServiceAccount('<hostname>\\testing','xxx')\n```\n\nYou can also do this in a graphical user interface using the ```services.msc```console.\n\n#### **Enable the Always On availability group feature on both replica servers**\n\nRun the following commands on both nodes, changing the parameters accordingly. Note that the third command restarts SQL services:\n\n```\nImport-Module \"SQLPS\"\nEnable-SqlAlwaysOn -ServerInstance <\"hostname\"> -Force\nget-service -Name MSSQLSERVER,SQLSERVERAGENT|Restart-Service -Force\n```\n\n#### **Create the login, master key, certificate, and endpoint on both replica servers**\n\nTurn on SQL authentication on both instances and restart them if you haven’t already. For information about changing authentication mode, refer to [Change server authentication mode](https://docs.microsoft.com/en-us/sql/database-engine/configure-windows/change-server-authentication-mode?view=sql-server-ver16). Run the following TSQL statements in SQL Server Management Studio on the corresponding node’s mentioned. Change the directory locations according to your environment.\n\nOn Node1, run the following code to set up the certificate:\n\n```\n-- master key creation\nCREATE MASTER KEY ENCRYPTION BY PASSWORD = 'XXX';\n\n-- Certificate creation \nCREATE CERTIFICATE [cert_node1] WITH SUBJECT = 'CERT_SUB';\n\n-- Certificate backup \nBACKUP CERTIFICATE [cert_node1]\n TO FILE = 'C:\\TESTING\\CERT_node1.CER'\n \n-- Endpoint creation \nCREATE ENDPOINT [HADR] STATE = STARTED AS TCP (LISTENER_PORT = 5022 ) FOR DATA_MIRRORING ( ROLE = ALL, AUTHENTICATION = CERTIFICATE [cert_node1], ENCRYPTION = REQUIRED ALGORITHM AES);\n```\n\nOn Node2, run the following code to set up the certificate:\n\n```\n-- master key creation*\nCREATE MASTER KEY ENCRYPTION BY PASSWORD = 'XXX';\n\n-- Certificate creation \nCREATE CERTIFICATE [cert_node2] WITH SUBJECT = 'CERT_SUB';\n\n--certificate backup \nBACKUP CERTIFICATE [cert_node2]\n TO FILE = 'C:\\TESTING\\CERT_node2.CER'\n \n--endpoint creation \nCREATE ENDPOINT [HADR] STATE = STARTED AS TCP (LISTENER_PORT = 5022 ) FOR DATA_MIRRORING ( ROLE = ALL, AUTHENTICATION = CERTIFICATE [cert_node2], ENCRYPTION = REQUIRED ALGORITHM AES);\n```\n\nCopy the certificates between nodes either manually or by running the following Windows PowerShell commands on Node1:\n\n```\nCopy-Item -Path \\\\EC2AMAZ-C1B4GVO\\c$\\testing\\cert_node1.cer -Destination \\\\RDSAMAZ-KLIN0HM\\c$\\testing\\\nCopy-Item -Path \\\\RDSAMAZ-KLIN0HM\\c$\\testing\\cert_node2.cer -Destination \\\\EC2AMAZ-C1B4GVO\\c$\\testing\\\n```\n\nOn Node1, run the following code:\n\n```\n-- Login creation\n use master;\n\nCREATE LOGIN [aon_node2] WITH PASSWORD = 'XXX';\nCREATE USER [aon_node2] FOR LOGIN [aon_node2];\n\n-- Restore Certificate from node2\nCREATE CERTIFICATE [cert_node2]\nAUTHORIZATION aon_node2 FROM FILE = 'C:\\TESTING\\CERT_node2.CER'\n\nGRANT CONNECT ON ENDPOINT::[HADR] TO [aon_node2];\n```\nOn Node2, run the following code:\n\n```\n-- Login creation\n use master;\n\nCREATE LOGIN [aon_node1] WITH PASSWORD = 'XXX';\nCREATE USER [aon_node1] FOR LOGIN [aon_node1];\n\n\n-- Certificate creation\nCREATE CERTIFICATE [cert_node1]\nAUTHORIZATION aon_node1 FROM FILE = 'C:\\TESTING\\CERT_node1.CER'\n\nGRANT CONNECT ON ENDPOINT::[HADR] TO [aon_node1];\n```\n\n### **Create an Always On availability group**\n\nRun the following command on Node1 to create an Always On availability group. The file system directory structure of the database files that will be created on Node2 should be identical to Node1 in order for automatic seeding to work. If they’re different, you must manually prepare the secondary database. For more information, see [Prepare a secondary database for an Always On availability group](https://docs.microsoft.com/en-us/sql/database-engine/availability-groups/windows/manually-prepare-a-secondary-database-for-an-availability-group-sql-server?view=sql-server-ver16).\n\nNote that all SQL Server database files are stored on the ```D:```drive by default, in the```D:\\rdsdbdata\\DATA```directory.\n\nIf you create or alter the database file location to be anywhere other than the ```D:```drive, then RDS Custom places the DB instance outside the support perimeter. For details, refer to [Troubleshooting DB issues for Amazon RDS Custom](https://docs.amazonaws.cn/en_us/AmazonRDS/latest/UserGuide/custom-troubleshooting.html).\n\nModify the ```availability group name```, ```database name```, ```replica value```, and ```endpoint_url```value according to your environment.\n\n```\nUSE [master]\nGO\nCREATE AVAILABILITY GROUP [<ag_name>]\nWITH (AUTOMATED_BACKUP_PREFERENCE = PRIMARY,\nDB_FAILOVER = OFF,\nDTC_SUPPORT = NONE,\nCLUSTER_TYPE = NONE,\nREQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 0)\nFOR DATABASE [<db_name>]\nREPLICA ON N'EC2AMAZ-C1B4GVO' WITH (\n ENDPOINT_URL = N'TCP://EC2AMAZ-C1B4GVO.OnPremSource.com:5022',\n FAILOVER_MODE = MANUAL, \n AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, \n BACKUP_PRIORITY = 50, \n SEEDING_MODE = AUTOMATIC, \n SECONDARY_ROLE(ALLOW_CONNECTIONS = NO)),\n N'RDSAMAZ-KLIN0HM' WITH (\n ENDPOINT_URL = N'TCP://RDSAMAZ-KLIN0HM.AWSDestination.com:5022',\n FAILOVER_MODE = MANUAL,\n AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,\n BACKUP_PRIORITY = 50, \n SEEDING_MODE = AUTOMATIC, \n SECONDARY_ROLE(ALLOW_CONNECTIONS = NO));\nGO\nALTER AVAILABILITY GROUP [<ag_name>] GRANT CREATE ANY DATABASE;\n```\n\nOn Node2, run the following code :\n\n```\nALTER AVAILABILITY GROUP [<ag_name>] JOIN WITH (CLUSTER_TYPE = NONE);\nALTER AVAILABILITY GROUP [<ag_name>] GRANT CREATE ANY DATABASE;\n```\n\nAn Always On availability group from on-premises to Amazon RDS Custom for SQL Server is successfully established.\n\nThe following screenshot shows Amazon EC2/on-premises replica as primary.\n\n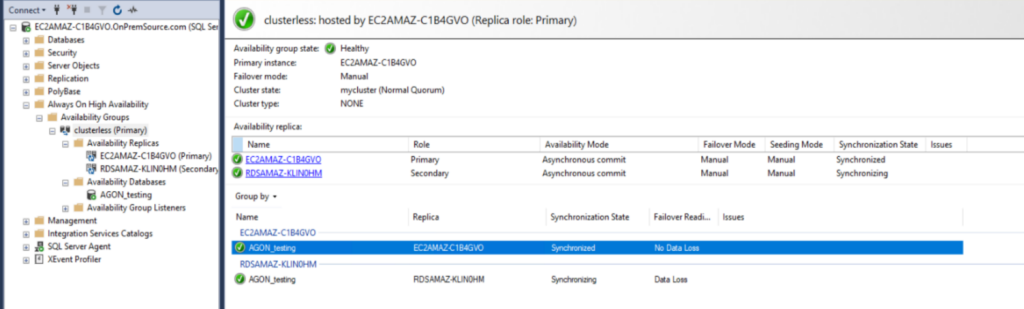\n\n### **Migrate the on-premises database to Amazon RDS Custom for SQL Server**\n\nUp to this step, we have demonstrated the setup to replicate the database as is from on-premises to Amazon RDS Custom for SQL Server.\n\nIn a typical migration scenario, you set this up and let it run until your actual cutover day approaches. When you’re ready for the migration, complete the following steps:\n\n1. Monitor the asynchronous data flow between Node 1 and Node2 using dynamic management views (DMVs). Query the DMV [sys.dm_hadr_database_replica_states](https://docs.microsoft.com/en-us/sql/relational-databases/system-dynamic-management-views/sys-dm-hadr-database-replica-states-transact-sql?view=sql-server-ver15) for ```last_commit_lsn```and ```last_commit_time```on both nodes to get an estimation of how far the destination is behind. For more information about monitoring performance, refer to [Monitor performance for Always On availability groups](https://docs.microsoft.com/en-us/sql/database-engine/availability-groups/windows/monitor-performance-for-always-on-availability-groups?view=sql-server-ver15).\n2. Stop all incoming application traffic to Node 1 so no write activities are occurring.\n3. Until now, the availability mode for the database was set to asynchronous commit to gain better performance. Switch that to synchronous commit to help avoid data loss by running the following TSQL on Node1:\n\n```\nUSE [master]\nGO\nALTER AVAILABILITY GROUP [<group-name>]\nMODIFY REPLICA ON N'<node1>' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT)\nGO\nUSE [master]\nGO\nALTER AVAILABILITY GROUP [<group-name>]\nMODIFY REPLICA ON N'<node2>' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT)\nGO\n```\n\n4. Repeat step 1 to revalidate and make sure RTO and RPO is met. At this point, we’re ready to perform the actual migration.\n5. Run the following TSQL on Node2 to migrate the database from on-premises to Amazon RDS Custom for SQL Server. This allows new read/write application connections to connect to the RDS Custom for SQL Server instance. Because we’re using domain-independent availability groups,```force_failover_allow_data_loss```is the only way to migrate the database.\n\n```\nUSE master;\nGO\n\nALTER AVAILABILITY GROUP [<group_name>] FORCE_FAILOVER_ALLOW_DATA_LOSS\nGO\n```\n\n6. Redirect your application, dependent services, traffic by modifying your connection string to use the RDS Custom for SQL Server instance so that the write activities can resume from this instance.\n\nThe following screenshot shows RDS Custom replica as primary.\n\n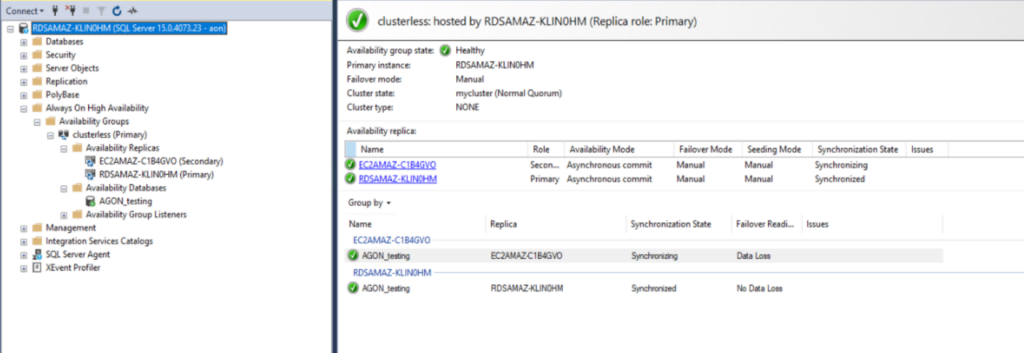\n\n#### **Rollback plan**\n\nFor any production change, it’s crucial to have a rollback plan. After the database migration from on-premises to Amazon RDS Custom for SQL Server is complete, data movement and synchronization will be suspended by default between the nodes. As a best practice, you should reestablish the synchronization back to on-premises by running the following TSQL on the on-premises node until you reach the cleanup phase so that you have an option to rollback if needed:\n\n```\nALTER DATABASE [<db-name>] SET HADR RESUME;\nGO\n```\n\n#### **Remove the on-premises dependencies**\n\nYou can monitor your application and database performance for a period of time to ensure stable performance. When you’re ready to run independently on Amazon RDS Custom for SQL Server, remove the on-premises dependencies by running the following TSQL statements\n\nThis removes the Always On database from the availability group. On Node2, run the following code:\n\n```\nUSE [master]\nGO\nALTER AVAILABILITY GROUP [<group-name>] REMOVE DATABASE [<db-name>];\n```\n\nOn both nodes, run the following code to drop the availability group completely:\n\n```\nDROP AVAILABILITY GROUP [<group-name>]\n```\n\n#### **Decommission the on-premises servers**\n\nNow that you have removed the on-premises dependencies of your RDS Custom for SQL Server instance, you can decommission the on-premises database, instance, or server accordingly. If you want high availability with RDS Custom for SQL Server, refer to [Configure high availability with Always On Availability Groups on Amazon RDS Custom for SQL Server](https://aws.amazon.com/blogs/database/configure-high-availability-with-always-on-availability-groups-on-amazon-rds-custom-for-sql-server/).\n\n### **Cleanup**\n\nTo avoid incurring future charges, delete the resources you created as part of this post. You can clean up the following Amazon Web Services resources:\n\n- Delete Amazon EC2 instance, refer to [Terminate your instance](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/terminating-instances.html)\n- Delete DB instance, refer to [Deleting a DB instance](https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_DeleteInstance.html)\n\n### **Summary**\n\nSQL Server Always On availability groups provide a cost-effective high availability and disaster recovery feature. The domain-independent Always On availability group feature enables you to configure your SQL Server cluster without using Active Directory, which reduces the complexity during a hybrid cluster setup.\n\nIn this post, we demonstrated a solution for migrating your on-premises SQL Server workload to Amazon RDS Custom for SQL Server using a domain-independent Always On availability group, which makes the whole migration strategy more simple, secure and cost-effective.\n\nTry out the solution and if you have any comments or questions, leave them in the comments section.\n\n#### **About the authors**\n\n\n\n**Aravind Hariharaputran** is Database Consultant with the Professional Services team at Amazon Web Services. He is passionate about databases in general with Microsoft SQL Server as his specialty. He helps build technical solutions that assist customers to migrate and optimize their on-premises database workload to the Amazon Web Services Cloud. He enjoys spending time with family and playing cricket.\n\n\n\n**Alok Srivastava** is Senior Database Consultant with Professional Services team at Amazon Web Services. He works as database specialist to help customers to architect and migrate their database solutions to Amazon Web Services.","render":"<p>There are different strategies you can leverage to migrate an on-premises SQL Server workload to <a href=\"https://aws.amazon.com/rds/custom/\" target=\"_blank\">Amazon Relational Database Service (Amazon RDS) Custom for SQL Server</a>. All of them come with pros and cons.</p>\n<p>The following are some high-level migration challenges that you may encounter during your analysis and implementation phase:</p>\n<ul>\n<li>Lift and shift (backup and restore) is efficient for moving an on-premises workload ‘as is’ to Amazon Web Services, but has more downtime during the cutover.</li>\n<li><a href=\"https://aws.amazon.com/dms/\" target=\"_blank\">Amazon Web Services Database Migration Service</a> (Amazon Web Services DMS) helps you migrate databases to Amazon Web Services quickly and securely. You can also continuously replicate data with low latency from <a href=\"https://docs.aws.amazon.com/dms/latest/userguide/CHAP_Source.html\" target=\"_blank\">any supported source</a> to <a href=\"https://docs.aws.amazon.com/dms/latest/userguide/CHAP_Target.html\" target=\"_blank\">any supported target</a>. However, it has some limitations if you need to move the workload as is to the cloud. For more details , refer to <a href=\"https://docs.aws.amazon.com/dms/latest/userguide/CHAP_Source.SQLServer.html#CHAP_Source.SQLServer.Limitations\" target=\"_blank\">Limitations on using SQL Server as a source for Amazon Web Services DMS</a>.</li>\n<li><a href=\"https://aws.amazon.com/snowball/\" target=\"_blank\">Amazon Web Services Snowball</a> moves terabytes of data in about a week. You can use it to move things like databases, backups, archives, healthcare records, analytics datasets, IoT sensor data, and media content, especially when network conditions prevent realistic timelines for transferring large amounts of data both into and out of Amazon Web Services. Amazon Web Services Snowball is designed to handle large volume workloads so if your requirement isn’t as large as multiple terabytes then one of the other solutions may be a better fit.</li>\n</ul>\n<p>In this post, we provide you a database migration pattern solution for your on-premises SQL Server standalone workload to Amazon RDS Custom, using a domain-independent Always On availability group.</p>\n<p>Amazon RDS Custom is a managed database service for legacy, custom, and packaged applications that require access to the underlying OS and DB environment. Amazon RDS Custom for SQL Server automates the setup, operation, and scaling of databases in the cloud, while granting access to the database and underlying operating system to configure settings, install drivers, and enable native features to help you meet the dependent application’s requirements.</p>\n<p>The <a href=\"https://docs.microsoft.com/en-us/sql/database-engine/availability-groups/windows/always-on-availability-groups-sql-server?view=sql-server-ver16\" target=\"_blank\">Always On availability group</a> provides a high availability and disaster recovery solution with an enterprise-level alternative to database mirroring. An availability group supports a replicated environment for a discrete set of user databases, known as availability databases, that can fail over together.</p>\n<h3><a id=\"Solution_overview_14\"></a><strong>Solution overview</strong></h3>\n<p>This migration pattern typically involves source and destination replica servers. For this post, our source is the on-premises standalone or workgroup server as the primary replica (Node1). Our destination is an RDS Custom for SQL Server database instance as the secondary replica (Node2). DNS configuration is done within the server (hosts file). The following diagram illustrates the solution architecture.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/4f9a05a802db4a4cba626ef1b523070d_image.png\" alt=\"image.png\" /></p>\n<p>The following are the high-level steps for the solution:</p>\n<ol>\n<li>Create a primary and secondary replica</li>\n<li>Configure Windows firewall inbound rules/VPC security group rules</li>\n<li>Set up connectivity from on-premises to the Amazon Web Services Cloud</li>\n<li>Configure the domain-independent Windows failover cluster</li>\n<li>Set up the prerequisites for an Always On an availability group</li>\n<li>Create the Always On availability group</li>\n<li>Migrate the on-premises database to Amazon RDS Custom for SQL Server</li>\n</ol>\n<h3><a id=\"Prerequisites_30\"></a><strong>Prerequisites</strong></h3>\n<p>We assume that you have prior knowledge regarding <a href=\"https://docs.microsoft.com/en-us/sql/database-engine/availability-groups/windows/always-on-availability-groups-sql-server?view=sql-server-ver15\" target=\"_blank\">setting up Always On availability groups</a>.<br />\nIn this post, we configure a domain-independent availability group to perform a migration. For additional information, refer to <a href=\"https://docs.microsoft.com/en-us/sql/database-engine/availability-groups/windows/overview-of-always-on-availability-groups-sql-server?view=sql-server-ver15\" target=\"_blank\">What is an Always On availability group</a> and <a href=\"https://docs.microsoft.com/en-us/sql/database-engine/availability-groups/windows/domain-independent-availability-groups?view=sql-server-ver15\" target=\"_blank\">Create a domain-independent availability group</a>. We use SQL Server 2019 Enterprise Edition and Windows Server 2019.</p>\n<p>In order to follow this post, the following prerequisites are required:</p>\n<ul>\n<li>Install and configure <a href=\"https://aws.amazon.com/cli/\" target=\"_blank\">Amazon Web Services Command Line Interface</a> (Amazon Web Services CLI)</li>\n<li>An <a href=\"https://portal.aws.amazon.com/billing/signup\" target=\"_blank\">Amazon Web Services account</a> and appropriate permissions to interact with resources in your Amazon Web Services account.</li>\n<li><a href=\"https://aws.amazon.com/quickstart/architecture/vpc\" target=\"_blank\">Amazon Virtual Private Cloud</a> (Amazon VPC)</li>\n</ul>\n<p>This solution can incur costs in your Amazon Web Services Account. Refer to the <a href=\"https://aws.amazon.com/rds/sqlserver/pricing/\" target=\"_blank\">RDS pricing page</a> for more information. Make sure you remove the resources once you are done with the solution.</p>\n<p>We strongly recommend that you set up Always On in a non-production instance and run end-to-end validations before you implement this solution in a production environment. It’s also recommended to follow the preceding high-level steps in the same order of sequence.</p>\n<h3><a id=\"Create_a_primary_and_secondary_replica_45\"></a><strong>Create a primary and secondary replica</strong></h3>\n<p>For this post, we create an <a href=\"https://aws.amazon.com/ec2/\" target=\"_blank\">Amazon Elastic Compute Cloud</a> (Amazon EC2) SQL Server instance to represent the on-premises standalone primary replica (Node1).</p>\n<p>Take note of your source IP address. In our case, Node1 uses the private IP 10.0.23.99.</p>\n<p>Launch Node2, using the following Amazon Web Services CLI script, and update the parameters accordingly. For more information about how to create an RDS Custom for SQL Server DB instance, refer to <a href=\"https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/custom-creating-sqlserver.html\" target=\"_blank\">Creating and connecting to a DB instance for Amazon RDS Custom for SQL Server</a>.</p>\n<pre><code class=\"lang-\">aws rds create-db-instance \\\n --engine custom-sqlserver-ee \\\n --engine-version 15.00.4073.23.v1 \\\n --db-instance-identifier <XXXXX> \\\n --db-instance-class db.m5.xlarge \\\n --db-subnet-group rds-custom-secondary \\\n --master-username admin\\\n --master-user-password <XXXXX>\\\n --backup-retention-period 7 \\\n --port 1433 \\\n --kms-key-id <kms-key-id> \\\n --custom-iam-instance-profile RDSCustomIAMProfile \\\n --vpc-security-group-ids security-group \\\n --publicly-accessible \\\n --region us-east-2\n</code></pre>\n<p>Take note of your destination IP address. In our case, Node2 uses the private IP 172.31.154.104.</p>\n<h3><a id=\"Configure_Windows_firewall_inbound_rules_and_VPC_security_group_rules_73\"></a><strong>Configure Windows firewall inbound rules and VPC security group rules</strong></h3>\n<p>For successful Windows failover cluster creation and communication to happen, you must open the following ports at the Windows operating system level and VPC security group level.</p>\n<ul>\n<li>TCP ports 1433, 1434, 4022, 5022, 5023, and 135</li>\n<li>UDP ports 3343 and 137. For more information about creating inbound port rules in Windows, refer to <a href=\"https://docs.microsoft.com/en-us/windows/security/threat-protection/windows-firewall/create-an-inbound-port-rule\" target=\"_blank\">Create an Inbound Port Rule</a>. To learn more about controlling traffic through security groups, refer to <a href=\"https://docs.aws.amazon.com/vpc/latest/userguide/VPC_SecurityGroups.html#SecurityGroupRules\" target=\"_blank\">Security group rules</a>.</li>\n</ul>\n<h3><a id=\"Set_up_connectivity_from_onpremises_to_the_Amazon_Web_Services_cloud_80\"></a><strong>Set up connectivity from on-premises to the Amazon Web Services cloud</strong></h3>\n<p>It’s very important to establish a secure connection from on-premises to the Amazon Web Services cloud so both can communicate with each other. You can adopt different methodologies to achieve this, for example using <a href=\"https://aws.amazon.com/transit-gateway/?whats-new-cards.sort-by=item.additionalFields.postDateTime&whats-new-cards.sort-order=desc\" target=\"_blank\">Amazon Web Services Transit Gateway</a>, <a href=\"https://docs.aws.amazon.com/directconnect/latest/UserGuide/Welcome.html\" target=\"_blank\">Amazon Web Services Direct Connect</a>, or <a href=\"https://aws.amazon.com/vpn/\" target=\"_blank\">Amazon Web Services VPN</a>.</p>\n<h3><a id=\"Configure_a_domainindependent_Windows_failover_cluster_84\"></a><strong>Configure a domain-independent Windows failover cluster</strong></h3>\n<p>Now let’s configure our domain-independent Windows failover cluster. Run the commands in this section in Windows PowerShell 64-bit as an administrator. Note that multiple server restarts will occur as a part of the setup process.</p>\n<h4><a id=\"Install_the_failover_clustering_feature_in_all_replica_servers_88\"></a><strong>Install the failover clustering feature in all replica servers</strong></h4>\n<p>Run the following command on both nodes to install the Windows failover clustering feature:</p>\n<pre><code class=\"lang-\">Install-WindowsFeature -Name Failover-Clustering –IncludeManagementTools\n</code></pre>\n<h4><a id=\"Assign_a_primary_DNS_suffix_to_all_replica_servers_96\"></a><strong>Assign a primary DNS suffix to all replica servers</strong></h4>\n<p>Run the following command on Node1. For this example, we assign the DNS suffix as “OnPremSource.com”.</p>\n<pre><code class=\"lang-\">Set-ItemProperty "HKLM:\\SYSTEM\\CurrentControlSet\\Services\\Tcpip\\Parameters\\" -Name "NV Domain" -Value <OnPremSource.com>\n</code></pre>\n<p>Run the following command on Node2 . For this example, we assign the DNS suffix as “AWSDestination.com”.</p>\n<pre><code class=\"lang-\">Set-ItemProperty "HKLM:\\SYSTEM\\CurrentControlSet\\Services\\Tcpip\\Parameters\\" -Name "NV Domain" -Value <AWSDestination.com>\n</code></pre>\n<h4><a id=\"Update_the_host_file_on_each_replica_servers_110\"></a><strong>Update the host file on each replica servers</strong></h4>\n<p>On both nodes, navigate to<code>C:\\Windows\\System32\\Drives\\etc\\hosts</code>Edit the Hosts file manually to add the IP address, host name, and FQDN entry at the end of the file. Restart the nodes for the changes to take effect.</p>\n<p><strong>The following table summarizes the parameter details.</strong></p>\n<p><img src=\"https://dev-media.amazoncloud.cn/f49575a5a277432496c6879a7491cca5_image.png\" alt=\"image.png\" /></p>\n<p>Use the following format:</p>\n<ul>\n<li><IP address of node1> <node1domainname></li>\n<li><IP address of node1> <node1hostname.domainname></li>\n<li><IP address of node2> <node2domainname></li>\n<li><IP address of node2> <node2hostname.domainname></li>\n</ul>\n<p>The following screenshot is an example from Node1.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/ae9a1e28ea0e4507b1f5e0f970b77279_image.png\" alt=\"image.png\" /></p>\n<p>Alternatively, run the following PowerShell (change the parameters accordingly) to perform the same actions:</p>\n<pre><code class=\"lang-\">$content= “\n<IP address of node1> <node1domainname> <IP address of node1> <node1hostname.domainname> <IP address of node2> <node2domainname> <IP address of node2> <node2hostname.domainname>\nAdd-Content -Path 'C:\\Windows\\System32\\drivers\\etc\\hosts' $content\n\nRestart-Computer\n</code></pre>\n<p>The following is an example command using our Node1 and Node2 configuration.</p>\n<pre><code class=\"lang-\">$content= “\n10.0.23.99 OnPremSource.com\n10.0.23.99 EC2AMAZ-C1B4GVO.OnPremSource.com\n172.31.154.104 AWSDestination.com\n172.31.154.104 RDSAMAZ-KLIN0HM.AWSDestination.com“\nAdd-Content -Path 'C:\\Windows\\System32\\drivers\\etc\\hosts' $content\n\nRestart-Computer\n</code></pre>\n<p>Now try to <a href=\"https://docs.microsoft.com/en-us/powershell/module/nettcpip/test-netconnection?view=windowsserver2022-ps\" target=\"_blank\">Test-NetConnection</a> between the nodes on port 1433 to make sure both servers have network connectivity. If you encounter an issue, open the Windows firewall’s inbound and outbound rules and review your configuration.</p>\n<p>Run the following command on Node1 to test port connectivity to Node2.</p>\n<pre><code class=\"lang-\">Test-NetConnection -port 1433 -ComputerName <AWSDestination.com>\n</code></pre>\n<p>Run the following command on Node2 to test port connectivity to Node1.</p>\n<pre><code class=\"lang-\">Test-NetConnection -port 1433 -ComputerName <on-premisessource.com>\n</code></pre>\n<h4><a id=\"Set_up_local_admin_user_account_on_all_replica_servers_166\"></a><strong>Set up local admin user account on all replica servers</strong></h4>\n<p>Create a local Windows user and add that user to the administrator’s group. Create a similar user on the other node with the same password. Run the following commands on both nodes:</p>\n<pre><code class=\"lang-\">$Password = Read-Host -AsSecureString\nNew-LocalUser <”user-name”> -Password $Password -FullName <”full-name”> -Description <"description of username">\nAdd-LocalGroupMember -Group "Administrators" -Member <”user-name”>\n</code></pre>\n<h4><a id=\"Configure_the_LocalAccountTokenFilterPolicy_registry_setting_176\"></a><strong>Configure the LocalAccountTokenFilterPolicy registry setting</strong></h4>\n<p>Run the following command on both nodes to configure the<code>LocalAccountTokenFilterPolicy</code>value to<code>1</code>This setting is required because we use a local user account during the failover cluster creation and not the domain account.</p>\n<pre><code class=\"lang-\">Set-ItemProperty -Path HKLM:\\SOFTWARE\\Microsoft\\Windows\\CurrentVersion\\Policies\\System -Name LocalAccountTokenFilterPolicy -Value 1\n</code></pre>\n<h4><a id=\"Configure_the_DNS_suffix_list_184\"></a><strong>Configure the DNS suffix list</strong></h4>\n<p>Run the following commands on both the nodes to append the existing DNS suffix list.</p>\n<pre><code class=\"lang-\">$dnsCGSetting = Get-DnsClientGlobalSetting\n$dnsCGSetting.SuffixSearchList += "<node1domainname>","<node2domainname>"\n\nset-DnsClientGlobalSetting -SuffixSearchList $dnsCGSetting.SuffixSearchList\n\n\nClear-DnsClientCache\n</code></pre>\n<h4><a id=\"Configure_a_domainindependent_Windows_failover_cluster_197\"></a><strong>Configure a domain-independent Windows failover cluster</strong></h4>\n<p>Run the following command on Node1 as the new user that you created to create a domain-independent Windows failover cluster. If possible, RDP as the new user and run the command.</p>\n<p>New-Cluster -Name <clustername> -Node <ip address of node1>, <ip address of node2> -AdministrativeAccessPoint DNS -NoStorage -StaticAddress <ipaddress for on-premisessource.com,ipaddress for AWSDestination.com></p>\n<h3><a id=\"Set_up_the_prerequisites_for_an_Always_On_availability_group_203\"></a><strong>Set up the prerequisites for an Always On availability group</strong></h3>\n<p>Let’s configure our SQL Server Always On availability group, which is a robust high availability and disaster recovery solution in SQL Server.</p>\n<h4><a id=\"Configure_the_SQL_Server_Log_on_as_a_service_using_a_local_admin_user_on_both_replica_servers_207\"></a><strong>Configure the SQL Server Log on as a service using a local admin user on both replica servers</strong></h4>\n<p>Change the SQL Server service account’s log-on as a service to the local admin user you created in the preceding section on both nodes using the following PowerShell code (change the parameters accordingly). Note that this will restart the SQL services automatically. In this example, we use the testing user.</p>\n<pre><code class=\"lang-\">[System.Reflection.Assembly]::LoadWithPartialName('Microsoft.SqlServer.SqlWmiManagement')| Out-Null\n$smowmi = New-Object Microsoft.SqlServer.Management.Smo.Wmi.ManagedComputer "<hostname>"\n$wmisvc = $smowmi.Services | Where-Object {$_.Name -eq "SQLSERVERAGENT" -or $_.Name -eq "MSSQLSERVER"}\n$wmisvc.SetServiceAccount('<hostname>\\testing','xxx')\n</code></pre>\n<p>You can also do this in a graphical user interface using the <code>services.msc</code>console.</p>\n<h4><a id=\"Enable_the_Always_On_availability_group_feature_on_both_replica_servers_220\"></a><strong>Enable the Always On availability group feature on both replica servers</strong></h4>\n<p>Run the following commands on both nodes, changing the parameters accordingly. Note that the third command restarts SQL services:</p>\n<pre><code class=\"lang-\">Import-Module "SQLPS"\nEnable-SqlAlwaysOn -ServerInstance <"hostname"> -Force\nget-service -Name MSSQLSERVER,SQLSERVERAGENT|Restart-Service -Force\n</code></pre>\n<h4><a id=\"Create_the_login_master_key_certificate_and_endpoint_on_both_replica_servers_230\"></a><strong>Create the login, master key, certificate, and endpoint on both replica servers</strong></h4>\n<p>Turn on SQL authentication on both instances and restart them if you haven’t already. For information about changing authentication mode, refer to <a href=\"https://docs.microsoft.com/en-us/sql/database-engine/configure-windows/change-server-authentication-mode?view=sql-server-ver16\" target=\"_blank\">Change server authentication mode</a>. Run the following TSQL statements in SQL Server Management Studio on the corresponding node’s mentioned. Change the directory locations according to your environment.</p>\n<p>On Node1, run the following code to set up the certificate:</p>\n<pre><code class=\"lang-\">-- master key creation\nCREATE MASTER KEY ENCRYPTION BY PASSWORD = 'XXX';\n\n-- Certificate creation \nCREATE CERTIFICATE [cert_node1] WITH SUBJECT = 'CERT_SUB';\n\n-- Certificate backup \nBACKUP CERTIFICATE [cert_node1]\n TO FILE = 'C:\\TESTING\\CERT_node1.CER'\n \n-- Endpoint creation \nCREATE ENDPOINT [HADR] STATE = STARTED AS TCP (LISTENER_PORT = 5022 ) FOR DATA_MIRRORING ( ROLE = ALL, AUTHENTICATION = CERTIFICATE [cert_node1], ENCRYPTION = REQUIRED ALGORITHM AES);\n</code></pre>\n<p>On Node2, run the following code to set up the certificate:</p>\n<pre><code class=\"lang-\">-- master key creation*\nCREATE MASTER KEY ENCRYPTION BY PASSWORD = 'XXX';\n\n-- Certificate creation \nCREATE CERTIFICATE [cert_node2] WITH SUBJECT = 'CERT_SUB';\n\n--certificate backup \nBACKUP CERTIFICATE [cert_node2]\n TO FILE = 'C:\\TESTING\\CERT_node2.CER'\n \n--endpoint creation \nCREATE ENDPOINT [HADR] STATE = STARTED AS TCP (LISTENER_PORT = 5022 ) FOR DATA_MIRRORING ( ROLE = ALL, AUTHENTICATION = CERTIFICATE [cert_node2], ENCRYPTION = REQUIRED ALGORITHM AES);\n</code></pre>\n<p>Copy the certificates between nodes either manually or by running the following Windows PowerShell commands on Node1:</p>\n<pre><code class=\"lang-\">Copy-Item -Path \\\\EC2AMAZ-C1B4GVO\\c$\\testing\\cert_node1.cer -Destination \\\\RDSAMAZ-KLIN0HM\\c$\\testing\\\nCopy-Item -Path \\\\RDSAMAZ-KLIN0HM\\c$\\testing\\cert_node2.cer -Destination \\\\EC2AMAZ-C1B4GVO\\c$\\testing\\\n</code></pre>\n<p>On Node1, run the following code:</p>\n<pre><code class=\"lang-\">-- Login creation\n use master;\n\nCREATE LOGIN [aon_node2] WITH PASSWORD = 'XXX';\nCREATE USER [aon_node2] FOR LOGIN [aon_node2];\n\n-- Restore Certificate from node2\nCREATE CERTIFICATE [cert_node2]\nAUTHORIZATION aon_node2 FROM FILE = 'C:\\TESTING\\CERT_node2.CER'\n\nGRANT CONNECT ON ENDPOINT::[HADR] TO [aon_node2];\n</code></pre>\n<p>On Node2, run the following code:</p>\n<pre><code class=\"lang-\">-- Login creation\n use master;\n\nCREATE LOGIN [aon_node1] WITH PASSWORD = 'XXX';\nCREATE USER [aon_node1] FOR LOGIN [aon_node1];\n\n\n-- Certificate creation\nCREATE CERTIFICATE [cert_node1]\nAUTHORIZATION aon_node1 FROM FILE = 'C:\\TESTING\\CERT_node1.CER'\n\nGRANT CONNECT ON ENDPOINT::[HADR] TO [aon_node1];\n</code></pre>\n<h3><a id=\"Create_an_Always_On_availability_group_307\"></a><strong>Create an Always On availability group</strong></h3>\n<p>Run the following command on Node1 to create an Always On availability group. The file system directory structure of the database files that will be created on Node2 should be identical to Node1 in order for automatic seeding to work. If they’re different, you must manually prepare the secondary database. For more information, see <a href=\"https://docs.microsoft.com/en-us/sql/database-engine/availability-groups/windows/manually-prepare-a-secondary-database-for-an-availability-group-sql-server?view=sql-server-ver16\" target=\"_blank\">Prepare a secondary database for an Always On availability group</a>.</p>\n<p>Note that all SQL Server database files are stored on the <code>D:</code>drive by default, in the<code>D:\\rdsdbdata\\DATA</code>directory.</p>\n<p>If you create or alter the database file location to be anywhere other than the <code>D:</code>drive, then RDS Custom places the DB instance outside the support perimeter. For details, refer to <a href=\"https://docs.amazonaws.cn/en_us/AmazonRDS/latest/UserGuide/custom-troubleshooting.html\" target=\"_blank\">Troubleshooting DB issues for Amazon RDS Custom</a>.</p>\n<p>Modify the <code>availability group name</code>, <code>database name</code>, <code>replica value</code>, and <code>endpoint_url</code>value according to your environment.</p>\n<pre><code class=\"lang-\">USE [master]\nGO\nCREATE AVAILABILITY GROUP [<ag_name>]\nWITH (AUTOMATED_BACKUP_PREFERENCE = PRIMARY,\nDB_FAILOVER = OFF,\nDTC_SUPPORT = NONE,\nCLUSTER_TYPE = NONE,\nREQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 0)\nFOR DATABASE [<db_name>]\nREPLICA ON N'EC2AMAZ-C1B4GVO' WITH (\n ENDPOINT_URL = N'TCP://EC2AMAZ-C1B4GVO.OnPremSource.com:5022',\n FAILOVER_MODE = MANUAL, \n AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, \n BACKUP_PRIORITY = 50, \n SEEDING_MODE = AUTOMATIC, \n SECONDARY_ROLE(ALLOW_CONNECTIONS = NO)),\n N'RDSAMAZ-KLIN0HM' WITH (\n ENDPOINT_URL = N'TCP://RDSAMAZ-KLIN0HM.AWSDestination.com:5022',\n FAILOVER_MODE = MANUAL,\n AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,\n BACKUP_PRIORITY = 50, \n SEEDING_MODE = AUTOMATIC, \n SECONDARY_ROLE(ALLOW_CONNECTIONS = NO));\nGO\nALTER AVAILABILITY GROUP [<ag_name>] GRANT CREATE ANY DATABASE;\n</code></pre>\n<p>On Node2, run the following code :</p>\n<pre><code class=\"lang-\">ALTER AVAILABILITY GROUP [<ag_name>] JOIN WITH (CLUSTER_TYPE = NONE);\nALTER AVAILABILITY GROUP [<ag_name>] GRANT CREATE ANY DATABASE;\n</code></pre>\n<p>An Always On availability group from on-premises to Amazon RDS Custom for SQL Server is successfully established.</p>\n<p>The following screenshot shows Amazon EC2/on-premises replica as primary.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/771ba2457ff24bc4baa956686eff4f25_image.png\" alt=\"image.png\" /></p>\n<h3><a id=\"Migrate_the_onpremises_database_to_Amazon_RDS_Custom_for_SQL_Server_358\"></a><strong>Migrate the on-premises database to Amazon RDS Custom for SQL Server</strong></h3>\n<p>Up to this step, we have demonstrated the setup to replicate the database as is from on-premises to Amazon RDS Custom for SQL Server.</p>\n<p>In a typical migration scenario, you set this up and let it run until your actual cutover day approaches. When you’re ready for the migration, complete the following steps:</p>\n<ol>\n<li>Monitor the asynchronous data flow between Node 1 and Node2 using dynamic management views (DMVs). Query the DMV <a href=\"https://docs.microsoft.com/en-us/sql/relational-databases/system-dynamic-management-views/sys-dm-hadr-database-replica-states-transact-sql?view=sql-server-ver15\" target=\"_blank\">sys.dm_hadr_database_replica_states</a> for <code>last_commit_lsn</code>and <code>last_commit_time</code>on both nodes to get an estimation of how far the destination is behind. For more information about monitoring performance, refer to <a href=\"https://docs.microsoft.com/en-us/sql/database-engine/availability-groups/windows/monitor-performance-for-always-on-availability-groups?view=sql-server-ver15\" target=\"_blank\">Monitor performance for Always On availability groups</a>.</li>\n<li>Stop all incoming application traffic to Node 1 so no write activities are occurring.</li>\n<li>Until now, the availability mode for the database was set to asynchronous commit to gain better performance. Switch that to synchronous commit to help avoid data loss by running the following TSQL on Node1:</li>\n</ol>\n<pre><code class=\"lang-\">USE [master]\nGO\nALTER AVAILABILITY GROUP [<group-name>]\nMODIFY REPLICA ON N'<node1>' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT)\nGO\nUSE [master]\nGO\nALTER AVAILABILITY GROUP [<group-name>]\nMODIFY REPLICA ON N'<node2>' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT)\nGO\n</code></pre>\n<ol start=\"4\">\n<li>Repeat step 1 to revalidate and make sure RTO and RPO is met. At this point, we’re ready to perform the actual migration.</li>\n<li>Run the following TSQL on Node2 to migrate the database from on-premises to Amazon RDS Custom for SQL Server. This allows new read/write application connections to connect to the RDS Custom for SQL Server instance. Because we’re using domain-independent availability groups,<code>force_failover_allow_data_loss</code>is the only way to migrate the database.</li>\n</ol>\n<pre><code class=\"lang-\">USE master;\nGO\n\nALTER AVAILABILITY GROUP [<group_name>] FORCE_FAILOVER_ALLOW_DATA_LOSS\nGO\n</code></pre>\n<ol start=\"6\">\n<li>Redirect your application, dependent services, traffic by modifying your connection string to use the RDS Custom for SQL Server instance so that the write activities can resume from this instance.</li>\n</ol>\n<p>The following screenshot shows RDS Custom replica as primary.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/bdd680ce96204f4eb01e8573410d1031_image.png\" alt=\"image.png\" /></p>\n<h4><a id=\"Rollback_plan_398\"></a><strong>Rollback plan</strong></h4>\n<p>For any production change, it’s crucial to have a rollback plan. After the database migration from on-premises to Amazon RDS Custom for SQL Server is complete, data movement and synchronization will be suspended by default between the nodes. As a best practice, you should reestablish the synchronization back to on-premises by running the following TSQL on the on-premises node until you reach the cleanup phase so that you have an option to rollback if needed:</p>\n<pre><code class=\"lang-\">ALTER DATABASE [<db-name>] SET HADR RESUME;\nGO\n</code></pre>\n<h4><a id=\"Remove_the_onpremises_dependencies_407\"></a><strong>Remove the on-premises dependencies</strong></h4>\n<p>You can monitor your application and database performance for a period of time to ensure stable performance. When you’re ready to run independently on Amazon RDS Custom for SQL Server, remove the on-premises dependencies by running the following TSQL statements</p>\n<p>This removes the Always On database from the availability group. On Node2, run the following code:</p>\n<pre><code class=\"lang-\">USE [master]\nGO\nALTER AVAILABILITY GROUP [<group-name>] REMOVE DATABASE [<db-name>];\n</code></pre>\n<p>On both nodes, run the following code to drop the availability group completely:</p>\n<pre><code class=\"lang-\">DROP AVAILABILITY GROUP [<group-name>]\n</code></pre>\n<h4><a id=\"Decommission_the_onpremises_servers_425\"></a><strong>Decommission the on-premises servers</strong></h4>\n<p>Now that you have removed the on-premises dependencies of your RDS Custom for SQL Server instance, you can decommission the on-premises database, instance, or server accordingly. If you want high availability with RDS Custom for SQL Server, refer to <a href=\"https://aws.amazon.com/blogs/database/configure-high-availability-with-always-on-availability-groups-on-amazon-rds-custom-for-sql-server/\" target=\"_blank\">Configure high availability with Always On Availability Groups on Amazon RDS Custom for SQL Server</a>.</p>\n<h3><a id=\"Cleanup_429\"></a><strong>Cleanup</strong></h3>\n<p>To avoid incurring future charges, delete the resources you created as part of this post. You can clean up the following Amazon Web Services resources:</p>\n<ul>\n<li>Delete Amazon EC2 instance, refer to <a href=\"https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/terminating-instances.html\" target=\"_blank\">Terminate your instance</a></li>\n<li>Delete DB instance, refer to <a href=\"https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/USER_DeleteInstance.html\" target=\"_blank\">Deleting a DB instance</a></li>\n</ul>\n<h3><a id=\"Summary_436\"></a><strong>Summary</strong></h3>\n<p>SQL Server Always On availability groups provide a cost-effective high availability and disaster recovery feature. The domain-independent Always On availability group feature enables you to configure your SQL Server cluster without using Active Directory, which reduces the complexity during a hybrid cluster setup.</p>\n<p>In this post, we demonstrated a solution for migrating your on-premises SQL Server workload to Amazon RDS Custom for SQL Server using a domain-independent Always On availability group, which makes the whole migration strategy more simple, secure and cost-effective.</p>\n<p>Try out the solution and if you have any comments or questions, leave them in the comments section.</p>\n<h4><a id=\"About_the_authors_444\"></a><strong>About the authors</strong></h4>\n<p><img src=\"https://dev-media.amazoncloud.cn/14819cb49ac346f9811b2e7dde708e62_image.png\" alt=\"image.png\" /></p>\n<p><strong>Aravind Hariharaputran</strong> is Database Consultant with the Professional Services team at Amazon Web Services. He is passionate about databases in general with Microsoft SQL Server as his specialty. He helps build technical solutions that assist customers to migrate and optimize their on-premises database workload to the Amazon Web Services Cloud. He enjoys spending time with family and playing cricket.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/dbcdf1f96ee84f848a2e3a736f943281_image.png\" alt=\"image.png\" /></p>\n<p><strong>Alok Srivastava</strong> is Senior Database Consultant with Professional Services team at Amazon Web Services. He works as database specialist to help customers to architect and migrate their database solutions to Amazon Web Services.</p>\n"}
Migrate an on-premises SQL Server standalone workload to Amazon RDS Custom for SQL Server using domain-independent, Always On availability groups
海外精选

海外精选的内容汇集了全球优质的亚马逊云科技相关技术内容。同时,内容中提到的“AWS”
是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。

 0
0 0
0亚马逊云科技解决方案 基于行业客户应用场景及技术领域的解决方案
联系亚马逊云科技专家
亚马逊云科技解决方案
基于行业客户应用场景及技术领域的解决方案
联系专家

0
目录

 分享
分享 点赞
点赞 收藏
收藏 目录
目录立即注册,开启您的免费套餐
立即关注

亚马逊云开发者
公众号

User Group
公众号

亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
关于我们 
更多资源
开发者工具
更多支持
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
