{"value":"Architecting workloads to achieve your resiliency targets can be a balancing act. Firms designing for resilience on cloud often need to evaluate multiple factors before they can decide the most optimal architecture for their workloads. Example Corp has multiple applications with varying criticality, and each of their applications have different needs in terms of resiliency, complexity, and cost. They have many choices to architect their workloads for resiliency and cost, but which option suits their needs best? Will they have to make any sacrifices to implement one over another? How and why should they choose one pattern over another?\n\nTo help answer these questions, we’ll discuss the five resilience patterns in Figure 1 and the trade-offs to consider when implementing them: 1) design complexity, 2) cost to implement, 3) operational effort, 4) effort to secure, and 5) environmental impact. This will help you achieve varying levels of resiliency and make decisions about the most appropriate architecture for your needs.\n\n\n\nFigure 1. Resilience patterns and trade-offs\n\n\n#### **What is resiliency? Why does it matter?**\n\n\nThe [AWS Well-Architected Framework](https://aws.amazon.com/architecture/well-architected/) defines resilience as having “the capability to recover when stressed by load (more requests for service), attacks (either accidental through a bug, or deliberate through intention), and failure of any component in the workload’s components.”\n\nTo meet your business’ resilience requirements, consider the following core factors as you design your workloads:\n\n- **Design complexity** – Usually, the more complex your workload becomes, the more complicated your resilience requirements will be. Each individual workload component has to be resilient, and you’ll need to eliminate single points of failure across people, process, and technology elements.\n- **Cost to implement** – Costs often significantly increase when you implement higher resilience because there are new software and infrastructure components to operate.\n- **Operational effort** – Deploying and supporting highly resilient systems require more complex operational processes and advanced technical skills. Before you decide to implement higher resilience, evaluate your operational competency to confirm you have the required level of process maturity and skillsets.\n- **Effort to secure** – Security complexity is less directly correlated to resilience. However, there are generally more components to secure for highly resilient systems. [AWS Security best practices](https://aws.amazon.com/architecture/security-identity-compliance/) can help customers achieve their security objectives for such complex deployments.\n- **Environmental impact** – An increased deployment footprint for resilient systems might increase your consumption of cloud resources. However, you can use trade-offs like [approximate computing](https://en.wikipedia.org/wiki/Approximate_computing) and slower response times to reduce resource consumption.\n\n\n#### **P1 – Multi-AZ**\n\n\nP1 is a cloud-based architecture pattern (Figure 2) that introduces [Availability Zones (AZs)](https://aws.amazon.com/about-aws/global-infrastructure/regions_az/) into your architecture to increase your system’s resilience. The P1 pattern uses a Multi-AZ architecture where applications operate in multiple AZs within a single AWS Region. This allows your application to withstand AZ-level impacts.\n\nAs shown in Figure 2, Example Corp deploys their internal employee applications using the P1 pattern. These applications are low business impact and therefore have lower requirements for resiliency.\n\nExample Corp deploys these applications on [Amazon Elastic Compute Cloud (Amazon EC2)](http://aws.amazon.com/ec2/autoscaling), which uses health checks to automatically detect faults. If an AZ fails, [Amazon EC2 ](https://aws.amazon.com/cn/ec2/?trk=cndc-detail)prompts an [Amazon EC2 Auto Scaling](http://aws.amazon.com/ec2/autoscaling) group to recreate their application in another unaffected AZ.\n\n\n\nFigure 2. Multi-AZ deployment pattern (P1)\n\n***Trade-offs***\n\nP1 is low effort in several categories, but this comes at the expense of application recovery. If AZ is down, it will disrupt end users’ access to the application while the new resources are being re-provisioned in a new AZ. This is known as [bi-modal behavior](https://docs.aws.amazon.com/wellarchitected/latest/reliability-pillar/design-your-workload-to-withstand-component-failures.html).\n\n\n#### **P2 – Multi-AZ with static stability**\n\n\nP2 uses multiple AZs within a Region to increase resilience, but it uses static stability to prevent bimodal behavior. P2 uses static stability systems, which remain stable and operate in one mode irrespective of changes to their operating environment.\n\nAs shown in Figure 3, Example Corp has a customer-facing website that has a lower tolerance for downtime. Any time the website is down, it could result in lost revenue. Because of this, the website requires two EC2 instances that are provisioned within two AZs. This way, if an AZ becomes impaired, the website can continue operating and does not require Example Corp to detect the fault or launch new infrastructure.\n\nhttps://d2908q01vomqb2.cloudfront.net/fc074d501302eb2b93e2554793fcaf50b3bf7291/2022/06/01/Figure-3.-Multi-AZ-with-static-stability-pattern-P2.png\n\nFigure 3. Multi-AZ with static stability pattern (P2)\n\n##### **Trade-offs**\n\n\nP2 must be weighed against cost concerns. P1 is less expensive because it provisions less compute capacity and relies on launching new instances in case of a failure. However, P1’s bimodal behavior might affect your customers during large-scale events.\n\nYou could go further and deploy your workload to three AZs across the Region. This will reduce costs associated with over-provisioning because you only have to provision three instances versus the four we mentioned in our earlier example.\n\n\n#### **P3 – Application portfolio distribution**\n\n\nThe P3 pattern uses a multi-Region pattern to increase functional resilience. It distributes different critical applications in multiple Regions.\n\nExample Corp provides banking services like credit balance checks to consumers on multiple digital channels. These services are available to consumers via a mobile application, contact center, and web-based applications. If the Region fails where the mobile application is deployed, customers can still access services via the other channels deployed in other Regions. Regional disruptions are rare, but implementing this pattern ensures your users retain access to business-critical services during disruptions.\n\nhttps://d2908q01vomqb2.cloudfront.net/fc074d501302eb2b93e2554793fcaf50b3bf7291/2022/06/01/Figure-4.-Application-portfolio-distribution-pattern-P3.png\n\nFigure 4. Application portfolio distribution pattern (P3)\n\n***Trade-offs***\n\nOperating an application portfolio that spans multiple Regions requires significant operational planning and management. Isolated functional elements may depend on common downstream systems and data sources that are deployed in a single Region. Therefore, Region-wide events might still cause disruption; however, the impact surface area is significantly reduced.\n\n\n#### **P4 – Multi-AZ deployment (multi-Region disaster recovery)**\n\n\nExample Corp operates several business-critical services, such as the ability for consumers to make bank payments, that have very low tolerance for disruptions. Example Corp uses the following sub-patterns for these applications:\n\n- **Pilot Light** – This pattern works for applications that require RTO/RPO of 10s of minutes. Data is actively replicated and application infrastructure is pre-provisioned in the disaster recovery (DR) Region. Cost optimization is a key driver here because the application infrastructure is kept switched off and only switched on during the restore event.\n- **Warm Standby**– This pattern improves restore times significantly compared to pilot light by keeping your applications running in the DR Region but with a reduced capacity. Application infrastructure will be scaled up during a DR event but this can typically be automated with minimal manual effort. This pattern can achieve RTO/RPO of minutes if implemented correctly.\n\nThe [Disaster Recovery of Workloads on AWS: Recovery in the Cloud](https://docs.aws.amazon.com/whitepapers/latest/disaster-recovery-workloads-on-aws/disaster-recovery-workloads-on-aws.html) whitepaper documents these patterns in detail.\n\n***Trade-offs***\n\nRegional DR patterns increase deployment complexity because infrastructure changes need to be synchronized across Regions. Testing is also significantly more complex and should include scenarios such as losing a Region and traffic routing and management. Using Infrastructure as Code to automate deployments can help alleviate these issues.\n\n\n#### **P5 – Multi-Region active-active**\n\n\nExample Corp’s core banking and Customer Relationship Management applications have zero tolerance for Regional disruption. They use the P5 pattern for deploying these applications because it has an RTO of real-time and an RPO of near-zero data loss. This way they run their workload simultaneously in multiple Regions, which allows them to serve traffic from all Regions.\n\n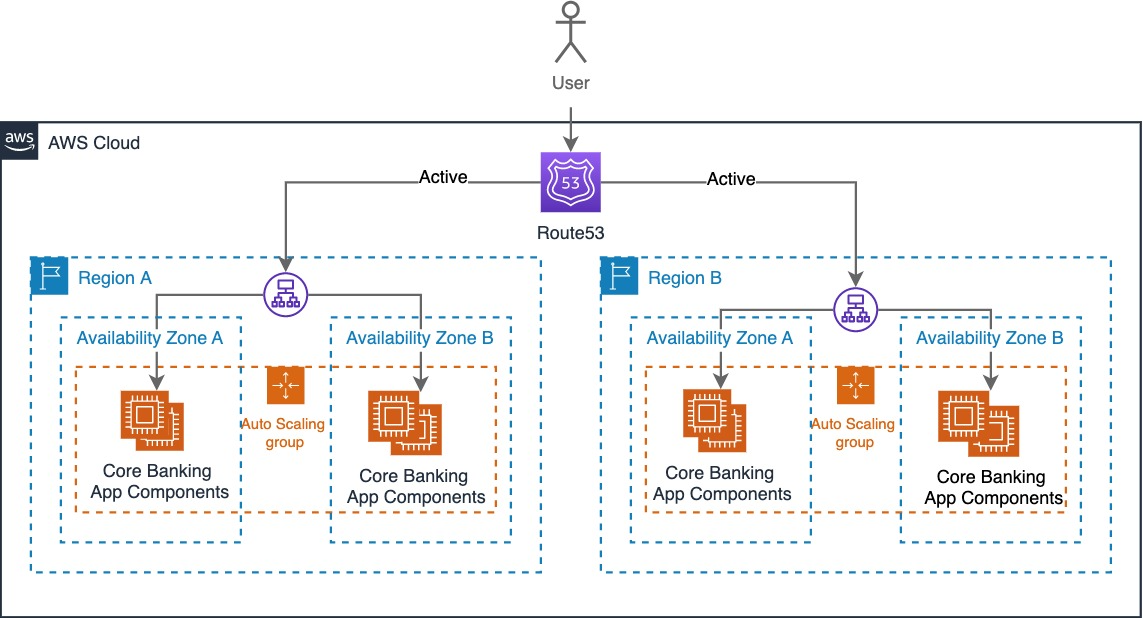\n\nFigure 5. Multi-Region active-active pattern (P5)\n\n***Trade-offs***\n\nMulti-active ecosystems are generally complex because they include multiple applications that collaborate to deliver required business services. If you implement this pattern, you’ll need to consider the fact that you’re introducing asynchronous replication for data across Regions and the [impact that has on data consistency](https://aws.amazon.com/blogs/architecture/disaster-recovery-dr-architecture-on-aws-part-iv-multi-site-active-active/).\n\nOperating this pattern requires a very high level of process maturity, so we recommend customers gradually build towards this pattern by starting initially with deployment patterns described earlier.\n\n\n#### **Conclusion**\n\n\nIn this blog post, we introduced five resilience patterns and the trade-offs to consider when implementing them. We showed you how Example Corp evaluated these options and how they applied to their business needs to help you decide on the most efficient architecture to implement.\n\n\n#### **Further reading**\n\n\n- [AWS Well Architected Framework – Resilience Pillar](https://docs.aws.amazon.com/wellarchitected/latest/reliability-pillar/welcome.html)\n- [Building Resilient Well-Architected Workloads Using AWS Resilience Hub](https://aws.amazon.com/blogs/architecture/building-resilient-well-architected-workloads-using-aws-resilience-hub/)\n- [Disaster Recovery of Workloads on AWS: Recovery in the Cloud](https://docs.aws.amazon.com/whitepapers/latest/disaster-recovery-workloads-on-aws/disaster-recovery-workloads-on-aws.html)\n- [Disaster Recovery (DR) Architecture on AWS, Architecture Blog series](https://aws.amazon.com/blogs/architecture/tag/disaster-recovery-series/)\n\n\n#### **Looking for more architecture content?**\n\n\n[AWS Architecture Center](https://aws.amazon.com/architecture/) provides reference architecture diagrams, vetted architecture solutions, [Well-Architected](https://aws.amazon.com/architecture/well-architected/) best practices, patterns, icons, and more!\n\n\n\n\n#### **Haresh Nandwani**\n\n\nHaresh is a Senior Solutions Architect working within AWS UK Financial Services team. He helps customers in their journey towards designing, building, and operating well architected systems on AWS.\n\n\n\n\n#### **Lewis Taylor**\n\n\nLewis is a Solution Architect working within AWS UK Financial Service team. He helps Financial Services customers and partners accelerate their cloud journey and use the cloud to transform their business.\n\n\n\n\n#### **Bonnie McClure**\n\n\nBonnie is an editor specializing in creating accessible, engaging content for all audiences and platforms. She is dedicated to delivering comprehensive editorial guidance to provide a seamless user experience. When she's not advocating for the Oxford comma, you can find her spending time with her two large dogs, practicing her sewing skills, or testing out new recipes in the kitchen.","render":"<p>Architecting workloads to achieve your resiliency targets can be a balancing act. Firms designing for resilience on cloud often need to evaluate multiple factors before they can decide the most optimal architecture for their workloads. Example Corp has multiple applications with varying criticality, and each of their applications have different needs in terms of resiliency, complexity, and cost. They have many choices to architect their workloads for resiliency and cost, but which option suits their needs best? Will they have to make any sacrifices to implement one over another? How and why should they choose one pattern over another?</p>\n<p>To help answer these questions, we’ll discuss the five resilience patterns in Figure 1 and the trade-offs to consider when implementing them: 1) design complexity, 2) cost to implement, 3) operational effort, 4) effort to secure, and 5) environmental impact. This will help you achieve varying levels of resiliency and make decisions about the most appropriate architecture for your needs.</p>\n<p><img src=\\"https://dev-media.amazoncloud.cn/9b8bfa16dd3a43c69d50e9ea6615502f_image.png\\" alt=\\"image.png\\" /></p>\n<p>Figure 1. Resilience patterns and trade-offs</p>\n<h4><a id=\\"What_is_resiliency_Why_does_it_matter_9\\"></a><strong>What is resiliency? Why does it matter?</strong></h4>\\n<p>The <a href=\\"https://aws.amazon.com/architecture/well-architected/\\" target=\\"_blank\\">AWS Well-Architected Framework</a> defines resilience as having “the capability to recover when stressed by load (more requests for service), attacks (either accidental through a bug, or deliberate through intention), and failure of any component in the workload’s components.”</p>\\n<p>To meet your business’ resilience requirements, consider the following core factors as you design your workloads:</p>\n<ul>\\n<li><strong>Design complexity</strong> – Usually, the more complex your workload becomes, the more complicated your resilience requirements will be. Each individual workload component has to be resilient, and you’ll need to eliminate single points of failure across people, process, and technology elements.</li>\\n<li><strong>Cost to implement</strong> – Costs often significantly increase when you implement higher resilience because there are new software and infrastructure components to operate.</li>\\n<li><strong>Operational effort</strong> – Deploying and supporting highly resilient systems require more complex operational processes and advanced technical skills. Before you decide to implement higher resilience, evaluate your operational competency to confirm you have the required level of process maturity and skillsets.</li>\\n<li><strong>Effort to secure</strong> – Security complexity is less directly correlated to resilience. However, there are generally more components to secure for highly resilient systems. <a href=\\"https://aws.amazon.com/architecture/security-identity-compliance/\\" target=\\"_blank\\">AWS Security best practices</a> can help customers achieve their security objectives for such complex deployments.</li>\\n<li><strong>Environmental impact</strong> – An increased deployment footprint for resilient systems might increase your consumption of cloud resources. However, you can use trade-offs like <a href=\\"https://en.wikipedia.org/wiki/Approximate_computing\\" target=\\"_blank\\">approximate computing</a> and slower response times to reduce resource consumption.</li>\\n</ul>\n<h4><a id=\\"P1__MultiAZ_23\\"></a><strong>P1 – Multi-AZ</strong></h4>\\n<p>P1 is a cloud-based architecture pattern (Figure 2) that introduces <a href=\\"https://aws.amazon.com/about-aws/global-infrastructure/regions_az/\\" target=\\"_blank\\">Availability Zones (AZs)</a> into your architecture to increase your system’s resilience. The P1 pattern uses a Multi-AZ architecture where applications operate in multiple AZs within a single AWS Region. This allows your application to withstand AZ-level impacts.</p>\\n<p>As shown in Figure 2, Example Corp deploys their internal employee applications using the P1 pattern. These applications are low business impact and therefore have lower requirements for resiliency.</p>\n<p>Example Corp deploys these applications on <a href=\\"http://aws.amazon.com/ec2/autoscaling\\" target=\\"_blank\\">Amazon Elastic Compute Cloud (Amazon EC2)</a>, which uses health checks to automatically detect faults. If an AZ fails, [Amazon EC2 ](https://aws.amazon.com/cn/ec2/?trk=cndc-detail)prompts an <a href=\\"http://aws.amazon.com/ec2/autoscaling\\" target=\\"_blank\\">Amazon EC2 Auto Scaling</a> group to recreate their application in another unaffected AZ.</p>\\n<p><img src=\\"https://dev-media.amazoncloud.cn/1d10d71de96841b2bbd8e444f90e9caa_image.png\\" alt=\\"image.png\\" /></p>\n<p>Figure 2. Multi-AZ deployment pattern (P1)</p>\n<p><em><strong>Trade-offs</strong></em></p>\n<p>P1 is low effort in several categories, but this comes at the expense of application recovery. If AZ is down, it will disrupt end users’ access to the application while the new resources are being re-provisioned in a new AZ. This is known as <a href=\\"https://docs.aws.amazon.com/wellarchitected/latest/reliability-pillar/design-your-workload-to-withstand-component-failures.html\\" target=\\"_blank\\">bi-modal behavior</a>.</p>\\n<h4><a id=\\"P2__MultiAZ_with_static_stability_41\\"></a><strong>P2 – Multi-AZ with static stability</strong></h4>\\n<p>P2 uses multiple AZs within a Region to increase resilience, but it uses static stability to prevent bimodal behavior. P2 uses static stability systems, which remain stable and operate in one mode irrespective of changes to their operating environment.</p>\n<p>As shown in Figure 3, Example Corp has a customer-facing website that has a lower tolerance for downtime. Any time the website is down, it could result in lost revenue. Because of this, the website requires two EC2 instances that are provisioned within two AZs. This way, if an AZ becomes impaired, the website can continue operating and does not require Example Corp to detect the fault or launch new infrastructure.</p>\n<p>https://d2908q01vomqb2.cloudfront.net/fc074d501302eb2b93e2554793fcaf50b3bf7291/2022/06/01/Figure-3.-Multi-AZ-with-static-stability-pattern-P2.png</p>\n<p>Figure 3. Multi-AZ with static stability pattern (P2)</p>\n<h5><a id=\\"Tradeoffs_52\\"></a><strong>Trade-offs</strong></h5>\\n<p>P2 must be weighed against cost concerns. P1 is less expensive because it provisions less compute capacity and relies on launching new instances in case of a failure. However, P1’s bimodal behavior might affect your customers during large-scale events.</p>\n<p>You could go further and deploy your workload to three AZs across the Region. This will reduce costs associated with over-provisioning because you only have to provision three instances versus the four we mentioned in our earlier example.</p>\n<h4><a id=\\"P3__Application_portfolio_distribution_60\\"></a><strong>P3 – Application portfolio distribution</strong></h4>\\n<p>The P3 pattern uses a multi-Region pattern to increase functional resilience. It distributes different critical applications in multiple Regions.</p>\n<p>Example Corp provides banking services like credit balance checks to consumers on multiple digital channels. These services are available to consumers via a mobile application, contact center, and web-based applications. If the Region fails where the mobile application is deployed, customers can still access services via the other channels deployed in other Regions. Regional disruptions are rare, but implementing this pattern ensures your users retain access to business-critical services during disruptions.</p>\n<p>https://d2908q01vomqb2.cloudfront.net/fc074d501302eb2b93e2554793fcaf50b3bf7291/2022/06/01/Figure-4.-Application-portfolio-distribution-pattern-P3.png</p>\n<p>Figure 4. Application portfolio distribution pattern (P3)</p>\n<p><em><strong>Trade-offs</strong></em></p>\n<p>Operating an application portfolio that spans multiple Regions requires significant operational planning and management. Isolated functional elements may depend on common downstream systems and data sources that are deployed in a single Region. Therefore, Region-wide events might still cause disruption; however, the impact surface area is significantly reduced.</p>\n<h4><a id=\\"P4__MultiAZ_deployment_multiRegion_disaster_recovery_76\\"></a><strong>P4 – Multi-AZ deployment (multi-Region disaster recovery)</strong></h4>\\n<p>Example Corp operates several business-critical services, such as the ability for consumers to make bank payments, that have very low tolerance for disruptions. Example Corp uses the following sub-patterns for these applications:</p>\n<ul>\\n<li><strong>Pilot Light</strong> – This pattern works for applications that require RTO/RPO of 10s of minutes. Data is actively replicated and application infrastructure is pre-provisioned in the disaster recovery (DR) Region. Cost optimization is a key driver here because the application infrastructure is kept switched off and only switched on during the restore event.</li>\\n<li><strong>Warm Standby</strong>– This pattern improves restore times significantly compared to pilot light by keeping your applications running in the DR Region but with a reduced capacity. Application infrastructure will be scaled up during a DR event but this can typically be automated with minimal manual effort. This pattern can achieve RTO/RPO of minutes if implemented correctly.</li>\\n</ul>\n<p>The <a href=\\"https://docs.aws.amazon.com/whitepapers/latest/disaster-recovery-workloads-on-aws/disaster-recovery-workloads-on-aws.html\\" target=\\"_blank\\">Disaster Recovery of Workloads on AWS: Recovery in the Cloud</a> whitepaper documents these patterns in detail.</p>\\n<p><em><strong>Trade-offs</strong></em></p>\n<p>Regional DR patterns increase deployment complexity because infrastructure changes need to be synchronized across Regions. Testing is also significantly more complex and should include scenarios such as losing a Region and traffic routing and management. Using Infrastructure as Code to automate deployments can help alleviate these issues.</p>\n<h4><a id=\\"P5__MultiRegion_activeactive_91\\"></a><strong>P5 – Multi-Region active-active</strong></h4>\\n<p>Example Corp’s core banking and Customer Relationship Management applications have zero tolerance for Regional disruption. They use the P5 pattern for deploying these applications because it has an RTO of real-time and an RPO of near-zero data loss. This way they run their workload simultaneously in multiple Regions, which allows them to serve traffic from all Regions.</p>\n<p><img src=\\"https://dev-media.amazoncloud.cn/d4028d34f09b4b0f91869386c1b39de0_image.png\\" alt=\\"image.png\\" /></p>\n<p>Figure 5. Multi-Region active-active pattern (P5)</p>\n<p><em><strong>Trade-offs</strong></em></p>\n<p>Multi-active ecosystems are generally complex because they include multiple applications that collaborate to deliver required business services. If you implement this pattern, you’ll need to consider the fact that you’re introducing asynchronous replication for data across Regions and the <a href=\\"https://aws.amazon.com/blogs/architecture/disaster-recovery-dr-architecture-on-aws-part-iv-multi-site-active-active/\\" target=\\"_blank\\">impact that has on data consistency</a>.</p>\\n<p>Operating this pattern requires a very high level of process maturity, so we recommend customers gradually build towards this pattern by starting initially with deployment patterns described earlier.</p>\n<h4><a id=\\"Conclusion_107\\"></a><strong>Conclusion</strong></h4>\\n<p>In this blog post, we introduced five resilience patterns and the trade-offs to consider when implementing them. We showed you how Example Corp evaluated these options and how they applied to their business needs to help you decide on the most efficient architecture to implement.</p>\n<h4><a id=\\"Further_reading_113\\"></a><strong>Further reading</strong></h4>\\n<ul>\\n<li><a href=\\"https://docs.aws.amazon.com/wellarchitected/latest/reliability-pillar/welcome.html\\" target=\\"_blank\\">AWS Well Architected Framework – Resilience Pillar</a></li>\\n<li><a href=\\"https://aws.amazon.com/blogs/architecture/building-resilient-well-architected-workloads-using-aws-resilience-hub/\\" target=\\"_blank\\">Building Resilient Well-Architected Workloads Using AWS Resilience Hub</a></li>\\n<li><a href=\\"https://docs.aws.amazon.com/whitepapers/latest/disaster-recovery-workloads-on-aws/disaster-recovery-workloads-on-aws.html\\" target=\\"_blank\\">Disaster Recovery of Workloads on AWS: Recovery in the Cloud</a></li>\\n<li><a href=\\"https://aws.amazon.com/blogs/architecture/tag/disaster-recovery-series/\\" target=\\"_blank\\">Disaster Recovery (DR) Architecture on AWS, Architecture Blog series</a></li>\\n</ul>\n<h4><a id=\\"Looking_for_more_architecture_content_122\\"></a><strong>Looking for more architecture content?</strong></h4>\\n<p><a href=\\"https://aws.amazon.com/architecture/\\" target=\\"_blank\\">AWS Architecture Center</a> provides reference architecture diagrams, vetted architecture solutions, <a href=\\"https://aws.amazon.com/architecture/well-architected/\\" target=\\"_blank\\">Well-Architected</a> best practices, patterns, icons, and more!</p>\\n<p><img src=\\"https://dev-media.amazoncloud.cn/cb028f60b6d0425c90b5dbfe456a9a79_image.png\\" alt=\\"image.png\\" /></p>\n<h4><a id=\\"Haresh_Nandwani_130\\"></a><strong>Haresh Nandwani</strong></h4>\\n<p>Haresh is a Senior Solutions Architect working within AWS UK Financial Services team. He helps customers in their journey towards designing, building, and operating well architected systems on AWS.</p>\n<p><img src=\\"https://dev-media.amazoncloud.cn/1f52e07ac6c841eb9c22473d174b5b99_image.png\\" alt=\\"image.png\\" /></p>\n<h4><a id=\\"Lewis_Taylor_138\\"></a><strong>Lewis Taylor</strong></h4>\\n<p>Lewis is a Solution Architect working within AWS UK Financial Service team. He helps Financial Services customers and partners accelerate their cloud journey and use the cloud to transform their business.</p>\n<p><img src=\\"https://dev-media.amazoncloud.cn/eb6e373712aa4eaab34de4a7c72e7a52_image.png\\" alt=\\"image.png\\" /></p>\n<h4><a id=\\"Bonnie_McClure_146\\"></a><strong>Bonnie McClure</strong></h4>\\n<p>Bonnie is an editor specializing in creating accessible, engaging content for all audiences and platforms. She is dedicated to delivering comprehensive editorial guidance to provide a seamless user experience. When she’s not advocating for the Oxford comma, you can find her spending time with her two large dogs, practicing her sewing skills, or testing out new recipes in the kitchen.</p>\n"}
Understand resiliency patterns and trade-offs to architect efficiently in the cloud
海外精选

海外精选的内容汇集了全球优质的亚马逊云科技相关技术内容。同时,内容中提到的“AWS”
是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。

 0
0 0
0亚马逊云科技解决方案 基于行业客户应用场景及技术领域的解决方案
联系亚马逊云科技专家
亚马逊云科技解决方案
基于行业客户应用场景及技术领域的解决方案
联系专家

0
目录

 分享
分享 点赞
点赞 收藏
收藏 目录
目录立即注册,开启您的免费套餐
立即关注

亚马逊云开发者
公众号

User Group
公众号

亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
关于我们 
更多资源
开发者工具
更多支持
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
