{"value":"At last week’s ++[ACM Symposium on Operating Systems Principles](https://sosp2021.mpi-sws.org/)++ (SOSP), my colleagues at Amazon Web Services and I won a best-paper award for our ++[work](https://www.amazon.science/publications/using-lightweight-formal-methods-to-validate-a-key-value-storage-node-in-amazon-s3)++ using automated reasoning to validate that ShardStore — our new S3 storage node microservice — will do what it’s supposed to. \n\nAmazon Simple Storage Service (S3) is our fundamental object storage service — fast, cheap, and reliable. ShardStore is the service we run on our storage hardware, responsible for durably storing S3 object data. It’s a ground-up re-thinking of how we store and access data at the lowest level of S3. Because ShardStore is essential for the reliability of S3, it’s critical that it is free from bugs.\n\nFormal verification involves mathematically specifying the important properties of our software and formally proving that our systems never violate those specifications — in other words, mathematically proving the absence of bugs. Automated reasoning is a way to find those proofs automatically.\n\n\n\nAn example of the ShardStore deletion procedure. Deleting the second data chunk in extent 18 (grey box) requires copying the other three chunks to different extents (extents 19 and 20) and resetting the write pointer for extent 18. The log-structured merge-tree itself is also stored on disk (in this case, in extent 17). See below for details.\n\nTraditionally, formal verification comes with high overhead, requiring up to 10 times as much effort as building the system being verified. That’s just not practical for a system as large as S3.\n\nFor ShardStore, we instead developed a new lightweight automated-reasoning approach that gives us nearly all of the benefits of traditional formal proofs but with far lower overhead. \n\nOur methods found 16 bugs in the ShardStore code that would have required time-consuming and labor-intensive testing to find otherwise — if they could have been found at all. And with our method, specifying the software properties to be verified increased the ShardStore codebase by only about 14% — versus the two- to tenfold increases typical of other formal-verification approaches.\n\nOur method also allows the specifications to be written in the same language as the code — in this case, Rust. That allows developers to write new specifications themselves whenever they extend the functionality of the code. Initially, experts in formal verification wrote the specifications for ShardStore. But as the project has progressed, software engineers have taken over that responsibility. At this point, 18% of the ShardStore specifications have been written by developers.\n\n#### **Reference models**\n\nOne of the central concepts in our approach is that of reference models, simplified instantiations of program components that can be used to track program state under different input conditions.\n\nFor instance, storage systems often use log-structured merge-trees (LSMTs), a sophisticated data structure designed to apportion data between memory and different tiers of storage, with protocols for transferring data that take advantage of the different storage media to maximize efficiency.\n\nThe state of an LSMT, however — data locations and the record of data access patterns — can be modeled using a simple hash table. A hash table can thus serve as a reference model for the tree.\n\nIn our approach, reference models are specified using executable code. Code verification is then a matter of ensuring that the state of a component instantiated in the code matches that of the reference model, for arbitrary inputs. In practice, we found that specifying reference models required, on average, about 1% as much code as the actual component implementations.\n\n#### **Dependency tracking**\n\nShardStore uses LSMTs to track and update data locations. Each object stored by ShardStore is divided into chunks, and the chunks are written to extents, which are contiguous regions of physical storage on a disk. A typical disk has tens of thousands of extents. Writes within each extent are sequential, tracked by a write pointer that defines the next valid write position.\n\nThe simplicity of this model makes data writes very efficient. But it does mean that data chunks within an extent can’t be deleted individually. Deleting a chunk from an extent requires transferring all the other chunks in the extent elsewhere and then moving the write pointer back to the beginning of the extent.\n\nThe sequence of procedures required to write a single chunk of data using ShardStore — the updating of the merge-tree, the writing of the chunk, the incrementation of the write pointer, and so on — create sets of dependencies between successive write operations. For instance, the position of the write pointer within an extent depends on the last write performed within that extent.\n\n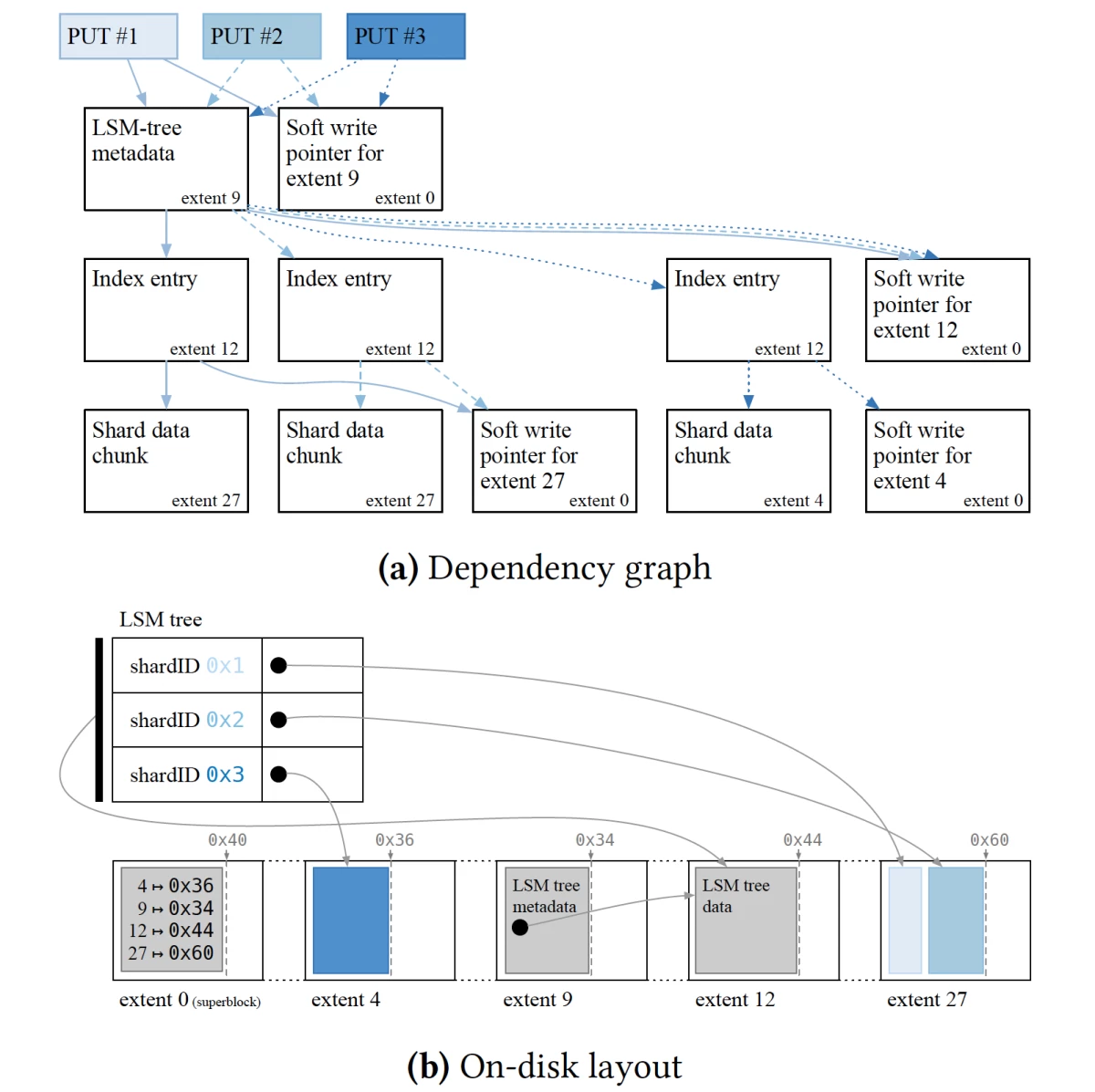\n\nThe dependency graph for a sequence of S3 PUT (write) operations, together with the state of the LSM tree and the locations of the data on-disk after the operations have executed.\n\nOur approach requires that we track dependencies across successive operations, which we do by constructing a dependency graph on the fly. ShardStore uses the dependency graph to decide how to most efficiently write data to disk while still remaining consistent when recovering from crashes. We use formal verification to check that the system always constructs these graphs correctly and so always remains consistent.\n\n#### **Test procedures**\n\nIn our paper, we describe a range of tests, beyond crash consistency, that our method enables, such as concurrent-execution tests and tests of the serializers that map the separate elements of a data structure to sequential locations in memory or storage.\n\nWe also describe some of our optimizations to ensure that our verification is thorough. For instance, our method generates random sequences of inputs to test for specification violations. If a violation is detected, the method systematically pares down the input sequence to identify which specific input or inputs caused the error.\n\nWe also bias the random-input selector so that it selects inputs that target the same storage pathways, to maximize the likelihood of detecting an error. If each input read from or wrote to a different object, for instance, there would be no risk of encountering a data inconsistency.\n\nWe use our lightweight automated-reasoning techniques to validate every single deployment of ShardStore. Before any change reaches production, we check its behavior in hundreds of millions of scenarios by running our automated tools using ++[AWS Batch](https://aws.amazon.com/batch/)++. \n\nTo support this type of scalable checking, we developed and open-sourced the new ++[Shuttle ](https://github.com/awslabs/shuttle)++ model checker for Rust code, which we use to validate concurrency properties of ShardStore. Together, these approaches provide a continuous and automated correctness mechanism for one of S3’s most important microservices.\n\nABOUT THE AUTHOR\n\n#### **[James Bornholt](https://www.amazon.science/author/james-bornholt)**\n\nJames Bornholt is an Amazon Visiting Academic and an assistant professor of computer science at the University of Texas at Austin.\n\n\n\n\n\n\n\n\n\n\n","render":"<p>At last week’s <ins><a href=\"https://sosp2021.mpi-sws.org/\" target=\"_blank\">ACM Symposium on Operating Systems Principles</a></ins> (SOSP), my colleagues at Amazon Web Services and I won a best-paper award for our <ins><a href=\"https://www.amazon.science/publications/using-lightweight-formal-methods-to-validate-a-key-value-storage-node-in-amazon-s3\" target=\"_blank\">work</a></ins> using automated reasoning to validate that ShardStore — our new S3 storage node microservice — will do what it’s supposed to.</p>\n<p>Amazon Simple Storage Service (S3) is our fundamental object storage service — fast, cheap, and reliable. ShardStore is the service we run on our storage hardware, responsible for durably storing S3 object data. It’s a ground-up re-thinking of how we store and access data at the lowest level of S3. Because ShardStore is essential for the reliability of S3, it’s critical that it is free from bugs.</p>\n<p>Formal verification involves mathematically specifying the important properties of our software and formally proving that our systems never violate those specifications — in other words, mathematically proving the absence of bugs. Automated reasoning is a way to find those proofs automatically.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/b46082ed1af94766b8dddd96e2327471_%E4%B8%8B%E8%BD%BD%20%281%29.gif\" alt=\"下载 1.gif\" /></p>\n<p>An example of the ShardStore deletion procedure. Deleting the second data chunk in extent 18 (grey box) requires copying the other three chunks to different extents (extents 19 and 20) and resetting the write pointer for extent 18. The log-structured merge-tree itself is also stored on disk (in this case, in extent 17). See below for details.</p>\n<p>Traditionally, formal verification comes with high overhead, requiring up to 10 times as much effort as building the system being verified. That’s just not practical for a system as large as S3.</p>\n<p>For ShardStore, we instead developed a new lightweight automated-reasoning approach that gives us nearly all of the benefits of traditional formal proofs but with far lower overhead.</p>\n<p>Our methods found 16 bugs in the ShardStore code that would have required time-consuming and labor-intensive testing to find otherwise — if they could have been found at all. And with our method, specifying the software properties to be verified increased the ShardStore codebase by only about 14% — versus the two- to tenfold increases typical of other formal-verification approaches.</p>\n<p>Our method also allows the specifications to be written in the same language as the code — in this case, Rust. That allows developers to write new specifications themselves whenever they extend the functionality of the code. Initially, experts in formal verification wrote the specifications for ShardStore. But as the project has progressed, software engineers have taken over that responsibility. At this point, 18% of the ShardStore specifications have been written by developers.</p>\n<h4><a id=\"Reference_models_18\"></a><strong>Reference models</strong></h4>\n<p>One of the central concepts in our approach is that of reference models, simplified instantiations of program components that can be used to track program state under different input conditions.</p>\n<p>For instance, storage systems often use log-structured merge-trees (LSMTs), a sophisticated data structure designed to apportion data between memory and different tiers of storage, with protocols for transferring data that take advantage of the different storage media to maximize efficiency.</p>\n<p>The state of an LSMT, however — data locations and the record of data access patterns — can be modeled using a simple hash table. A hash table can thus serve as a reference model for the tree.</p>\n<p>In our approach, reference models are specified using executable code. Code verification is then a matter of ensuring that the state of a component instantiated in the code matches that of the reference model, for arbitrary inputs. In practice, we found that specifying reference models required, on average, about 1% as much code as the actual component implementations.</p>\n<h4><a id=\"Dependency_tracking_28\"></a><strong>Dependency tracking</strong></h4>\n<p>ShardStore uses LSMTs to track and update data locations. Each object stored by ShardStore is divided into chunks, and the chunks are written to extents, which are contiguous regions of physical storage on a disk. A typical disk has tens of thousands of extents. Writes within each extent are sequential, tracked by a write pointer that defines the next valid write position.</p>\n<p>The simplicity of this model makes data writes very efficient. But it does mean that data chunks within an extent can’t be deleted individually. Deleting a chunk from an extent requires transferring all the other chunks in the extent elsewhere and then moving the write pointer back to the beginning of the extent.</p>\n<p>The sequence of procedures required to write a single chunk of data using ShardStore — the updating of the merge-tree, the writing of the chunk, the incrementation of the write pointer, and so on — create sets of dependencies between successive write operations. For instance, the position of the write pointer within an extent depends on the last write performed within that extent.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/57c5908a8fa74d8a8adaeeae7b58ef93_image.png\" alt=\"image.png\" /></p>\n<p>The dependency graph for a sequence of S3 PUT (write) operations, together with the state of the LSM tree and the locations of the data on-disk after the operations have executed.</p>\n<p>Our approach requires that we track dependencies across successive operations, which we do by constructing a dependency graph on the fly. ShardStore uses the dependency graph to decide how to most efficiently write data to disk while still remaining consistent when recovering from crashes. We use formal verification to check that the system always constructs these graphs correctly and so always remains consistent.</p>\n<h4><a id=\"Test_procedures_42\"></a><strong>Test procedures</strong></h4>\n<p>In our paper, we describe a range of tests, beyond crash consistency, that our method enables, such as concurrent-execution tests and tests of the serializers that map the separate elements of a data structure to sequential locations in memory or storage.</p>\n<p>We also describe some of our optimizations to ensure that our verification is thorough. For instance, our method generates random sequences of inputs to test for specification violations. If a violation is detected, the method systematically pares down the input sequence to identify which specific input or inputs caused the error.</p>\n<p>We also bias the random-input selector so that it selects inputs that target the same storage pathways, to maximize the likelihood of detecting an error. If each input read from or wrote to a different object, for instance, there would be no risk of encountering a data inconsistency.</p>\n<p>We use our lightweight automated-reasoning techniques to validate every single deployment of ShardStore. Before any change reaches production, we check its behavior in hundreds of millions of scenarios by running our automated tools using <ins><a href=\"https://aws.amazon.com/batch/\" target=\"_blank\">AWS Batch</a></ins>.</p>\n<p>To support this type of scalable checking, we developed and open-sourced the new <ins><a href=\"https://github.com/awslabs/shuttle\" target=\"_blank\">Shuttle </a></ins> model checker for Rust code, which we use to validate concurrency properties of ShardStore. Together, these approaches provide a continuous and automated correctness mechanism for one of S3’s most important microservices.</p>\n<p>ABOUT THE AUTHOR</p>\n<h4><a id=\"James_Bornholthttpswwwamazonscienceauthorjamesbornholt_56\"></a><strong><a href=\"https://www.amazon.science/author/james-bornholt\" target=\"_blank\">James Bornholt</a></strong></h4>\n<p>James Bornholt is an Amazon Visiting Academic and an assistant professor of computer science at the University of Texas at Austin.</p>\n"}
Amazon team wins best-paper award for work on automated reasoning
海外精选

海外精选的内容汇集了全球优质的亚马逊云科技相关技术内容。同时,内容中提到的“AWS”
是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。

 0
0 0
0亚马逊云科技解决方案 基于行业客户应用场景及技术领域的解决方案
联系亚马逊云科技专家
亚马逊云科技解决方案
基于行业客户应用场景及技术领域的解决方案
联系专家

0
目录

 分享
分享 点赞
点赞 收藏
收藏 目录
目录立即注册,开启您的免费套餐
立即关注

亚马逊云开发者
公众号

User Group
公众号

亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
关于我们 
更多资源
开发者工具
更多支持
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
