{"value":"The prevalence and success of machine learning have given rise to services that enable customers to train machine learning models in the cloud. In one scenario, a customer would upload training data to a cloud-based service and receive a trained model in return.\n\n*Homomorphic encryption* (HE), a technology that allows computation on encrypted data, would give this procedure an extra layer of security. With HE, a customer would upload encrypted training data, and the service would use the encrypted data to directly produce an encrypted machine learning model, which only the customer could then decrypt.\n\nAt the 2020 Workshop on Encrypted Computing and Applied Homomorphic Cryptography, we presented a ++[paper](https://www.amazon.science/publications/a-low-depth-homomorphic-circuit-for-logistic-regression-model-training)++ exploring the application of homomorphic encryption to logistic regression, a statistical model used for myriad machine learning applications, from genomics to tax compliance. Our paper shows how to train logistic-regression models on encrypted data six times as fast as prior work.\n\n\n#### **Homomorphic encryption**\n\n\n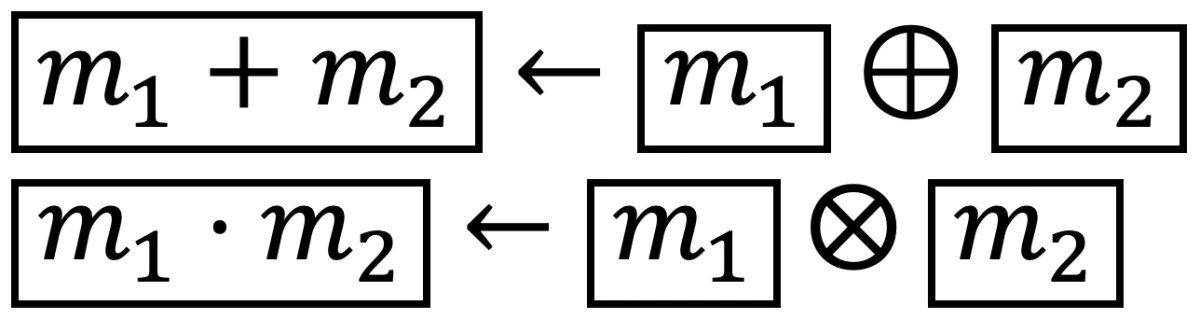\n\nHomomorphic encryption provides an application programming interface (API) for evaluating functions on encrypted data. We refer to a message as m and its encryption as m with a box around it. Two of the operations in this API are the HE versions of addition and multiplication, which we present at right. The inputs are encrypted values, and the output is the encryption of the sum or product of the plaintext values. \n\n\n\n\n\nA circuit with a multiplicative depth of three.\n\nThe eval operation takes a description of an arbitrary function *ƒ* as a circuit *ƒ*-hat (*ƒ* with a circumflex accent above it) expressed using only the HE versions of addition and multiplication, as in the example at left. Given *ƒ*-hat and an encrypted input, eval produces an encryption of the output of evaluating *ƒ* on the input *m*.\n\nFor example, to evaluate *ƒ(x) = x^4^ + 2* on encrypted data, we could use the circuit *ƒ~1~*-hat at right. This would be to use *ƒ~1~*-hat and the encrypted version of x as the inputs to the eval operation and *x^4^ + 2* as *ƒ(m)*.\n\n\n#### **Multiplicative depth**\n\n\n\n\nA circuit with a multiplicative depth of two.\n\nThe efficiency of the *eval* operation depends on a property called *multiplicative depth*, the maximum number of multiplications along any path through a circuit. In the example at right, *ƒ~1~*-hat has a multiplicative depth of three, since there is a path that contains three multiplications but no path that has more than three multiplications. However, this is not the most efficient circuit for computing *ƒ(x) = x^4^ + 2* .\n\nConsider, instead, the circuit at left. This circuit also computes *x^4^ + 2* but has a multiplicative depth of only two. It is therefore more efficient to evaluate *ƒ~2~*-hat than to evaluate *ƒ~1~*-hat.\n\n\n#### **Model training with homomorphic encryption**\n\n\nWe can now see how homomorphic encryption could be used to securely outsource the training of a logistic-regression model. Customers would encrypt training data with keys they generate and control and send the encrypted training data to a cloud service. The service would compute an encrypted model based on the encrypted data and send it back to the customer; the model could then be decrypted with the customer’s key.\n\nThe most challenging part of deploying this solution is expressing the logistic-regression-model training function as a low-depth circuit. Prior research on encrypted logistic-regression-model training has explored several variations on the logistic-regression training function. For example:\n\n- Training on all samples at once versus using minibatches;\n- Alternatives to classic gradient descent, such as Nesterov’s accelerated gradient;\n- Training with variations of the fixed-Hessian method.\n\nPreviously, the lowest-depth (and therefore most efficient) circuits for logistic-regression training had multiplicative depth 5*k*, where k is the number of minibatches of data that the model is trained on. \n\nWe revisited one of these existing solutions and created a circuit with multiplicative depth 2.5*k* for *k* minibatches — half the multiplicative depth. This effectively doubles the number of minibatches that can be incorporated into the model in the same amount of time.\n\n\n#### **Techniques**\n\n\nThe logistic-regression-training algorithm can be expressed as a sequence of linear-algebra computations. Prior work showed how to evaluate a limited number of linear-algebra expressions on encrypted data when certain conditions apply. Our paper generalizes those results, providing a complete “toolkit” of homomorphic linear-algebra operations, enabling addition and multiplication of scalars, encrypted vectors, and encrypted matrices. The toolkit is generic and can be used with a variety of linear-algebra applications.\n\nWe combine the algorithms in the toolkit with well-established compiler techniques to reduce the circuit depth for logistic-regression model training. First, we use loop unrolling, which replaces the body of a loop with two or more copies of itself and adjusts the loop indices accordingly. Loop unrolling enables further optimizations that may not be possible with just a single copy of the loop body.\n\n\n\nWe also employ pipelining, which allows us to start one iteration of a loop while still working on the previous iteration. Finally, we remove data dependencies by duplicating some computations. This has the effect of increasing the circuit *width* (the number of operations that can be performed in parallel), while reducing the circuit depth. \n\nWe note that despite the increased circuit width, computing this lower-depth circuit is faster than computing previous circuits even on a single core. If the server has many cores, we can further improve training time, since our wide circuit provides ample opportunity for parallelism.\n\n\n#### **Results**\n\n\nWe compared our circuit for logistic-regression training to an earlier baseline circuit, using the MNIST data set, an image-processing data set consisting of handwritten digits. Both circuits were configured to incorporate six minibatches into the resulting model. In practice, both circuits would have to be applied multiple times to accommodate a realistic number of minibatches. \n\nOur circuit requires more encrypted inputs than the baseline; with the circuit parameters we chose, that corresponded to about an 80% increase in bandwidth requirements. Even though our circuit involves four times as many multiplications as the baseline, we can evaluate it more than six times as rapidly (13 seconds, compared to 80 seconds for the baseline) using a parallel implementation. Our homomorphically trained model had the same accuracy as a model trained on the plaintext data for the MNIST data set.\n\n\n#### **Training other model types**\n\n\nCreating efficient homomorphic circuits is a manual, time-consuming process. To make it easier for Amazon Web Services (Amazon Web Services) and others to create circuits for other functions — such as training functions for other machine learning models — we created the Homomorphic Implementor’s Toolkit (HIT), a C++ library that provides high-level APIs and evaluators for homomorphic circuits. HIT is available today ++[on GitHub](https://github.com/awslabs/homomorphic-implementors-toolkit)++. \n\nABOUT THE AUTHOR\n\n\n#### **[Eric Crockett](https://www.amazon.science/author/eric-crockett)**\n\n\nEric Crockett is an applied scientist with Amazon Web Services' Cryptography team.\n","render":"<p>The prevalence and success of machine learning have given rise to services that enable customers to train machine learning models in the cloud. In one scenario, a customer would upload training data to a cloud-based service and receive a trained model in return.</p>\n<p><em>Homomorphic encryption</em> (HE), a technology that allows computation on encrypted data, would give this procedure an extra layer of security. With HE, a customer would upload encrypted training data, and the service would use the encrypted data to directly produce an encrypted machine learning model, which only the customer could then decrypt.</p>\n<p>At the 2020 Workshop on Encrypted Computing and Applied Homomorphic Cryptography, we presented a <ins><a href=\"https://www.amazon.science/publications/a-low-depth-homomorphic-circuit-for-logistic-regression-model-training\" target=\"_blank\">paper</a></ins> exploring the application of homomorphic encryption to logistic regression, a statistical model used for myriad machine learning applications, from genomics to tax compliance. Our paper shows how to train logistic-regression models on encrypted data six times as fast as prior work.</p>\n<h4><a id=\"Homomorphic_encryption_7\"></a><strong>Homomorphic encryption</strong></h4>\n<p><img src=\"https://dev-media.amazoncloud.cn/a5dcda7f7a14472e88f2c94ed45d9f34_image.png\" alt=\"image.png\" /></p>\n<p>Homomorphic encryption provides an application programming interface (API) for evaluating functions on encrypted data. We refer to a message as m and its encryption as m with a box around it. Two of the operations in this API are the HE versions of addition and multiplication, which we present at right. The inputs are encrypted values, and the output is the encryption of the sum or product of the plaintext values.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/4004c1e0bbae4245b623fd999b62297b_image.png\" alt=\"image.png\" /></p>\n<p><img src=\"https://dev-media.amazoncloud.cn/b9c45716aa95416ab2ba72a2b82e4c17_image.png\" alt=\"image.png\" /></p>\n<p>A circuit with a multiplicative depth of three.</p>\n<p>The eval operation takes a description of an arbitrary function <em>ƒ</em> as a circuit <em>ƒ</em>-hat (<em>ƒ</em> with a circumflex accent above it) expressed using only the HE versions of addition and multiplication, as in the example at left. Given <em>ƒ</em>-hat and an encrypted input, eval produces an encryption of the output of evaluating <em>ƒ</em> on the input <em>m</em>.</p>\n<p>For example, to evaluate <em>ƒ(x) = x<sup>4</sup> + 2</em> on encrypted data, we could use the circuit <em>ƒ<sub>1</sub></em>-hat at right. This would be to use <em>ƒ<sub>1</sub></em>-hat and the encrypted version of x as the inputs to the eval operation and <em>x<sup>4</sup> + 2</em> as <em>ƒ(m)</em>.</p>\n<h4><a id=\"Multiplicative_depth_25\"></a><strong>Multiplicative depth</strong></h4>\n<p><img src=\"https://dev-media.amazoncloud.cn/391f346593054674836229f50f471f0c_image.png\" alt=\"image.png\" /></p>\n<p>A circuit with a multiplicative depth of two.</p>\n<p>The efficiency of the <em>eval</em> operation depends on a property called <em>multiplicative depth</em>, the maximum number of multiplications along any path through a circuit. In the example at right, <em>ƒ<sub>1</sub></em>-hat has a multiplicative depth of three, since there is a path that contains three multiplications but no path that has more than three multiplications. However, this is not the most efficient circuit for computing <em>ƒ(x) = x<sup>4</sup> + 2</em> .</p>\n<p>Consider, instead, the circuit at left. This circuit also computes <em>x<sup>4</sup> + 2</em> but has a multiplicative depth of only two. It is therefore more efficient to evaluate <em>ƒ<sub>2</sub></em>-hat than to evaluate <em>ƒ<sub>1</sub></em>-hat.</p>\n<h4><a id=\"Model_training_with_homomorphic_encryption_37\"></a><strong>Model training with homomorphic encryption</strong></h4>\n<p>We can now see how homomorphic encryption could be used to securely outsource the training of a logistic-regression model. Customers would encrypt training data with keys they generate and control and send the encrypted training data to a cloud service. The service would compute an encrypted model based on the encrypted data and send it back to the customer; the model could then be decrypted with the customer’s key.</p>\n<p>The most challenging part of deploying this solution is expressing the logistic-regression-model training function as a low-depth circuit. Prior research on encrypted logistic-regression-model training has explored several variations on the logistic-regression training function. For example:</p>\n<ul>\n<li>Training on all samples at once versus using minibatches;</li>\n<li>Alternatives to classic gradient descent, such as Nesterov’s accelerated gradient;</li>\n<li>Training with variations of the fixed-Hessian method.</li>\n</ul>\n<p>Previously, the lowest-depth (and therefore most efficient) circuits for logistic-regression training had multiplicative depth 5<em>k</em>, where k is the number of minibatches of data that the model is trained on.</p>\n<p>We revisited one of these existing solutions and created a circuit with multiplicative depth 2.5<em>k</em> for <em>k</em> minibatches — half the multiplicative depth. This effectively doubles the number of minibatches that can be incorporated into the model in the same amount of time.</p>\n<h4><a id=\"Techniques_53\"></a><strong>Techniques</strong></h4>\n<p>The logistic-regression-training algorithm can be expressed as a sequence of linear-algebra computations. Prior work showed how to evaluate a limited number of linear-algebra expressions on encrypted data when certain conditions apply. Our paper generalizes those results, providing a complete “toolkit” of homomorphic linear-algebra operations, enabling addition and multiplication of scalars, encrypted vectors, and encrypted matrices. The toolkit is generic and can be used with a variety of linear-algebra applications.</p>\n<p>We combine the algorithms in the toolkit with well-established compiler techniques to reduce the circuit depth for logistic-regression model training. First, we use loop unrolling, which replaces the body of a loop with two or more copies of itself and adjusts the loop indices accordingly. Loop unrolling enables further optimizations that may not be possible with just a single copy of the loop body.</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/f0fbe88387ad431db6d031eb32b5d1df_image.png\" alt=\"image.png\" /></p>\n<p>We also employ pipelining, which allows us to start one iteration of a loop while still working on the previous iteration. Finally, we remove data dependencies by duplicating some computations. This has the effect of increasing the circuit <em>width</em> (the number of operations that can be performed in parallel), while reducing the circuit depth.</p>\n<p>We note that despite the increased circuit width, computing this lower-depth circuit is faster than computing previous circuits even on a single core. If the server has many cores, we can further improve training time, since our wide circuit provides ample opportunity for parallelism.</p>\n<h4><a id=\"Results_67\"></a><strong>Results</strong></h4>\n<p>We compared our circuit for logistic-regression training to an earlier baseline circuit, using the MNIST data set, an image-processing data set consisting of handwritten digits. Both circuits were configured to incorporate six minibatches into the resulting model. In practice, both circuits would have to be applied multiple times to accommodate a realistic number of minibatches.</p>\n<p>Our circuit requires more encrypted inputs than the baseline; with the circuit parameters we chose, that corresponded to about an 80% increase in bandwidth requirements. Even though our circuit involves four times as many multiplications as the baseline, we can evaluate it more than six times as rapidly (13 seconds, compared to 80 seconds for the baseline) using a parallel implementation. Our homomorphically trained model had the same accuracy as a model trained on the plaintext data for the MNIST data set.</p>\n<h4><a id=\"Training_other_model_types_75\"></a><strong>Training other model types</strong></h4>\n<p>Creating efficient homomorphic circuits is a manual, time-consuming process. To make it easier for Amazon Web Services (Amazon Web Services) and others to create circuits for other functions — such as training functions for other machine learning models — we created the Homomorphic Implementor’s Toolkit (HIT), a C++ library that provides high-level APIs and evaluators for homomorphic circuits. HIT is available today <ins><a href=\"https://github.com/awslabs/homomorphic-implementors-toolkit\" target=\"_blank\">on GitHub</a></ins>.</p>\n<p>ABOUT THE AUTHOR</p>\n<h4><a id=\"Eric_Crocketthttpswwwamazonscienceauthorericcrockett_83\"></a><strong><a href=\"https://www.amazon.science/author/eric-crockett\" target=\"_blank\">Eric Crockett</a></strong></h4>\n<p>Eric Crockett is an applied scientist with Amazon Web Services’ Cryptography team.</p>\n"}
Building machine learning models with encrypted data
海外精选

海外精选的内容汇集了全球优质的亚马逊云科技相关技术内容。同时,内容中提到的“AWS”
是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。

 0
0 0
0亚马逊云科技解决方案 基于行业客户应用场景及技术领域的解决方案
联系亚马逊云科技专家
亚马逊云科技解决方案
基于行业客户应用场景及技术领域的解决方案
联系专家

0
目录

 分享
分享 点赞
点赞 收藏
收藏 目录
目录立即注册,开启您的免费套餐
立即关注

亚马逊云开发者
公众号

User Group
公众号

亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
关于我们 
更多资源
开发者工具
更多支持
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
