{"value":"##### **Key Takeaways**\n- The advent of Big Data is characterized by the 5Vs: Volume, Variety, Velocity, Veracity, and Value\n- DataBase Plus allows applications to communicate with standardized services using SQL queries. It also allows for feature plugins.\n- Database Plus is a technology and development concept compatible with any database, that can eliminate switching costs and vendor lock-in.\n- Apache ShardingSphere is an open source ecosystem that can create a distributed and encrypted database and can enhance them with sharding, elastic scaling, and encryption features.\n- Using AWS’ Aurora database as the storage node, it is possible to build a distributed database cluster with ShardingSphere running as a computing node on EC2.\n\n### **Background**\nData traffic increased to levels we’d never have thought possible just little over a decade ago - and it’s not slowing down. The exponential increase in data traffic has ushered us into the era of Big Data coming from a number of sources ranging from mobile apps, social networks, customer databases or data from IoT (Internet of Things) devices. \n\nThe advent of Big Data has meant new attention dedicated to new technologies, new challenges, and new skill sets to be developed to keep up with the newly found database tech development pace. \n\nConcurrently, what has now come to be called \"traditional databases\", have been losing ground to innovative database solutions. The emergence of data lakes as the preferred storage solution for Big Data, has meant that traditional data warehouses that were built on relational databases (traditional databases) and capable of storing only structured data, have been struggling. Data lakes are usually based on Hadoop clusters, or NoSQL databases for example. \n\nThis post starts off by introducing the challenges that emerged since the Internet has gone mainstream, to then present you with some ideas and a hands-on guide to solving some of these issues - data distribution and security in particular. \n\nConsidering how these two issues related to different areas of Big Data, you'd be pressed to think about the number of databases that can potentially be used. To keep things simple and clear, this post considers how to upgrade conventional databases such as MySQL, PostgreSQL, or SQLServer with distributed and secure features. This type of solution converts your database cluster into a sharding distributed system and enhances it with useful features such as data encryption and traffic governance. These advantages are certainly no small feat, but there's more: upgrading and migrating your database cluster will generate a net positive if you consider the cost-benefit equation. \n\n### **Big data creating database challenges**\nBefore getting down to the practical aspects, let's first look at the 5V characteristics of Big Data and its challenges:\n\n1、Volume. The amount and size of the data are too large to manage and efficiently use. \n2、Variety. There is a wide range of data types, including the likes of structured data, unstructured data, and hybrid data.\n3、Velocity. The increasing speed is a result of thriving Internet traffic. \n4、Veracity. The accuracy of data determines executives' confidence in business decisions and prospects. /5、Value. Data accumulation and analysis creates new opportunities for businesses to discover new potential markets/products, and to make better informed decisions. \n\nConsidering the Veracity and Value points of the previous list are more pertinent to data analytics, they're not the focus of this piece. Considering the Volume, Variety and Velocity points, across industries multiple types of businesses are looking for solutions to the following issues:\n\n1、How to store and efficiently manage unprecedented amounts of data?\n2、How to flexibly expand database instances on-demand?\n3、Considering that in some cases data is collected from multiple sources and then combined into a single result, how to manage structured and unstructured data in tandem? \n4、How to protect users' privacy in an online system with the minimum amount of refactoring? \n\nThere are multiple possible solutions to these problems. Examples include finding a new database vendor or developing middleware or plugins.\n\nHowever, if you are using or considering an open source traditional DBMS, you can refer to the rest of this post as a recommendation for your own system to evolve it to or create a distributed secure database system that leverages traditional DBMS. Depending on if you prefer PostgreSQL, MySQL, or RDS the following steps can be applied to your system. \n\n### **Introducing the architecture**\n#### **Apache ShardingSphere**\n[Apache ShardingSphere](https://shardingsphere.apache.org/) is an open source ecosystem that can transform any database into a distributed database system, and enhance it with sharding, elastic scaling, encryption features and much more. \n\nThe project's definition can already give you a hint - it can assist you in converting your existing databases into distributed databases, and improve the eventual new system with useful features. \n\nThe procedure is fairly straightforward. To achieve this outcome, all you have to do is import the project into your database system (therefore creating a sharding database system), scaling it out on-demand and if you wish to do so, encrypting the data for privacy protection. The following figure gives you an overview of the proposed architecture. \n\n\n\nAs shown in the previous figure, our distributed database system consists of Apache ShardingSphere (in this case ShardingSphere-Proxy) positioned in between applications and databases such as MySQL, PostgreSQL, Aurora or any other SQL92 database.\n\nIn this system, ShardingSphere serves as the computing node receiving user requests, while databases serve as storage nodes to store the data and perform some local computing. Connecting applications will send their queries to ShardingSphere in the same way they would send their queries to a DBMS. \n\nTraditionally SQL would be used to query the databases. Nevertheless, due to the addition of multiple new features in the proposed distributed database system (think auto-scaling, encryption, SQL audit), a SQL-like language is required to operate the new features. \n\nTo answer this requirement, without creating a new barrier or learning curve, the project uses Distributed SQL (DistSQL), to allow for a seamless transition. This means that you can just login to ShardingSphere, enter your SQL and DistSQL to create a sharding table, encrypted table, or start a scaling job. In the following sections I will demonstrate its magic and versatility.\n\nBefore we proceed, let's take the previous figure one step further. If the previous figure gave you an overview of the deployment architecture including ShardingSphere, the following figure \"zooms in\" to give you an indepth look. \n\n\n\nAs you can see from the figure, ShardingSphere not only acts as a computing node in the distributed database system, but also includes a multitude of useful features, and two clients being ShardingSphere-Proxy and ShardingSphere-JDBC. \n\n#### **Database Plus**\nDatabase Plus is the guiding development concept the Apache ShardingSphere project follows. It is a concept for a distributed database system that takes it up a notch, and goes beyond simple data sharding. \n\nIt was first conceived with the goal of creating a standardized layer and ecosystem positioned above existing and fragmented databases, to provide unified SQL operation services, and minimize databases' differentiation. As a result, applications communicate with a standardized service, rather than requiring tweaking to match each different database. ShardingSphere functions as a standard database server for end users by leveraging traditional DBMS and noSQL databases (TODO). \n\n\n\n#### **Feature plugins**\nThe term \"feature plugins\" that we use in the Database Plus terminology, refers to the fact that all of these features can function both independently as well as concurrently. \n\nThis means that a Database Plus based database system is adaptable and \"pluggable\", simplifying the combination of multiple feature plugins for end users. ShardingSphere currently supports sharding, read/write splitting, database gateway, data encryption, distributed privileges, shadow database, and other features.\n\n#### **Clients**\nTwo clients are included in the ecosystem, for independent or concurrent deployment. \n\nShardingSphere-Proxy is a transparent database proxy that also functions as a database server. As a result, it should be deployed independently on a server. Currently, PostgreSQL and MySQL work well with ShardingSphere.\n\nShardingSphere-JDBC is a lightweight Java framework that extends the Java JDBC layer. It integrates into your JDBC application.\n\nA concurrent deployment of the two clients is an option, with ShardingSphere-JDBC acting as a high-performance driver and ShardingSphere-Proxy acting as a management client.\n\n### **Guide to create a secure distributed database cluster leveraging your DBMS**\nFollowing the comprehensive architecture introduction, let's now jump into a step-by-step guide for creating a sharding and secure Aurora database system. In other words, we use ShardingSphere's sharding plugin, data encryption plugin, and ShardingSphere-Proxy for PostgreSQL to build a distributed database system, as shown in the following figure.\n\n\n\nThe final solution you will have once you go through the steps in the guide, will look like the figure below. \n\nThe application considers ShardingSphere + PostgreSQL instances to be a distributed database and treats ShardingSphere similarly to PostgreSQL. From the user perspective, there is only one logic table, namely t_user. However, this table is made up of four actual tables, from t_user_0 to t_user_3, which are located in two different PostgreSQL instances. \n\nThe logic table t_user has a column tel that stores users' phone numbers. Since phone numbers are considered sensitive data, they must be encrypted when stored in a database. To accomplish this, two columns tel cipher and tel plain are created in the actual tables to save the corresponding ciphertext and plaintext (optional, shown here only for demonstration purposes). \n\nThe ecosystem's user friendliness means that end users do not need to be concerned with these columns in the actual table, or how to map a logic column to its actual columns. They simply construct their SQL statement using the logic column and plaintext data, and ShardingSphere will complete the entire process of sharding the data, as well as automatically encrypting and decrypting data. \n\nShardingSphere-Proxy executes all of these processes in the background, greatly simplifying your life as a user, only requiring you to deal with the logic table t user with a logic column tel. However, before running a SQL query, users shall guide ShardingSphere on how to shard and encrypt data.\n\n\n\n### **Step-by-step demo **\nThe following demonstration is performed on AWS using the Aurora database as the storage nodes, with ShardingSphere running as a computing node on EC2.\n\n1、Create EC2 for ShardingSphere-Proxy.\n\n\n\n2、Create Aurora databases.\n\n\n\n\n\n3、Deploy ShardingSphere-Proxy.\n\n\n\n\n\n4、Login to ShardingSphere-Proxy.\n\n\n\n5、Initialize the Aurora databases.\n\n\n\n\n\n6、Initialize ShardingSphere with encryption rule and sharding rule by SQL and Distributed SQL.\n\n\n\n\n\n\n\n\n\n7、Insert rows for test on ShardingSphere-Proxy.\n\n\n\n8、Run test query SQLs.\n\n\n\n\n\n\n9、Check the actual data in the Aurora databases.\n\n\n\n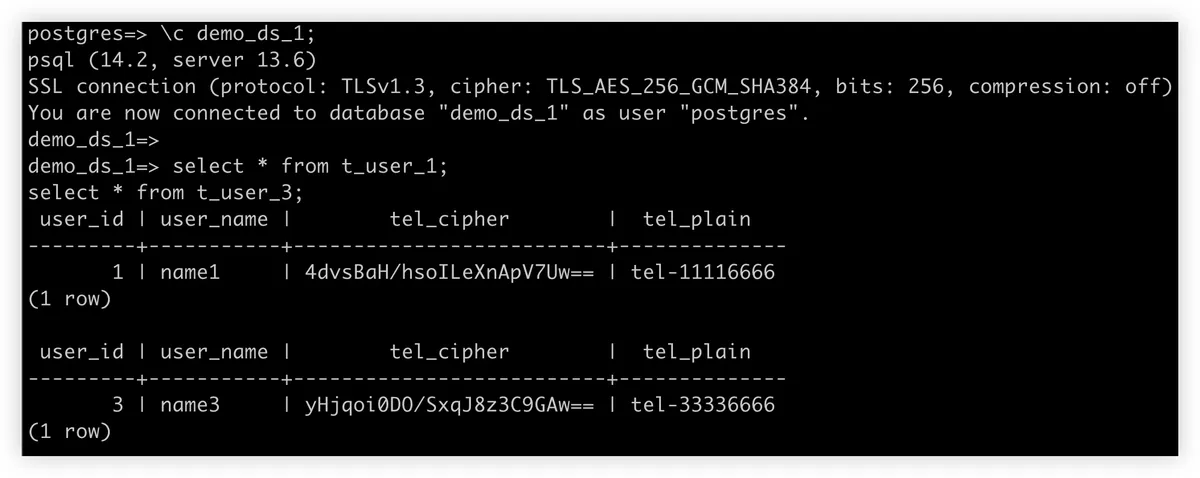\n\n### **Wrap-up**\nThis post focuses on the creation of a distributed and secure database on Aurora using ShardingSphere, while giving the possibility to add many interesting features as well. \n\nThe same guide can be used for a variety of other supported database types, to serve as storage nodes for this distributed database. Thanks to the power of open source, there probably are many other solutions that could solve similar issues, and I hope that the readers of this post can find the most suitable solution for their environment.\n\n#### **About the Author**\n\n\n\n\n**Trista Pan**\n\n*SphereEx Co-Founder & CTO, Apache Member & Incubator Mentor, Apache ShardingSphere PMC, AWS Data Hero, Tencent Cloud TVP. She used to be responsible for the design and development of the intelligent database platform of JD Digital Science and Technology.*\n\n\n","render":"<h5><a id=\"Key_Takeaways_0\"></a><strong>Key Takeaways</strong></h5>\n<ul>\n<li>The advent of Big Data is characterized by the 5Vs: Volume, Variety, Velocity, Veracity, and Value</li>\n<li>DataBase Plus allows applications to communicate with standardized services using SQL queries. It also allows for feature plugins.</li>\n<li>Database Plus is a technology and development concept compatible with any database, that can eliminate switching costs and vendor lock-in.</li>\n<li>Apache ShardingSphere is an open source ecosystem that can create a distributed and encrypted database and can enhance them with sharding, elastic scaling, and encryption features.</li>\n<li>Using AWS’ Aurora database as the storage node, it is possible to build a distributed database cluster with ShardingSphere running as a computing node on EC2.</li>\n</ul>\n<h3><a id=\"Background_7\"></a><strong>Background</strong></h3>\n<p>Data traffic increased to levels we’d never have thought possible just little over a decade ago - and it’s not slowing down. The exponential increase in data traffic has ushered us into the era of Big Data coming from a number of sources ranging from mobile apps, social networks, customer databases or data from IoT (Internet of Things) devices.</p>\n<p>The advent of Big Data has meant new attention dedicated to new technologies, new challenges, and new skill sets to be developed to keep up with the newly found database tech development pace.</p>\n<p>Concurrently, what has now come to be called “traditional databases”, have been losing ground to innovative database solutions. The emergence of data lakes as the preferred storage solution for Big Data, has meant that traditional data warehouses that were built on relational databases (traditional databases) and capable of storing only structured data, have been struggling. Data lakes are usually based on Hadoop clusters, or NoSQL databases for example.</p>\n<p>This post starts off by introducing the challenges that emerged since the Internet has gone mainstream, to then present you with some ideas and a hands-on guide to solving some of these issues - data distribution and security in particular.</p>\n<p>Considering how these two issues related to different areas of Big Data, you’d be pressed to think about the number of databases that can potentially be used. To keep things simple and clear, this post considers how to upgrade conventional databases such as MySQL, PostgreSQL, or SQLServer with distributed and secure features. This type of solution converts your database cluster into a sharding distributed system and enhances it with useful features such as data encryption and traffic governance. These advantages are certainly no small feat, but there’s more: upgrading and migrating your database cluster will generate a net positive if you consider the cost-benefit equation.</p>\n<h3><a id=\"Big_data_creating_database_challenges_18\"></a><strong>Big data creating database challenges</strong></h3>\n<p>Before getting down to the practical aspects, let’s first look at the 5V characteristics of Big Data and its challenges:</p>\n<p>1、Volume. The amount and size of the data are too large to manage and efficiently use.<br />\n2、Variety. There is a wide range of data types, including the likes of structured data, unstructured data, and hybrid data.<br />\n3、Velocity. The increasing speed is a result of thriving Internet traffic.<br />\n4、Veracity. The accuracy of data determines executives’ confidence in business decisions and prospects. /5、Value. Data accumulation and analysis creates new opportunities for businesses to discover new potential markets/products, and to make better informed decisions.</p>\n<p>Considering the Veracity and Value points of the previous list are more pertinent to data analytics, they’re not the focus of this piece. Considering the Volume, Variety and Velocity points, across industries multiple types of businesses are looking for solutions to the following issues:</p>\n<p>1、How to store and efficiently manage unprecedented amounts of data?<br />\n2、How to flexibly expand database instances on-demand?<br />\n3、Considering that in some cases data is collected from multiple sources and then combined into a single result, how to manage structured and unstructured data in tandem?<br />\n4、How to protect users’ privacy in an online system with the minimum amount of refactoring?</p>\n<p>There are multiple possible solutions to these problems. Examples include finding a new database vendor or developing middleware or plugins.</p>\n<p>However, if you are using or considering an open source traditional DBMS, you can refer to the rest of this post as a recommendation for your own system to evolve it to or create a distributed secure database system that leverages traditional DBMS. Depending on if you prefer PostgreSQL, MySQL, or RDS the following steps can be applied to your system.</p>\n<h3><a id=\"Introducing_the_architecture_37\"></a><strong>Introducing the architecture</strong></h3>\n<h4><a id=\"Apache_ShardingSphere_38\"></a><strong>Apache ShardingSphere</strong></h4>\n<p><a href=\"https://shardingsphere.apache.org/\" target=\"_blank\">Apache ShardingSphere</a> is an open source ecosystem that can transform any database into a distributed database system, and enhance it with sharding, elastic scaling, encryption features and much more.</p>\n<p>The project’s definition can already give you a hint - it can assist you in converting your existing databases into distributed databases, and improve the eventual new system with useful features.</p>\n<p>The procedure is fairly straightforward. To achieve this outcome, all you have to do is import the project into your database system (therefore creating a sharding database system), scaling it out on-demand and if you wish to do so, encrypting the data for privacy protection. The following figure gives you an overview of the proposed architecture.</p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/ed1decfa789746c6941e378e9b3e9f51_image.png\" alt=\"image.png\" /></p>\n<p>As shown in the previous figure, our distributed database system consists of Apache ShardingSphere (in this case ShardingSphere-Proxy) positioned in between applications and databases such as MySQL, PostgreSQL, Aurora or any other SQL92 database.</p>\n<p>In this system, ShardingSphere serves as the computing node receiving user requests, while databases serve as storage nodes to store the data and perform some local computing. Connecting applications will send their queries to ShardingSphere in the same way they would send their queries to a DBMS.</p>\n<p>Traditionally SQL would be used to query the databases. Nevertheless, due to the addition of multiple new features in the proposed distributed database system (think auto-scaling, encryption, SQL audit), a SQL-like language is required to operate the new features.</p>\n<p>To answer this requirement, without creating a new barrier or learning curve, the project uses Distributed SQL (DistSQL), to allow for a seamless transition. This means that you can just login to ShardingSphere, enter your SQL and DistSQL to create a sharding table, encrypted table, or start a scaling job. In the following sections I will demonstrate its magic and versatility.</p>\n<p>Before we proceed, let’s take the previous figure one step further. If the previous figure gave you an overview of the deployment architecture including ShardingSphere, the following figure “zooms in” to give you an indepth look.</p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/c5cea9e9a4b348f18c67317aa26b33ca_image.png\" alt=\"image.png\" /></p>\n<p>As you can see from the figure, ShardingSphere not only acts as a computing node in the distributed database system, but also includes a multitude of useful features, and two clients being ShardingSphere-Proxy and ShardingSphere-JDBC.</p>\n<h4><a id=\"Database_Plus_61\"></a><strong>Database Plus</strong></h4>\n<p>Database Plus is the guiding development concept the Apache ShardingSphere project follows. It is a concept for a distributed database system that takes it up a notch, and goes beyond simple data sharding.</p>\n<p>It was first conceived with the goal of creating a standardized layer and ecosystem positioned above existing and fragmented databases, to provide unified SQL operation services, and minimize databases’ differentiation. As a result, applications communicate with a standardized service, rather than requiring tweaking to match each different database. ShardingSphere functions as a standard database server for end users by leveraging traditional DBMS and noSQL databases (TODO).</p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/abd7b02ecd5041df83c8fac490bff2b3_image.png\" alt=\"image.png\" /></p>\n<h4><a id=\"Feature_plugins_68\"></a><strong>Feature plugins</strong></h4>\n<p>The term “feature plugins” that we use in the Database Plus terminology, refers to the fact that all of these features can function both independently as well as concurrently.</p>\n<p>This means that a Database Plus based database system is adaptable and “pluggable”, simplifying the combination of multiple feature plugins for end users. ShardingSphere currently supports sharding, read/write splitting, database gateway, data encryption, distributed privileges, shadow database, and other features.</p>\n<h4><a id=\"Clients_73\"></a><strong>Clients</strong></h4>\n<p>Two clients are included in the ecosystem, for independent or concurrent deployment.</p>\n<p>ShardingSphere-Proxy is a transparent database proxy that also functions as a database server. As a result, it should be deployed independently on a server. Currently, PostgreSQL and MySQL work well with ShardingSphere.</p>\n<p>ShardingSphere-JDBC is a lightweight Java framework that extends the Java JDBC layer. It integrates into your JDBC application.</p>\n<p>A concurrent deployment of the two clients is an option, with ShardingSphere-JDBC acting as a high-performance driver and ShardingSphere-Proxy acting as a management client.</p>\n<h3><a id=\"Guide_to_create_a_secure_distributed_database_cluster_leveraging_your_DBMS_82\"></a><strong>Guide to create a secure distributed database cluster leveraging your DBMS</strong></h3>\n<p>Following the comprehensive architecture introduction, let’s now jump into a step-by-step guide for creating a sharding and secure Aurora database system. In other words, we use ShardingSphere’s sharding plugin, data encryption plugin, and ShardingSphere-Proxy for PostgreSQL to build a distributed database system, as shown in the following figure.</p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/9958ca8a4d70478082b87c21f0a8a6c8_image.png\" alt=\"image.png\" /></p>\n<p>The final solution you will have once you go through the steps in the guide, will look like the figure below.</p>\n<p>The application considers ShardingSphere + PostgreSQL instances to be a distributed database and treats ShardingSphere similarly to PostgreSQL. From the user perspective, there is only one logic table, namely t_user. However, this table is made up of four actual tables, from t_user_0 to t_user_3, which are located in two different PostgreSQL instances.</p>\n<p>The logic table t_user has a column tel that stores users’ phone numbers. Since phone numbers are considered sensitive data, they must be encrypted when stored in a database. To accomplish this, two columns tel cipher and tel plain are created in the actual tables to save the corresponding ciphertext and plaintext (optional, shown here only for demonstration purposes).</p>\n<p>The ecosystem’s user friendliness means that end users do not need to be concerned with these columns in the actual table, or how to map a logic column to its actual columns. They simply construct their SQL statement using the logic column and plaintext data, and ShardingSphere will complete the entire process of sharding the data, as well as automatically encrypting and decrypting data.</p>\n<p>ShardingSphere-Proxy executes all of these processes in the background, greatly simplifying your life as a user, only requiring you to deal with the logic table t user with a logic column tel. However, before running a SQL query, users shall guide ShardingSphere on how to shard and encrypt data.</p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/6a2ddca10bd5492daa793b9278aba797_image.png\" alt=\"image.png\" /></p>\n<h3><a id=\"Stepbystep_demo__99\"></a>**Step-by-step demo **</h3>\n<p>The following demonstration is performed on AWS using the Aurora database as the storage nodes, with ShardingSphere running as a computing node on EC2.</p>\n<p>1、Create EC2 for ShardingSphere-Proxy.</p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/fff88ae6004046a98ab5747961020984_image.png\" alt=\"image.png\" /></p>\n<p>2、Create Aurora databases.</p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/3a124ae34cc242c088e927a888451f00_image.png\" alt=\"image.png\" /></p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/43b1ae75861e4fa8a8315fae46e6bcf2_image.png\" alt=\"image.png\" /></p>\n<p>3、Deploy ShardingSphere-Proxy.</p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/c4800928582f4ca4be39345250d7bd0b_image.png\" alt=\"image.png\" /></p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/5e792c2966db4e85b31afcc67ce3e697_image.png\" alt=\"image.png\" /></p>\n<p>4、Login to ShardingSphere-Proxy.</p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/9920ad9333d1433890ec4246636e3c73_image.png\" alt=\"image.png\" /></p>\n<p>5、Initialize the Aurora databases.</p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/6dd5002debbb48dfbf60ae694cff553e_image.png\" alt=\"image.png\" /></p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/9b72f5d01c164599bfbc764d1d83fdf5_image.png\" alt=\"image.png\" /></p>\n<p>6、Initialize ShardingSphere with encryption rule and sharding rule by SQL and Distributed SQL.</p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/6d2ebb85dc2a4d29bd45ddb69b3ae677_image.png\" alt=\"image.png\" /></p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/5d36527d993543549d3bd9280ce6eaa6_image.png\" alt=\"image.png\" /></p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/73d921cc73334d779b75a419248b4315_image.png\" alt=\"image.png\" /></p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/880e667b89fa4b3daaf666ca49ac6cbc_image.png\" alt=\"image.png\" /></p>\n<p>7、Insert rows for test on ShardingSphere-Proxy.</p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/3a3a4301a101485897cae64f6b9067f9_image.png\" alt=\"image.png\" /></p>\n<p>8、Run test query SQLs.</p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/8a58a2dd18f941d393299cf101597ea2_image.png\" alt=\"image.png\" /></p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/cb07842d388c4582a0fc36310ec5b2fd_image.png\" alt=\"image.png\" /></p>\n<p>9、Check the actual data in the Aurora databases.</p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/87b98b9a68314c83ba76aa59ab424749_image.png\" alt=\"image.png\" /></p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/f92fc6093fd5433189a8b04a7c19ea37_image.png\" alt=\"image.png\" /></p>\n<h3><a id=\"Wrapup_155\"></a><strong>Wrap-up</strong></h3>\n<p>This post focuses on the creation of a distributed and secure database on Aurora using ShardingSphere, while giving the possibility to add many interesting features as well.</p>\n<p>The same guide can be used for a variety of other supported database types, to serve as storage nodes for this distributed database. Thanks to the power of open source, there probably are many other solutions that could solve similar issues, and I hope that the readers of this post can find the most suitable solution for their environment.</p>\n<h4><a id=\"About_the_Author_160\"></a><strong>About the Author</strong></h4>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/109a767d7239424a88abcedaa2c624ce_image.png\" alt=\"image.png\" /></p>\n<p><strong>Trista Pan</strong></p>\n<p><em>SphereEx Co-Founder & CTO, Apache Member & Incubator Mentor, Apache ShardingSphere PMC, AWS Data Hero, Tencent Cloud TVP. She used to be responsible for the design and development of the intelligent database platform of JD Digital Science and Technology.</em></p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/82893d13192a482cb3ec2afce5983f29_%E6%8A%80%E6%9C%AF%E4%B8%93%E6%A0%8F1.jpg\" alt=\"技术专栏1.jpg\" /></p>\n"}
利用现有数据库管理系统创建一个安全的分布式数据库集群
数据库
分布式
海外精选

海外精选的内容汇集了全球优质的亚马逊云科技相关技术内容。同时,内容中提到的“AWS”
是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。

 0
0 0
0

亚马逊云科技解决方案 基于行业客户应用场景及技术领域的解决方案
联系亚马逊云科技专家
亚马逊云科技解决方案
基于行业客户应用场景及技术领域的解决方案
联系专家

0
目录

 分享
分享 点赞
点赞 收藏
收藏 目录
目录立即注册,开启您的免费套餐
立即关注

亚马逊云开发者
公众号

User Group
公众号

亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
关于我们 
更多资源
开发者工具
更多支持
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
