{"value":"由于云中管理着大量数据,因此需要在存储数据之前对其进行压缩,以实现存储介质的高效使用。已经开发了各种算法来对飞行中的各种数据类型进行压缩和解压缩。在本博客中,我们将介绍两种广受认可的算法——Zstandard 和 Snappy,并比较它们在 Arm 服务器上的性能。\n\n### **背景**\n有各种类型的数据压缩算法——其中一些是根据数据类型定制的——例如,视频、音频、图像/图形。然而,大多数其他类型的数据需要一种通用的无损压缩算法,并且可以跨不同的数据集提供良好的压缩比。这些压缩算法可用于多个应用程序。\n\n- 文件或对象存储系统,如 Ceph、OpenZFS、SquashFS\n- 数据库或分析应用程序,如 MongoDB、Kafka、Hadoop、Redis 等。\n- Web 或 HTTP–NGINX、curl、Django 等。\n- 档案软件——tar、winzip 等。\n- 其他几个用例,比如 Linux 内核压缩\n\n### **压缩与速度**\n压缩算法面临的一个关键挑战是,它们是为实现更高的压缩率而优化,还是为以更高的速度压缩/解压缩而优化。其中一个优化了存储空间,而另一个有助于节省计算周期并降低操作延迟。有些算法,例如 Zstandard[1]和 zlib[2],提供了多个预设,允许用户/应用程序根据使用情况选择自己的权衡。而另一些(例如 Snappy[3])则是为速度而设计的。\n\nZstandard 是 Facebook 开发的一种开源算法,可以提供与 DEFLATE 算法相当的最大压缩比,但针对更高的速度进行了优化,尤其是用于解压缩。自2016年推出以来,它在多套应用程序中非常流行,并成为Linux内核的默认压缩算法。\n\nSnappy 是由 Google 开发的开源算法,旨在以合理的压缩比优化压缩速度。它在数据库和分析应用程序中非常流行。\n\nArm 软件团队优化了这两种算法,以在基于 Arm Neoverse 内核的Arm服务器平台上实现高性能。这些优化使用 Neon 矢量引擎的功能来加速算法的某些部分。\n\n### **性能比较**\n我们采用了 Zstandard 和 Snappy 算法的最新优化版本,并在 Amazon Web Services 上的类似云实例上对它们进行了基准测试。\n\n- 2xlarge 实例——使用基于 Arm Neoverse N1内核的 Amazon Web Services Graviton2 \n- 2xlarge 实例–使用 Intel Cascade Lake\n\n两种算法都在两种不同的场景中进行了基准测试:\n\n关注原始算法性能——我们使用 lzbench 工具对包含不同行业标准数据类型的 Silesia corpus 进行了测试。\n\n流行的 NoSQL 数据库 MongoDB的应用程序级性能——使用 YCSB 工具测试使用这些压缩算法对数据库操作吞吐量和延迟的影响,并测量数据库的整体压缩。\n\n### **原始算法性能**\n##### 带宽(速度)比较\n该测试主要关注不同数据集的16个并行进程的原始聚合压缩/反压缩吞吐量。对于 Zstandard,我们观察到C6g实例压缩时的总体性能提升了30-67%,解压缩时的整体性能提升了11-35%。\n\n考虑到 C6g实例的价格降低了20%,每 MB 压缩数据最多可节省52%。\n\n\n图1:Zstd8压缩吞吐量比较——C5与G6g\n\n\n图2:Zstd8解压缩吞吐量比较——C5与G6g\n\n使用 Snappy 作为压缩算法,我们观察到,与预期的 Zstandard 相比,Snappy 具有更高的压缩和相对类似的解压缩速度。总体而言,与 C5相比,Snappy 在 C6g 实例的各种数据集上的表现要好40-90%。\n\n考虑到 C6g 实例的价格降低了20%,每 MB 压缩数据可以节省58%。\n\n\n图3:Snappy 压缩-C5与C6g\n\n\n图4:Snappy 解压缩-C5与C6g\n\n#### **压缩率**\n我们还比较了两种算法在 C6g 和 C5实例上对不同数据集的压缩比。在这两种情况下,都获得了相同的压缩比,这表明该算法的运行效率达到了预期。\n\n### **应用程序级性能**\nMongoDB WiredTiger 存储引擎支持几种压缩模式:snappy、zstd、zlib 等。这里我们正在测试压缩模式 snappy,zstd none。我们使用了一个由10000句英语文本组成的数据集,该数据集是使用 Python faker 随机生成的。\n\n单独的Amazon Web Services实例被用作测试对象和测试主机。文档被插入 MongoDB 数据库,占5GB(近似值)的数据。使用的测试对象实例是 Arm(c6g.2xlarge)和 Intel(c5.2xlarge)。在 MongoDB 数据库中填充了5GB 的数据后,我们使用“dbstat”命令来获取存储大小。\n\n### **Snappy vs Zstandard –速度 vs 压缩**\n在 Snappy 和 Zstandard 之间,我们观察到 Zstandard 在压缩总体数据库大小方面比预期的更好。\n\n\n图5:MongoDB:数据库压缩比\n\nSnappy 在插入操作中提供了更好的吞吐量,这是一种写(压缩)密集型操作。然而,涉及压缩和解压缩混合的读/修改/写操作在这两种算法之间几乎没有差异\n\n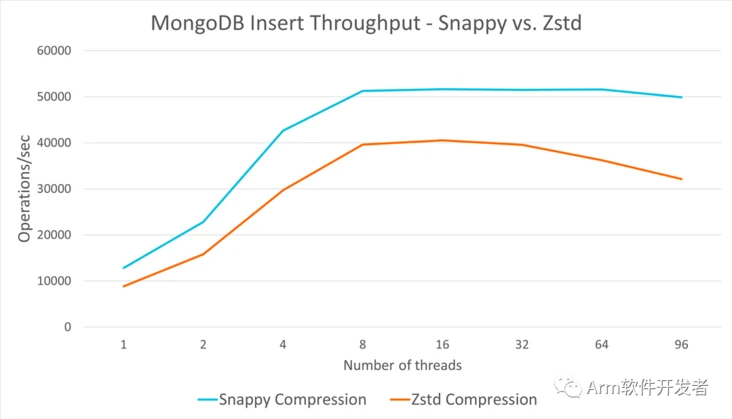\n图6:MongoDB:插入吞吐量——Snappy 与 Zstd\n\n\n图7:MongoDB:读/修改/写吞吐量——Snappy 与 Zstd\n\n### **结论**\nZstandard 和 Snappy 等通用压缩算法可用于各种应用程序,在压缩不同类型的通用数据集方面非常通用。Zstandard 和 Snappy 都针对 Arm Neoverse 和 Amazon Graviton2进行了优化,与基于 Intel 的实例相比,我们观察到了两个关键结果。首先,与类似的基于 Intel 的实例类型相比,基于 Graviton2的实例可以实现11-90%的更好的压缩和解压缩性能。第二,基于 Graviton2的实例可以将数据压缩成本降低一半。对于像 MongoDB 这样的实际应用程序,这些压缩算法只会给典型操作增加很少的开销,同时显著减少数据库大小。\n\n作者:Ravi Malhotra 2022年2月8日\n\n联合作者:Manoj Iyer 和 Yichen Jia\n\n","render":"<p>由于云中管理着大量数据,因此需要在存储数据之前对其进行压缩,以实现存储介质的高效使用。已经开发了各种算法来对飞行中的各种数据类型进行压缩和解压缩。在本博客中,我们将介绍两种广受认可的算法——Zstandard 和 Snappy,并比较它们在 Arm 服务器上的性能。</p>\n<h3><a id=\"_2\"></a><strong>背景</strong></h3>\n<p>有各种类型的数据压缩算法——其中一些是根据数据类型定制的——例如,视频、音频、图像/图形。然而,大多数其他类型的数据需要一种通用的无损压缩算法,并且可以跨不同的数据集提供良好的压缩比。这些压缩算法可用于多个应用程序。</p>\n<ul>\n<li>文件或对象存储系统,如 Ceph、OpenZFS、SquashFS</li>\n<li>数据库或分析应用程序,如 MongoDB、Kafka、Hadoop、Redis 等。</li>\n<li>Web 或 HTTP–NGINX、curl、Django 等。</li>\n<li>档案软件——tar、winzip 等。</li>\n<li>其他几个用例,比如 Linux 内核压缩</li>\n</ul>\n<h3><a id=\"_11\"></a><strong>压缩与速度</strong></h3>\n<p>压缩算法面临的一个关键挑战是,它们是为实现更高的压缩率而优化,还是为以更高的速度压缩/解压缩而优化。其中一个优化了存储空间,而另一个有助于节省计算周期并降低操作延迟。有些算法,例如 Zstandard[1]和 zlib[2],提供了多个预设,允许用户/应用程序根据使用情况选择自己的权衡。而另一些(例如 Snappy[3])则是为速度而设计的。</p>\n<p>Zstandard 是 Facebook 开发的一种开源算法,可以提供与 DEFLATE 算法相当的最大压缩比,但针对更高的速度进行了优化,尤其是用于解压缩。自2016年推出以来,它在多套应用程序中非常流行,并成为Linux内核的默认压缩算法。</p>\n<p>Snappy 是由 Google 开发的开源算法,旨在以合理的压缩比优化压缩速度。它在数据库和分析应用程序中非常流行。</p>\n<p>Arm 软件团队优化了这两种算法,以在基于 Arm Neoverse 内核的Arm服务器平台上实现高性能。这些优化使用 Neon 矢量引擎的功能来加速算法的某些部分。</p>\n<h3><a id=\"_20\"></a><strong>性能比较</strong></h3>\n<p>我们采用了 Zstandard 和 Snappy 算法的最新优化版本,并在 Amazon Web Services 上的类似云实例上对它们进行了基准测试。</p>\n<ul>\n<li>2xlarge 实例——使用基于 Arm Neoverse N1内核的 Amazon Web Services Graviton2</li>\n<li>2xlarge 实例–使用 Intel Cascade Lake</li>\n</ul>\n<p>两种算法都在两种不同的场景中进行了基准测试:</p>\n<p>关注原始算法性能——我们使用 lzbench 工具对包含不同行业标准数据类型的 Silesia corpus 进行了测试。</p>\n<p>流行的 NoSQL 数据库 MongoDB的应用程序级性能——使用 YCSB 工具测试使用这些压缩算法对数据库操作吞吐量和延迟的影响,并测量数据库的整体压缩。</p>\n<h3><a id=\"_32\"></a><strong>原始算法性能</strong></h3>\n<h5><a id=\"_33\"></a>带宽(速度)比较</h5>\n<p>该测试主要关注不同数据集的16个并行进程的原始聚合压缩/反压缩吞吐量。对于 Zstandard,我们观察到C6g实例压缩时的总体性能提升了30-67%,解压缩时的整体性能提升了11-35%。</p>\n<p>考虑到 C6g实例的价格降低了20%,每 MB 压缩数据最多可节省52%。</p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/6b80b5348c9549ce8132e4d25d379434_image.png\" alt=\"image.png\" /><br />\n图1:Zstd8压缩吞吐量比较——C5与G6g</p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/e299523e5a194b999f594e6e19d56ff1_image.png\" alt=\"image.png\" /><br />\n图2:Zstd8解压缩吞吐量比较——C5与G6g</p>\n<p>使用 Snappy 作为压缩算法,我们观察到,与预期的 Zstandard 相比,Snappy 具有更高的压缩和相对类似的解压缩速度。总体而言,与 C5相比,Snappy 在 C6g 实例的各种数据集上的表现要好40-90%。</p>\n<p>考虑到 C6g 实例的价格降低了20%,每 MB 压缩数据可以节省58%。</p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/63bc209fe11a492c9393eaf3555202ac_image.png\" alt=\"image.png\" /><br />\n图3:Snappy 压缩-C5与C6g</p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/90d70eee2cc44fa4a3cd7ab324e14e8c_image.png\" alt=\"image.png\" /><br />\n图4:Snappy 解压缩-C5与C6g</p>\n<h4><a id=\"_54\"></a><strong>压缩率</strong></h4>\n<p>我们还比较了两种算法在 C6g 和 C5实例上对不同数据集的压缩比。在这两种情况下,都获得了相同的压缩比,这表明该算法的运行效率达到了预期。</p>\n<h3><a id=\"_57\"></a><strong>应用程序级性能</strong></h3>\n<p>MongoDB WiredTiger 存储引擎支持几种压缩模式:snappy、zstd、zlib 等。这里我们正在测试压缩模式 snappy,zstd none。我们使用了一个由10000句英语文本组成的数据集,该数据集是使用 Python faker 随机生成的。</p>\n<p>单独的Amazon Web Services实例被用作测试对象和测试主机。文档被插入 MongoDB 数据库,占5GB(近似值)的数据。使用的测试对象实例是 Arm(c6g.2xlarge)和 Intel(c5.2xlarge)。在 MongoDB 数据库中填充了5GB 的数据后,我们使用“dbstat”命令来获取存储大小。</p>\n<h3><a id=\"Snappy_vs_Zstandard__vs__62\"></a><strong>Snappy vs Zstandard –速度 vs 压缩</strong></h3>\n<p>在 Snappy 和 Zstandard 之间,我们观察到 Zstandard 在压缩总体数据库大小方面比预期的更好。</p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/017cd86511ea4f91a92ad90594fdb388_image.png\" alt=\"image.png\" /><br />\n图5:MongoDB:数据库压缩比</p>\n<p>Snappy 在插入操作中提供了更好的吞吐量,这是一种写(压缩)密集型操作。然而,涉及压缩和解压缩混合的读/修改/写操作在这两种算法之间几乎没有差异</p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/2dca567294654712965d9560c3f6699d_image.png\" alt=\"image.png\" /><br />\n图6:MongoDB:插入吞吐量——Snappy 与 Zstd</p>\n<p><img src=\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/e7c30488dcf54ae786a466c4e173b5e8_image.png\" alt=\"image.png\" /><br />\n图7:MongoDB:读/修改/写吞吐量——Snappy 与 Zstd</p>\n<h3><a id=\"_76\"></a><strong>结论</strong></h3>\n<p>Zstandard 和 Snappy 等通用压缩算法可用于各种应用程序,在压缩不同类型的通用数据集方面非常通用。Zstandard 和 Snappy 都针对 Arm Neoverse 和 Amazon Graviton2进行了优化,与基于 Intel 的实例相比,我们观察到了两个关键结果。首先,与类似的基于 Intel 的实例类型相比,基于 Graviton2的实例可以实现11-90%的更好的压缩和解压缩性能。第二,基于 Graviton2的实例可以将数据压缩成本降低一半。对于像 MongoDB 这样的实际应用程序,这些压缩算法只会给典型操作增加很少的开销,同时显著减少数据库大小。</p>\n<p>作者:Ravi Malhotra 2022年2月8日</p>\n<p>联合作者:Manoj Iyer 和 Yichen Jia</p>\n<p><img src=\"https://dev-media.amazoncloud.cn/b60598a479304d83b8f7d5b03c3825f6_image.png\" alt=\"image.png\" /></p>\n"}
Amazon Graviton2 上数据压缩算法性能比较
数据库
Linux

 0
0 0
0亚马逊云科技解决方案 基于行业客户应用场景及技术领域的解决方案
联系亚马逊云科技专家
亚马逊云科技解决方案
基于行业客户应用场景及技术领域的解决方案
联系专家

0
目录

 分享
分享 点赞
点赞 收藏
收藏 目录
目录立即注册,开启您的免费套餐
立即关注

亚马逊云开发者
公众号

User Group
公众号

亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
关于我们 
更多资源
开发者工具
更多支持
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
