{"value":"::: hljs-center\n\n##### 目录\n\n:::\n\n1. ClickHouse 简介\n2. ClickHouse 与对象存储\n3. ClickHouse 与 S3 结合的三种方法\n4. 示例参考架构\n5. 小结\n6. 参考资料\n\n##### ClickHouse 简介\n\nClickHouse 是一种快速的、开源的、用于联机分析(OLAP)的列式数据库管理系统(DBMS),由俄罗斯的Yandex公司开发,于2016年开源。ClickHouse 作为交互式分析领域的后起之秀,发展速度非常快,目前在 GitHub 上已收获 14K Star。\n\n\n\nClickHouse 主打顶尖的极致性能,每台服务器每秒钟可以处理数亿至数十亿多行或者是数十GB的数据。ClickHouse 基于列式存储,通过 SQL 查询海量数据并实时生成分析报告。ClickHouse 充分利用了所有可用的硬件优化技术,以尽可能快地处理每个查询。向量化的查询执行引入了 SIMD 处理器指令和运行时代码生成技术。列式存储的数据会提高CPU缓存的命中率。ClickHouse 概览文档中的图片清晰地展示了行式存储与列式存储在 OLAP 领域中的速度差距。\n\n\n::: hljs-center\n\n*行式存储*\n\n:::\n\n\n::: hljs-center\n*列式存储*\n:::\n\n在分布式集群中,副本之间的数据读取会自动保持平衡,以避免增加延迟。同时,ClickHouse 支持多主异步复制模式,这种情况下所有节点角色都是相等的,可以避免出现单点故障,单个节点或整个可用区的停机时间并不会影响系统的读写可用性。\n\n\n\n在网络和应用分析,广告网络和实时出价,电信,电子商务和金融以及商业智能等领域,ClickHouse 都有很好的支持与应用,更多信息请参考 ClickHouse 官网。\n\n###### **01 ClickHouse与对象存储**\n\nClickHouse 针对数据量和查询场景提供了不同的数据库和数据表引擎,此外它也可以使用多种多样的专用引擎或表函数(例如 HDFS,Kafka,S3 等)与许多外部系统进行通讯。在现代化的云架构中,对象存储是最重要的存储组成部分。2006年,亚马逊云科技正式推出的第一个云服务也是 [Amazon S3](https://aws.amazon.com/cn/s3/?trk=cndc-detail)(Simple Storage Service),目前 [Amazon S3](https://aws.amazon.com/cn/s3/?trk=cndc-detail) 已经成为事实上的云对象存储标准。\n\n\n\n使用对象存储可以给数据分析系统带来诸多优势。首先,它可以使用数据湖架构中的原始数据。其次,对象存储可以为数据表数据提供高性价比且高可靠性的存储。针对 S3 目前 ClickHouse 已经上述对象存储的这两种用途。\n\n###### **02 ClickHouse 与 S3 结合的三种方法**\n\n1)通过 MergeTree 表引擎集成 S3\n\n\n\n前面提到 ClickHouse 提供了众多数据库和数据表引擎,这其中最强大的表引擎当属 MergeTree (合并树)引擎及合并树系列(*MergeTree)中的其他引擎。MergeTree 系列的引擎被设计用于插入海量的数据到一张表当中。数据可以以数据片段的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合并。相比在插入时不断修改(重写)已存储的数据,这种策略会高效很多。\n\n\n\nMergeTree 系列表引擎可以将数据存储在多块设备上。这对某些可以潜在被划分为“冷”“热”的表来说是很有用的。近期数据被定期的查询但只需要比较小的磁盘存储空间。相反,大量的、详尽的历史数据被用到的频率相对较少。ClickHouse 可以将 S3 对象存储用于 MergeTree 表数据,这样针对“热”的数据,可以放置在快速的磁盘上(比如 NVMe 固态硬盘或内存中),“冷”的数据可以存放在S3对象存储中。在MergeTree 系列表引擎中使用S3的参考架构如下图所示:\n\n\n\n2)通过 S3 表引擎集成\n\n\n\n除了 MergeTree 表引擎,ClickHouse 还直接提供了专用的 S3 表引擎,进一步加强了 [Amazon S3](https://aws.amazon.com/cn/s3/?trk=cndc-detail) 生态系统的集成,可以充分利用数据湖中已有的各种开放数据格式例如Parquet。通过以下语句就可以进行 S3 表引擎的创建:\n\n\n\n```\\nENGINE = S3(path, [aws_access_key_id, aws_secret_access_key,] format, structure, [compression])\\n```\n\n\n\n3)通过 S3 表函数集成\n\n\n\nClickHouse 提供表接口的方式对 S3 中的文件进行 SELECT/INSERT 操作,这种方式使用起来更加方便,可以快速与 ClickHouse 中已有的数据进行连接等操作。通过以下语句就可以使用S3表函数:\n\n\n\n```\\ns3(path, [aws_access_key_id, aws_secret_access_key,] format, structure, [compression])\\n```\n\n\n\n上述方式分别适用于不同的应用场景,可以根据具体情况进行单独或者结合使用。\n\n\n\n此外,可以看到这里面还涉及到 S3 访问权限的安全问题。在 ClickHouse 20.13之前的版本中,必须要在 SQL 或 ClickHouse 存储配置中提供 Amazon Web Services 的访问密钥(Access Key 和 Secret Access Key)才能访问,这是既不安全也不方便的模式。但是在20.13版本中,ClickHouse 提供了实用 IAM Role 访问方式,解决了访问 S3 的安全性问题。\n\n##### **03 示例参考架构**\n\n接下来,我们将演示如何实现上述介绍的 ClickHouse 与 S3 结合的三种方法。演示的参考架构如下图所示,我们将 ClickHouse 环境部署在一个 VPC 私有子网中,然后通过 VPC Enpoints 内网的方式来访问 S3 中的数据。\n\n\n\n在示例中,我们将使用纽约出租车数据,该数据分析是 Kaggle 竞赛的著名赛题之一,也是学习数据分析的经典练习案例,项目数据可以从 NYC 网站上进行下载,这里选取了2020年6月的 Yellow Taxi Trip Records 数据。\n\n\n\n以下示例的操作环境为亚马逊云科技中国(北京)区域。\n\n\n\n1)创建 S3 存储桶\n\n\n\n首先,在亚马逊云科技中国(北京)区域创建存储数据的S3存储桶,例如 clickhouse-shtian。\n\n\n\n 2)下载数据并上传到 S3 存储桶中\n\n\n\n首先,在 NYC 网站上将2020年6月 Yellow Taxi Trip Records 数据下载下来,然后上传到刚刚创建的 S3 桶中。\n\n\n\n 3)创建并配置 S3 的 VPC Enpoint\n\n\n\nVPC Enpoint 的创建和配置请参考 VPC 文档,确保子网路由表中包含下图中第二条路有条目。\n\n\n\n4)部署 ClickHouse\n\n\n\n示例操作系统为 Amazon Linux 2,ClickHouse 版本为20.13.1.5591,演示使用单点部署模式,实际使用环境建议部署集群模式,提升高可用的同时也增加性能。需要注意的是在创建 EC2 实例过程中需要配置 IAM 角色,可以参考文档适用于 [Amazon EC2 ](https://aws.amazon.com/cn/ec2/?trk=cndc-detail)的 IAM 角色进行设置,并确保这个角色具有 S3 桶的读写权限。\n\n\n\nSSH 登录到 EC2 实例上,然后下载对应版本的安装包,然后解压并安装。\n\n\n\n```\\nwget https://github.com/ClickHouse/ClickHouse/releases/download/v20.13.1.5591-testing/clickhouse-client-20.13.1.5591.tgz\\n\\nwget https://github.com/ClickHouse/ClickHouse/releases/download/v20.13.1.5591-testing/clickhouse-common-static-20.13.1.5591.tgz\\n\\nwget https://github.com/ClickHouse/ClickHouse/releases/download/v20.13.1.5591-testing/clickhouse-common-static-dbg-20.13.1.5591.tgz\\n\\nwget https://github.com/ClickHouse/ClickHouse/releases/download/v20.13.1.5591-testing/clickhouse-server-20.13.1.5591.tgz\\n\\ntar -xzvf clickhouse-common-static-20.13.1.5591.tgz\\nsudo clickhouse-common-static-20.13.1.5591/install/doinst.sh\\n\\ntar -xzvf clickhouse-common-static-dbg-20.13.1.5591.tgz\\nsudo clickhouse-common-static-dbg-20.13.1.5591/install/doinst.sh\\n\\ntar -xzvf clickhouse-client-20.13.1.5591.tgz\\nsudo clickhouse-client-20.13.1.5591/install/doinst.sh\\n\\ntar -xzvf clickhouse-server-20.13.1.5591.tgz\\nsudo clickhouse-server-20.13.1.5591/install/doinst.sh\\n```\n\n\n\n安装成功后,后看到如下提示:\n\n\n\n```\\n…\\n\\nClickHouse has been successfully installed.\\n\\nStart clickhouse-server with:\\n sudo clickhouse start\\n\\nStart clickhouse-client with:\\n clickhouse-client\\n```\n\n\n\n根据提示使用以下命令启动 clickhouse-server 服务:\n\n\n\n```\\nsudo clickhouse start\\n```\n\n\n\n执行命令 clickhouse-client 启动客户端,可以看到连接到服务器并\n\n\n\n```\\n\$ clickhouse-client \\n\\nClickHouse client version 20.13.1.5591 (official build).\\nConnecting to localhost:9000 as user default.\\nConnected to ClickHouse server version 20.13.1 revision 54443.\\n```\n\n\n\n5)配置 ClickHouse 实现通过 MergeTree 表引擎集成 S3\n\n\n\n创建并编辑 ClickHouse 配置文件,ClickHouse 的主配置文件通常在/etc/clickhouse-server/config.xml,其他附加配置我们可以通过在/etc/clickhouse-server/config.d/添加 xml 文件来设置,也方便配置的扩展。\n\n\n\n```\\nsudo vim /etc/clickhouse-server/config.d/merge-s3.xml\\n```\n\n\n\n复制一下内容到文件中,其中 use_environment_credentials 表示通过 IAM 的角色、环境变量或者.Amazon Web Services 中的安全配置来访问 S3。注意替换 endpoint 部分对应的 S3 存储桶和路径:\n\n\n\n```\\n<yandex>\\n <storage_configuration>\\n <disks>\\n <s3>\\n <type>s3</type>\\n <endpoint>https://s3.cn-north-1.amazonaws.com.cn/clickhouse-shtian/mergetree/</endpoint>\\n <use_environment_credentials>true</use_environment_credentials>\\n </s3>\\n </disks>\\n <policies>\\n <s3>\\n <volumes>\\n <main>\\n <disk>s3</disk>\\n </main>\\n </volumes>\\n </s3>\\n </policies>\\n </storage_configuration>\\n</yandex>\\n```\n\n\n\n编辑 /etc/clickhouse-server/config.xml.修改 openSSL 中的client配置,添加一行<caConfig>/etc/pki/tls/certs/ca-bundle.crt</caConfig>,设定SSL/TLS访问的CA证书。如果想使用S3的http端点,则无需配置此选项,但是会存在数据传输安全风险,因此建议使用上面的https的端点并进行如下配置。\n\n\n\n```\\n<client> <!-- Used for connecting to https dictionary source and secured Zookeeper communication -->\\n <loadDefaultCAFile>true</loadDefaultCAFile>\\n <caConfig>/etc/pki/tls/certs/ca-bundle.crt</caConfig>\\n <cacheSessions>true</cacheSessions>\\n <disableProtocols>sslv2,sslv3</disableProtocols>\\n <preferServerCiphers>true</preferServerCiphers>\\n <!-- Use for self-signed: <verificationMode>none</verificationMode> -->\\n <invalidCertificateHandler>\\n <!-- Use for self-signed: <name>AcceptCertificateHandler</name> -->\\n <name>RejectCertificateHandler</name>\\n </invalidCertificateHandler>\\n </client>\\n </openSSL>\\n```\n\n\n\n此外,根据操作系统不同,caConfig 选项可能不需要单独添加。实际测试在使用 Ubuntu 18.04 的时候,ClickHouse 会自动找到 CA 证书的位置,无需额外配置。但是,在使用 Amazon Linux 2 操作系统时需要配置上述选项,否则 ClickHouse 找不到 CA 证书的位置,并且会报如下证书错误:\n\n\n\n```\\nError message: Poco::Exception. Code: 1000, e.code() = 0, e.displayText() = SSL Exception: error:1000007d:SSL routines:OPENSSL_internal:CERTIFICATE_VERIFY_FAILED (version 20.13.1.5591 (official build))\\n```\n\n\n\n重启 clickhouse-server 使配置文件生效:\n\n\n\n```\\nsudo clickhouse restart\\n```\n\n\n\n启动客户端 clickhouse-client,创建 MergeTree 引擎的数据表,并选择定义好的 S3 存储策略:\n\n\n\n```\\nCREATE TABLE default.s3mergetree\\n(\\n `VendorID` UInt8,\\n `VendorName` String\\n)\\nENGINE = MergeTree\\nPARTITION BY VendorName\\nORDER BY VendorID\\nSETTINGS storage_policy = 's3'\\n```\n\n\n\n插入2行测试数据:\n\n\n\n```\\nINSERT INTO default.s3mergetree VALUES (1, 'Vendor1') (2, 'Vendor2')\\n```\n\n\n\n然后查询这个数据表:\n\n\n\n```\\nSELECT *\\nFROM default.s3mergetree\\n```\n\n\n\n返回结果如下,查询成功:\n\n\n\n\n\n但是实际上数据文件中并没有保存真实的数据,而是存储了 S3 数据的链接。\n\n\n\n查看 S3 中的数据信息,数据文件是长这个样子的:\n\n\n\n\n\n尽管原来在块存储中需要硬链接的合并、变异和重命名操作现在是在引用上操作的,S3 数据完全没有被触及,但是通过查看上述文件结构发现这会导致另一个问题,就是针对这些数据并没有办法通过其他数据分析工具进行处理,因为 ClickHouse 本身也是采用的专有数据存储格式,这也是该方案的一个弊端,借助了 MergeTree 的好处但仅仅是使用 S3 做为存储。\n\n\n\n6)配置 ClickHouse 实现通过专用表引擎集成 S3\n\n\n\n创建并编辑 ClickHouse 配置文件:\n\n\n\n```\\nsudo vim /etc/clickhouse-server/config.d/table-s3.xml\\n```\n\n\n\n复制一下内容到文件中:\n\n\n\n```\\n<yandex>\\n <s3>\\n <endpoint>\\n <endpoint>https://s3.cn-north-1.amazonaws.com.cn</endpoint>\\n <use_environment_credentials>true</use_environment_credentials>\\n </endpoint>\\n </s3>\\n</yandex>\\n```\n\n\n\n重启 clickhouse-server 使配置文件生效:\n\n\n\n```\\nsudo clickhouse restart\\n```\n\n\n\n启动客户端 clickhouse-client,创建 S3 引擎的数据表:\n\n\n\n```\\nCREATE TABLE default.s3table\\n(\\n `VendorID` UInt8,\\n `tpep_pickup_datetime` DateTime,\\n `tpep_dropoff_datetime` DateTime,\\n `passenger_count` UInt8,\\n `trip_distance` Float32,\\n `RatecodeID` UInt8,\\n `store_and_fwd_flag` String,\\n `PULocationID` UInt8,\\n `DOLocationID` UInt8,\\n `payment_type` UInt8,\\n `fare_amount` Float32,\\n `extra` Float32,\\n `mta_tax` Float32,\\n `tip_amount` Float32,\\n `tolls_amount` Float32,\\n `improvement_surcharge` Float32,\\n `total_amount` Float32,\\n `congestion_surcharge` Float32\\n)\\nENGINE = S3('https://s3.cn-north-1.amazonaws.com.cn/clickhouse-shtian/yellow_tripdata_2020-06.csv', CSVWithNames)\\n```\n\n\n\n然后进行基本的查询:\n\n\n\n```\\nSELECT\\n VendorID,\\n tpep_pickup_datetime,\\n tpep_pickup_datetime,\\n passenger_count,\\n tolls_amount,\\n total_amount,\\n congestion_surcharge\\nFROM default.s3table\\nLIMIT 10\\n```\n\n\n\n返回结果如下,查询成功:\n\n\n\n需要注意的是,插入数据在这种情况下也是支持的,但是如果表是使用单文件定义的(如本示例),那么插入会覆盖当前文件的内容。如果是使用通配符的方式进行定义(如*.CSV),在插入数据的时候会写到*.CSV,目前已经将问题反馈提交到 ClickHouse 开源社区。因此,建议目前使用这种方法时,只去查询 S3 中的数据。\n\n\n\n该方案的优势在于对于已有的数据湖中的数据,比如各种开放数据格式 CSV、Parquet 等,都可以通过 ClickHouse 进行查询,无需作出额外的改动,趋于 LakeHouse 这样的新架构。\n\n\n\n7)配置 ClickHouse 实现通过专用表函数集成 S3\n\n\n\n在步骤6中的配置 etc/clickhouse-server/config.d/table-s3.xml对 S3 专用表函数也是生效的,所以直接在客户端 clickhouse-client 继续进行查询即可:\n\n\n\n```\\nSELECT\\n VendorID,\\n tpep_pickup_datetime,\\n tpep_pickup_datetime,\\n passenger_count,\\n tolls_amount,\\n total_amount,\\n congestion_surcharge\\nFROM s3('https://s3.cn-north-1.amazonaws.com.cn/clickhouse-shtian/yellow_tripdata_2020-06.csv', CSVWithNames, 'VendorID UInt8,tpep_pickup_datetime DateTime,tpep_dropoff_datetime DateTime,passenger_count UInt8,trip_distance Float32,RatecodeID UInt8,store_and_fwd_flag String,PULocationID UInt8,DOLocationID UInt8,payment_type UInt8,fare_amount Float32,extra Float32,mta_tax Float32,tip_amount Float32,tolls_amount Float32,improvement_surcharge Float32,total_amount Float32,congestion_surcharge Float32')\\nLIMIT 10\\n```\n\n\n\n返回结果如下,数据查询成功:\n\n\n\n除了单独使用 S3 表函数,还可以和其他 MergeTree 表进行连接,例如我们可以使用以下 SQL 将 S3 表函数和步骤5中创建的表进行 JOIN 查询。\n\n\n```\\nSELECT\\n VendorName,\\n VendorID,\\n tpep_pickup_datetime,\\n tpep_pickup_datetime,\\n passenger_count,\\n tolls_amount,\\n total_amount,\\n congestion_surcharge\\nFROM s3('https://s3.cn-north-1.amazonaws.com.cn/clickhouse-shtian/yellow_tripdata_2020-06.csv', CSVWithNames, 'VendorID UInt8,tpep_pickup_datetime DateTime,tpep_dropoff_datetime DateTime,passenger_count UInt8,trip_distance Float32,RatecodeID UInt8,store_and_fwd_flag String,PULocationID UInt8,DOLocationID UInt8,payment_type UInt8,fare_amount Float32,extra Float32,mta_tax Float32,tip_amount Float32,tolls_amount Float32,improvement_surcharge Float32,total_amount Float32,congestion_surcharge Float32') AS s3\\nINNER JOIN default.s3mergetree ON s3.VendorID = s3mergetree.VendorID\\nWHERE s3mergetree.VendorID = 1\\nLIMIT 10\\n\\n```\n\n\n返回结果如下,数据查询成功:\n\n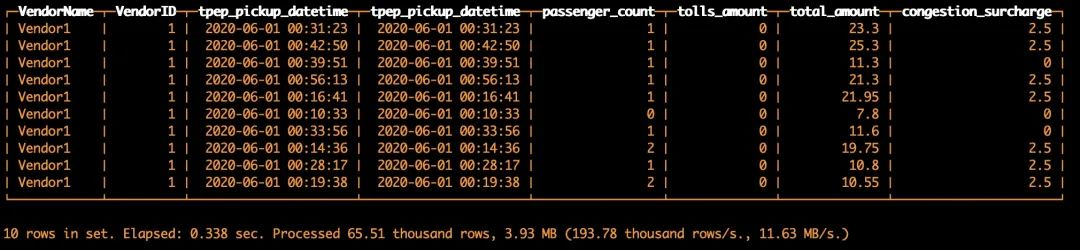\n\n该方案同样发挥了数据湖的价值,可以和已有的各种开放数据格式 CSV、Parquet 等数据进行连接,扩展了数据仓库的使用范围。\n\n\n\n通过上述演示,可以基本实现不同应用场景下的 ClickHouse 和 S3 结合。由于 ClickHouse 是开源项目,所以和 S3 的集成和更丰富的特性还在逐步完善中。\n\n###### 04 小结\n\n本文首先简单介绍了 ClickHouse 及其特性和使用场景,然后介绍了通过与 [Amazon S3](https://aws.amazon.com/cn/s3/?trk=cndc-detail) 存储的结合,可以为数据分析系统带来的优势:成本优化以及数据湖的应用。接下来,我们又介绍了 ClickHouse 和 S3 集成的三种方案,并通过具体示例来展示了各方案的具体实现方法和优劣势。\n\n##### 参考资料:\n\n1. [https://altinity.com/blog/clickhouse-and-s3-compatible-object-storage](https://altinity.com/blog/clickhouse-and-s3-compatible-object-storage)\n2. [https://clickhouse.tech/docs/en/engines/table-engines/mergetree-family/mergetree/#table_engine-mergetree-multiple-volumes](https://clickhouse.tech/docs/en/engines/table-engines/mergetree-family/mergetree/#table_engine-mergetree-multiple-volumes)\n3. [https://clickhouse.tech/docs/en/engines/table-engines/integrations/s3/](https://clickhouse.tech/docs/en/engines/table-engines/integrations/s3/)\n4. [https://clickhouse.tech/docs/en/sql-reference/table-functions/s3/](https://clickhouse.tech/docs/en/sql-reference/table-functions/s3/)\n\n**本篇作者**\n\n\n\n**史天 亚马逊云科技解决方案架构师**\n\n拥有丰富的云计算、大数据和[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)经验,目前致力于数据科学、[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)、[无服务器](https://aws.amazon.com/cn/serverless/?trk=cndc-detail)等领域的研究和实践。译有《[机器学习](https://aws.amazon.com/cn/machine-learning/?trk=cndc-detail)即服务》《基于 Kubernetes 的 DevOps 实践》《Prometheus 监控实战》等。","render":"<div class=\\"hljs-center\\">\\n<h5><a id=\\"_2\\"></a>目录</h5>\\n</div>\n<ol>\\n<li>ClickHouse 简介</li>\n<li>ClickHouse 与对象存储</li>\n<li>ClickHouse 与 S3 结合的三种方法</li>\n<li>示例参考架构</li>\n<li>小结</li>\n<li>参考资料</li>\n</ol>\\n<h5><a id=\\"ClickHouse__13\\"></a>ClickHouse 简介</h5>\\n<p>ClickHouse 是一种快速的、开源的、用于联机分析(OLAP)的列式数据库管理系统(DBMS),由俄罗斯的Yandex公司开发,于2016年开源。ClickHouse 作为交互式分析领域的后起之秀,发展速度非常快,目前在 GitHub 上已收获 14K Star。</p>\n<p><img src=\\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/04a4c20986a749d5ac83fb47fe9363ad_image.png\\" alt=\\"image.png\\" /></p>\n<p>ClickHouse 主打顶尖的极致性能,每台服务器每秒钟可以处理数亿至数十亿多行或者是数十GB的数据。ClickHouse 基于列式存储,通过 SQL 查询海量数据并实时生成分析报告。ClickHouse 充分利用了所有可用的硬件优化技术,以尽可能快地处理每个查询。向量化的查询执行引入了 SIMD 处理器指令和运行时代码生成技术。列式存储的数据会提高CPU缓存的命中率。ClickHouse 概览文档中的图片清晰地展示了行式存储与列式存储在 OLAP 领域中的速度差距。</p>\n<p><img src=\\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/93e002004c4e4d95b913a0b20d927aa7_image.png\\" alt=\\"image.png\\" /></p>\n<div class=\\"hljs-center\\">\\n<p><em>行式存储</em></p>\\n</div>\n<p><img src=\\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/0b026cb708874629aa2f6857784475f4_image.png\\" alt=\\"image.png\\" /></p>\n<div class=\\"hljs-center\\">\\n<p><em>列式存储</em></p>\\n</div>\n<p>在分布式集群中,副本之间的数据读取会自动保持平衡,以避免增加延迟。同时,ClickHouse 支持多主异步复制模式,这种情况下所有节点角色都是相等的,可以避免出现单点故障,单个节点或整个可用区的停机时间并不会影响系统的读写可用性。</p>\n<p>在网络和应用分析,广告网络和实时出价,电信,电子商务和金融以及商业智能等领域,ClickHouse 都有很好的支持与应用,更多信息请参考 ClickHouse 官网。</p>\n<h6><a id=\\"01_ClickHouse_39\\"></a><strong>01 ClickHouse与对象存储</strong></h6>\\n<p>ClickHouse 针对数据量和查询场景提供了不同的数据库和数据表引擎,此外它也可以使用多种多样的专用引擎或表函数(例如 HDFS,Kafka,S3 等)与许多外部系统进行通讯。在现代化的云架构中,对象存储是最重要的存储组成部分。2006年,亚马逊云科技正式推出的第一个云服务也是 Amazon S3(Simple Storage Service),目前 Amazon S3 已经成为事实上的云对象存储标准。</p>\n<p>使用对象存储可以给数据分析系统带来诸多优势。首先,它可以使用数据湖架构中的原始数据。其次,对象存储可以为数据表数据提供高性价比且高可靠性的存储。针对 S3 目前 ClickHouse 已经上述对象存储的这两种用途。</p>\n<h6><a id=\\"02_ClickHouse__S3__47\\"></a><strong>02 ClickHouse 与 S3 结合的三种方法</strong></h6>\\n<p>1)通过 MergeTree 表引擎集成 S3</p>\n<p>前面提到 ClickHouse 提供了众多数据库和数据表引擎,这其中最强大的表引擎当属 MergeTree (合并树)引擎及合并树系列(*MergeTree)中的其他引擎。MergeTree 系列的引擎被设计用于插入海量的数据到一张表当中。数据可以以数据片段的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合并。相比在插入时不断修改(重写)已存储的数据,这种策略会高效很多。</p>\n<p>MergeTree 系列表引擎可以将数据存储在多块设备上。这对某些可以潜在被划分为“冷”“热”的表来说是很有用的。近期数据被定期的查询但只需要比较小的磁盘存储空间。相反,大量的、详尽的历史数据被用到的频率相对较少。ClickHouse 可以将 S3 对象存储用于 MergeTree 表数据,这样针对“热”的数据,可以放置在快速的磁盘上(比如 NVMe 固态硬盘或内存中),“冷”的数据可以存放在S3对象存储中。在MergeTree 系列表引擎中使用S3的参考架构如下图所示:</p>\n<p><img src=\\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/4a6393b3c0cf4d3e9f780f35ac1c2ff3_image.png\\" alt=\\"image.png\\" /></p>\n<p>2)通过 S3 表引擎集成</p>\n<p>除了 MergeTree 表引擎,ClickHouse 还直接提供了专用的 S3 表引擎,进一步加强了 Amazon S3 生态系统的集成,可以充分利用数据湖中已有的各种开放数据格式例如Parquet。通过以下语句就可以进行 S3 表引擎的创建:</p>\n<pre><code class=\\"lang-\\">ENGINE = S3(path, [aws_access_key_id, aws_secret_access_key,] format, structure, [compression])\\n</code></pre>\\n<p>3)通过 S3 表函数集成</p>\n<p>ClickHouse 提供表接口的方式对 S3 中的文件进行 SELECT/INSERT 操作,这种方式使用起来更加方便,可以快速与 ClickHouse 中已有的数据进行连接等操作。通过以下语句就可以使用S3表函数:</p>\n<pre><code class=\\"lang-\\">s3(path, [aws_access_key_id, aws_secret_access_key,] format, structure, [compression])\\n</code></pre>\\n<p>上述方式分别适用于不同的应用场景,可以根据具体情况进行单独或者结合使用。</p>\n<p>此外,可以看到这里面还涉及到 S3 访问权限的安全问题。在 ClickHouse 20.13之前的版本中,必须要在 SQL 或 ClickHouse 存储配置中提供 Amazon Web Services 的访问密钥(Access Key 和 Secret Access Key)才能访问,这是既不安全也不方便的模式。但是在20.13版本中,ClickHouse 提供了实用 IAM Role 访问方式,解决了访问 S3 的安全性问题。</p>\n<h5><a id=\\"03__95\\"></a><strong>03 示例参考架构</strong></h5>\\n<p>接下来,我们将演示如何实现上述介绍的 ClickHouse 与 S3 结合的三种方法。演示的参考架构如下图所示,我们将 ClickHouse 环境部署在一个 VPC 私有子网中,然后通过 VPC Enpoints 内网的方式来访问 S3 中的数据。</p>\n<p><img src=\\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/0d4f599e3fa3492eb776e89aaaee2868_image.png\\" alt=\\"image.png\\" /></p>\n<p>在示例中,我们将使用纽约出租车数据,该数据分析是 Kaggle 竞赛的著名赛题之一,也是学习数据分析的经典练习案例,项目数据可以从 NYC 网站上进行下载,这里选取了2020年6月的 Yellow Taxi Trip Records 数据。</p>\n<p>以下示例的操作环境为亚马逊云科技中国(北京)区域。</p>\n<p>1)创建 S3 存储桶</p>\n<p>首先,在亚马逊云科技中国(北京)区域创建存储数据的S3存储桶,例如 clickhouse-shtian。</p>\n<p><img src=\\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/d003de27f72846598cea3b34c69e3057_image.png\\" alt=\\"image.png\\" /></p>\n<p>2)下载数据并上传到 S3 存储桶中</p>\n<p>首先,在 NYC 网站上将2020年6月 Yellow Taxi Trip Records 数据下载下来,然后上传到刚刚创建的 S3 桶中。</p>\n<p><img src=\\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/3c55f842d8d14b16a0392c98b742e45f_image.png\\" alt=\\"image.png\\" /></p>\n<p>3)创建并配置 S3 的 VPC Enpoint</p>\n<p>VPC Enpoint 的创建和配置请参考 VPC 文档,确保子网路由表中包含下图中第二条路有条目。</p>\n<p><img src=\\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/351e80bf881b4dae86a08e6d68b540f3_image.png\\" alt=\\"image.png\\" /></p>\n<p>4)部署 ClickHouse</p>\n<p>示例操作系统为 Amazon Linux 2,ClickHouse 版本为20.13.1.5591,演示使用单点部署模式,实际使用环境建议部署集群模式,提升高可用的同时也增加性能。需要注意的是在创建 EC2 实例过程中需要配置 IAM 角色,可以参考文档适用于 Amazon EC2 的 IAM 角色进行设置,并确保这个角色具有 S3 桶的读写权限。</p>\n<p><img src=\\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/d9cbf8a178ca496790f3045863679c96_image.png\\" alt=\\"image.png\\" /></p>\n<p>SSH 登录到 EC2 实例上,然后下载对应版本的安装包,然后解压并安装。</p>\n<pre><code class=\\"lang-\\">wget https://github.com/ClickHouse/ClickHouse/releases/download/v20.13.1.5591-testing/clickhouse-client-20.13.1.5591.tgz\\n\\nwget https://github.com/ClickHouse/ClickHouse/releases/download/v20.13.1.5591-testing/clickhouse-common-static-20.13.1.5591.tgz\\n\\nwget https://github.com/ClickHouse/ClickHouse/releases/download/v20.13.1.5591-testing/clickhouse-common-static-dbg-20.13.1.5591.tgz\\n\\nwget https://github.com/ClickHouse/ClickHouse/releases/download/v20.13.1.5591-testing/clickhouse-server-20.13.1.5591.tgz\\n\\ntar -xzvf clickhouse-common-static-20.13.1.5591.tgz\\nsudo clickhouse-common-static-20.13.1.5591/install/doinst.sh\\n\\ntar -xzvf clickhouse-common-static-dbg-20.13.1.5591.tgz\\nsudo clickhouse-common-static-dbg-20.13.1.5591/install/doinst.sh\\n\\ntar -xzvf clickhouse-client-20.13.1.5591.tgz\\nsudo clickhouse-client-20.13.1.5591/install/doinst.sh\\n\\ntar -xzvf clickhouse-server-20.13.1.5591.tgz\\nsudo clickhouse-server-20.13.1.5591/install/doinst.sh\\n</code></pre>\\n<p>安装成功后,后看到如下提示:</p>\n<pre><code class=\\"lang-\\">…\\n\\nClickHouse has been successfully installed.\\n\\nStart clickhouse-server with:\\n sudo clickhouse start\\n\\nStart clickhouse-client with:\\n clickhouse-client\\n</code></pre>\\n<p>根据提示使用以下命令启动 clickhouse-server 服务:</p>\n<pre><code class=\\"lang-\\">sudo clickhouse start\\n</code></pre>\\n<p>执行命令 clickhouse-client 启动客户端,可以看到连接到服务器并</p>\n<pre><code class=\\"lang-\\">\$ clickhouse-client \\n\\nClickHouse client version 20.13.1.5591 (official build).\\nConnecting to localhost:9000 as user default.\\nConnected to ClickHouse server version 20.13.1 revision 54443.\\n</code></pre>\\n<p>5)配置 ClickHouse 实现通过 MergeTree 表引擎集成 S3</p>\n<p>创建并编辑 ClickHouse 配置文件,ClickHouse 的主配置文件通常在/etc/clickhouse-server/config.xml,其他附加配置我们可以通过在/etc/clickhouse-server/config.d/添加 xml 文件来设置,也方便配置的扩展。</p>\n<pre><code class=\\"lang-\\">sudo vim /etc/clickhouse-server/config.d/merge-s3.xml\\n</code></pre>\\n<p>复制一下内容到文件中,其中 use_environment_credentials 表示通过 IAM 的角色、环境变量或者.Amazon Web Services 中的安全配置来访问 S3。注意替换 endpoint 部分对应的 S3 存储桶和路径:</p>\n<pre><code class=\\"lang-\\"><yandex>\\n <storage_configuration>\\n <disks>\\n <s3>\\n <type>s3</type>\\n <endpoint>https://s3.cn-north-1.amazonaws.com.cn/clickhouse-shtian/mergetree/</endpoint>\\n <use_environment_credentials>true</use_environment_credentials>\\n </s3>\\n </disks>\\n <policies>\\n <s3>\\n <volumes>\\n <main>\\n <disk>s3</disk>\\n </main>\\n </volumes>\\n </s3>\\n </policies>\\n </storage_configuration>\\n</yandex>\\n</code></pre>\\n<p>编辑 /etc/clickhouse-server/config.xml.修改 openSSL 中的client配置,添加一行<caConfig>/etc/pki/tls/certs/ca-bundle.crt</caConfig>,设定SSL/TLS访问的CA证书。如果想使用S3的http端点,则无需配置此选项,但是会存在数据传输安全风险,因此建议使用上面的https的端点并进行如下配置。</p>\n<pre><code class=\\"lang-\\"><client> <!-- Used for connecting to https dictionary source and secured Zookeeper communication -->\\n <loadDefaultCAFile>true</loadDefaultCAFile>\\n <caConfig>/etc/pki/tls/certs/ca-bundle.crt</caConfig>\\n <cacheSessions>true</cacheSessions>\\n <disableProtocols>sslv2,sslv3</disableProtocols>\\n <preferServerCiphers>true</preferServerCiphers>\\n <!-- Use for self-signed: <verificationMode>none</verificationMode> -->\\n <invalidCertificateHandler>\\n <!-- Use for self-signed: <name>AcceptCertificateHandler</name> -->\\n <name>RejectCertificateHandler</name>\\n </invalidCertificateHandler>\\n </client>\\n </openSSL>\\n</code></pre>\\n<p>此外,根据操作系统不同,caConfig 选项可能不需要单独添加。实际测试在使用 Ubuntu 18.04 的时候,ClickHouse 会自动找到 CA 证书的位置,无需额外配置。但是,在使用 Amazon Linux 2 操作系统时需要配置上述选项,否则 ClickHouse 找不到 CA 证书的位置,并且会报如下证书错误:</p>\n<pre><code class=\\"lang-\\">Error message: Poco::Exception. Code: 1000, e.code() = 0, e.displayText() = SSL Exception: error:1000007d:SSL routines:OPENSSL_internal:CERTIFICATE_VERIFY_FAILED (version 20.13.1.5591 (official build))\\n</code></pre>\\n<p>重启 clickhouse-server 使配置文件生效:</p>\n<pre><code class=\\"lang-\\">sudo clickhouse restart\\n</code></pre>\\n<p>启动客户端 clickhouse-client,创建 MergeTree 引擎的数据表,并选择定义好的 S3 存储策略:</p>\n<pre><code class=\\"lang-\\">CREATE TABLE default.s3mergetree\\n(\\n `VendorID` UInt8,\\n `VendorName` String\\n)\\nENGINE = MergeTree\\nPARTITION BY VendorName\\nORDER BY VendorID\\nSETTINGS storage_policy = 's3'\\n</code></pre>\\n<p>插入2行测试数据:</p>\n<pre><code class=\\"lang-\\">INSERT INTO default.s3mergetree VALUES (1, 'Vendor1') (2, 'Vendor2')\\n</code></pre>\\n<p>然后查询这个数据表:</p>\n<pre><code class=\\"lang-\\">SELECT *\\nFROM default.s3mergetree\\n</code></pre>\\n<p>返回结果如下,查询成功:</p>\n<p><img src=\\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/69a98aac37834944a52e390297d6d05f_image.png\\" alt=\\"image.png\\" /></p>\n<p><img src=\\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/e825cbfc4d5e4fe584bf233761a47c5c_image.png\\" alt=\\"image.png\\" /></p>\n<p>但是实际上数据文件中并没有保存真实的数据,而是存储了 S3 数据的链接。</p>\n<p><img src=\\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/4e5eca1ea80246df8f0fa9529315e3e8_image.png\\" alt=\\"image.png\\" /></p>\n<p>查看 S3 中的数据信息,数据文件是长这个样子的:</p>\n<p><img src=\\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/8a20d51e3fca4991b3d7f702d4f8b9c6_image.png\\" alt=\\"image.png\\" /></p>\n<p>尽管原来在块存储中需要硬链接的合并、变异和重命名操作现在是在引用上操作的,S3 数据完全没有被触及,但是通过查看上述文件结构发现这会导致另一个问题,就是针对这些数据并没有办法通过其他数据分析工具进行处理,因为 ClickHouse 本身也是采用的专有数据存储格式,这也是该方案的一个弊端,借助了 MergeTree 的好处但仅仅是使用 S3 做为存储。</p>\n<p>6)配置 ClickHouse 实现通过专用表引擎集成 S3</p>\n<p>创建并编辑 ClickHouse 配置文件:</p>\n<pre><code class=\\"lang-\\">sudo vim /etc/clickhouse-server/config.d/table-s3.xml\\n</code></pre>\\n<p>复制一下内容到文件中:</p>\n<pre><code class=\\"lang-\\"><yandex>\\n <s3>\\n <endpoint>\\n <endpoint>https://s3.cn-north-1.amazonaws.com.cn</endpoint>\\n <use_environment_credentials>true</use_environment_credentials>\\n </endpoint>\\n </s3>\\n</yandex>\\n</code></pre>\\n<p>重启 clickhouse-server 使配置文件生效:</p>\n<pre><code class=\\"lang-\\">sudo clickhouse restart\\n</code></pre>\\n<p>启动客户端 clickhouse-client,创建 S3 引擎的数据表:</p>\n<pre><code class=\\"lang-\\">CREATE TABLE default.s3table\\n(\\n `VendorID` UInt8,\\n `tpep_pickup_datetime` DateTime,\\n `tpep_dropoff_datetime` DateTime,\\n `passenger_count` UInt8,\\n `trip_distance` Float32,\\n `RatecodeID` UInt8,\\n `store_and_fwd_flag` String,\\n `PULocationID` UInt8,\\n `DOLocationID` UInt8,\\n `payment_type` UInt8,\\n `fare_amount` Float32,\\n `extra` Float32,\\n `mta_tax` Float32,\\n `tip_amount` Float32,\\n `tolls_amount` Float32,\\n `improvement_surcharge` Float32,\\n `total_amount` Float32,\\n `congestion_surcharge` Float32\\n)\\nENGINE = S3('https://s3.cn-north-1.amazonaws.com.cn/clickhouse-shtian/yellow_tripdata_2020-06.csv', CSVWithNames)\\n</code></pre>\\n<p>然后进行基本的查询:</p>\n<pre><code class=\\"lang-\\">SELECT\\n VendorID,\\n tpep_pickup_datetime,\\n tpep_pickup_datetime,\\n passenger_count,\\n tolls_amount,\\n total_amount,\\n congestion_surcharge\\nFROM default.s3table\\nLIMIT 10\\n</code></pre>\\n<p>返回结果如下,查询成功:</p>\n<p><img src=\\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/968ece95bd5941e1b106b991c37c75a8_image.png\\" alt=\\"image.png\\" /></p>\n<p>需要注意的是,插入数据在这种情况下也是支持的,但是如果表是使用单文件定义的(如本示例),那么插入会覆盖当前文件的内容。如果是使用通配符的方式进行定义(如*.CSV),在插入数据的时候会写到*.CSV,目前已经将问题反馈提交到 ClickHouse 开源社区。因此,建议目前使用这种方法时,只去查询 S3 中的数据。</p>\n<p>该方案的优势在于对于已有的数据湖中的数据,比如各种开放数据格式 CSV、Parquet 等,都可以通过 ClickHouse 进行查询,无需作出额外的改动,趋于 LakeHouse 这样的新架构。</p>\n<p>7)配置 ClickHouse 实现通过专用表函数集成 S3</p>\n<p>在步骤6中的配置 etc/clickhouse-server/config.d/table-s3.xml对 S3 专用表函数也是生效的,所以直接在客户端 clickhouse-client 继续进行查询即可:</p>\n<pre><code class=\\"lang-\\">SELECT\\n VendorID,\\n tpep_pickup_datetime,\\n tpep_pickup_datetime,\\n passenger_count,\\n tolls_amount,\\n total_amount,\\n congestion_surcharge\\nFROM s3('https://s3.cn-north-1.amazonaws.com.cn/clickhouse-shtian/yellow_tripdata_2020-06.csv', CSVWithNames, 'VendorID UInt8,tpep_pickup_datetime DateTime,tpep_dropoff_datetime DateTime,passenger_count UInt8,trip_distance Float32,RatecodeID UInt8,store_and_fwd_flag String,PULocationID UInt8,DOLocationID UInt8,payment_type UInt8,fare_amount Float32,extra Float32,mta_tax Float32,tip_amount Float32,tolls_amount Float32,improvement_surcharge Float32,total_amount Float32,congestion_surcharge Float32')\\nLIMIT 10\\n</code></pre>\\n<p>返回结果如下,数据查询成功:</p>\n<p><img src=\\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/c69bf24d1d32440aba6d83b457292fe8_image.png\\" alt=\\"image.png\\" /></p>\n<p>除了单独使用 S3 表函数,还可以和其他 MergeTree 表进行连接,例如我们可以使用以下 SQL 将 S3 表函数和步骤5中创建的表进行 JOIN 查询。</p>\n<pre><code class=\\"lang-\\">SELECT\\n VendorName,\\n VendorID,\\n tpep_pickup_datetime,\\n tpep_pickup_datetime,\\n passenger_count,\\n tolls_amount,\\n total_amount,\\n congestion_surcharge\\nFROM s3('https://s3.cn-north-1.amazonaws.com.cn/clickhouse-shtian/yellow_tripdata_2020-06.csv', CSVWithNames, 'VendorID UInt8,tpep_pickup_datetime DateTime,tpep_dropoff_datetime DateTime,passenger_count UInt8,trip_distance Float32,RatecodeID UInt8,store_and_fwd_flag String,PULocationID UInt8,DOLocationID UInt8,payment_type UInt8,fare_amount Float32,extra Float32,mta_tax Float32,tip_amount Float32,tolls_amount Float32,improvement_surcharge Float32,total_amount Float32,congestion_surcharge Float32') AS s3\\nINNER JOIN default.s3mergetree ON s3.VendorID = s3mergetree.VendorID\\nWHERE s3mergetree.VendorID = 1\\nLIMIT 10\\n\\n</code></pre>\\n<p>返回结果如下,数据查询成功:</p>\n<p><img src=\\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/e5e43e8c5c4544deb5ae204d9ded9eef_image.png\\" alt=\\"image.png\\" /></p>\n<p>该方案同样发挥了数据湖的价值,可以和已有的各种开放数据格式 CSV、Parquet 等数据进行连接,扩展了数据仓库的使用范围。</p>\n<p>通过上述演示,可以基本实现不同应用场景下的 ClickHouse 和 S3 结合。由于 ClickHouse 是开源项目,所以和 S3 的集成和更丰富的特性还在逐步完善中。</p>\n<h6><a id=\\"04__516\\"></a>04 小结</h6>\\n<p>本文首先简单介绍了 ClickHouse 及其特性和使用场景,然后介绍了通过与 Amazon S3 存储的结合,可以为数据分析系统带来的优势:成本优化以及数据湖的应用。接下来,我们又介绍了 ClickHouse 和 S3 集成的三种方案,并通过具体示例来展示了各方案的具体实现方法和优劣势。</p>\n<h5><a id=\\"_520\\"></a>参考资料:</h5>\\n<ol>\\n<li><a href=\\"https://altinity.com/blog/clickhouse-and-s3-compatible-object-storage\\" target=\\"_blank\\">https://altinity.com/blog/clickhouse-and-s3-compatible-object-storage</a></li>\\n<li><a href=\\"https://clickhouse.tech/docs/en/engines/table-engines/mergetree-family/mergetree/#table_engine-mergetree-multiple-volumes\\" target=\\"_blank\\">https://clickhouse.tech/docs/en/engines/table-engines/mergetree-family/mergetree/#table_engine-mergetree-multiple-volumes</a></li>\\n<li><a href=\\"https://clickhouse.tech/docs/en/engines/table-engines/integrations/s3/\\" target=\\"_blank\\">https://clickhouse.tech/docs/en/engines/table-engines/integrations/s3/</a></li>\\n<li><a href=\\"https://clickhouse.tech/docs/en/sql-reference/table-functions/s3/\\" target=\\"_blank\\">https://clickhouse.tech/docs/en/sql-reference/table-functions/s3/</a></li>\\n</ol>\n<p><strong>本篇作者</strong></p>\\n<p><img src=\\"https://awsdevweb.s3.cn-north-1.amazonaws.com.cn/e08bea739bbb4607b1eba6235a728fb7_image.png\\" alt=\\"image.png\\" /></p>\n<p><strong>史天 亚马逊云科技解决方案架构师</strong></p>\\n<p>拥有丰富的云计算、大数据和机器学习经验,目前致力于数据科学、机器学习、无服务器等领域的研究和实践。译有《机器学习即服务》《基于 Kubernetes 的 DevOps 实践》《Prometheus 监控实战》等。</p>\n"}
ClickHouse 与 Amazon S3 结合?一起来探索其中奥秘
GitHub

 0
0 3
3

亚马逊云科技解决方案 基于行业客户应用场景及技术领域的解决方案
联系亚马逊云科技专家
亚马逊云科技解决方案
基于行业客户应用场景及技术领域的解决方案
联系专家

3
目录

 分享
分享 点赞
点赞 收藏
收藏 目录
目录立即注册,开启您的免费套餐
立即关注

亚马逊云开发者
公众号

User Group
公众号

亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
关于我们 
更多资源
开发者工具
更多支持
立即关注
亚马逊云开发者
公众号
User Group
公众号
亚马逊云科技
官方小程序
“AWS” 是 “Amazon Web Services” 的缩写,在此网站不作为商标展示。
